 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Efficiency Incremental Learning Framework via Vision-Language Model with Nonlinear Multi-Adapters
Mar 11, 2026Incremental Learning (IL) aims to learn new tasks while preserving previously acquired knowledge. Integrating the zero-shot learning capabilities of pre-trained vision-language models into IL methods has marked a significant advancement. However, these methods face three primary challenges: (1) the need for improved training efficiency; (2) reliance on a memory bank to store previous data; and (3) the necessity of a strong backbone to augment the model's capabilities. In this paper, we propose SimE, a Simple and Efficient framework that employs a vision-language model with adapters designed specifically for the IL task. We report a remarkable phenomenon: there is a nonlinear correlation between the number of adaptive adapter connections and the model's IL capabilities. While increasing adapter connections between transformer blocks improves model performance, adding more adaptive connections within transformer blocks during smaller incremental steps does not enhance, and may even degrade the model's IL ability. Extensive experimental results show that SimE surpasses traditional methods by 9.6% on TinyImageNet and outperforms other CLIP-based methods by 5.3% on CIFAR-100. Furthermore, we conduct a systematic study to enhance the utilization of the zero-shot capabilities of CLIP. We suggest replacing SimE's encoder with a CLIP model trained on larger datasets (e.g., LAION2B) and stronger architectures (e.g., ViT-L/14).
Reversible Lifelong Model Editing via Semantic Routing-Based LoRA
Mar 11, 2026The dynamic evolution of real-world necessitates model editing within Large Language Models. While existing methods explore modular isolation or parameter-efficient strategies, they still suffer from semantic drift or knowledge forgetting due to continual updating. To address these challenges, we propose SoLA, a Semantic routing-based LoRA framework for lifelong model editing. In SoLA, each edit is encapsulated as an independent LoRA module, which is frozen after training and mapped to input by semantic routing, allowing dynamic activation of LoRA modules via semantic matching. This mechanism avoids semantic drift caused by cluster updating and mitigates catastrophic forgetting from parameter sharing. More importantly, SoLA supports precise revocation of specific edits by removing key from semantic routing, which restores model's original behavior. To our knowledge, this reversible rollback editing capability is the first to be achieved in existing literature. Furthermore, SoLA integrates decision-making process into edited layer, eliminating the need for auxiliary routing networks and enabling end-to-end decision-making process. Extensive experiments demonstrate that SoLA effectively learns and retains edited knowledge, achieving accurate, efficient, and reversible lifelong model editing.
Key-Value Pair-Free Continual Learner via Task-Specific Prompt-Prototype
Jan 08, 2026Continual learning aims to enable models to acquire new knowledge while retaining previously learned information. Prompt-based methods have shown remarkable performance in this domain; however, they typically rely on key-value pairing, which can introduce inter-task interference and hinder scalability. To overcome these limitations, we propose a novel approach employing task-specific Prompt-Prototype (ProP), thereby eliminating the need for key-value pairs. In our method, task-specific prompts facilitate more effective feature learning for the current task, while corresponding prototypes capture the representative features of the input. During inference, predictions are generated by binding each task-specific prompt with its associated prototype. Additionally, we introduce regularization constraints during prompt initialization to penalize excessively large values, thereby enhancing stability. Experiments on several widely used datasets demonstrate the effectiveness of the proposed method. In contrast to mainstream prompt-based approaches, our framework removes the dependency on key-value pairs, offering a fresh perspective for future continual learning research.
Spiking Neural Networks with Temporal Attention-Guided Adaptive Fusion for imbalanced Multi-modal Learning
May 20, 2025Multimodal spiking neural networks (SNNs) hold significant potential for energy-efficient sensory processing but face critical challenges in modality imbalance and temporal misalignment. Current approaches suffer from uncoordinated convergence speeds across modalities and static fusion mechanisms that ignore time-varying cross-modal interactions. We propose the temporal attention-guided adaptive fusion framework for multimodal SNNs with two synergistic innovations: 1) The Temporal Attention-guided Adaptive Fusion (TAAF) module that dynamically assigns importance scores to fused spiking features at each timestep, enabling hierarchical integration of temporally heterogeneous spike-based features; 2) The temporal adaptive balanced fusion loss that modulates learning rates per modality based on the above attention scores, preventing dominant modalities from monopolizing optimization. The proposed framework implements adaptive fusion, especially in the temporal dimension, and alleviates the modality imbalance during multimodal learning, mimicking cortical multisensory integration principles. Evaluations on CREMA-D, AVE, and EAD datasets demonstrate state-of-the-art performance (77.55\%, 70.65\% and 97.5\%accuracy, respectively) with energy efficiency. The system resolves temporal misalignment through learnable time-warping operations and faster modality convergence coordination than baseline SNNs. This work establishes a new paradigm for temporally coherent multimodal learning in neuromorphic systems, bridging the gap between biological sensory processing and efficient machine intelligence.
Self-cross Feature based Spiking Neural Networks for Efficient Few-shot Learning
May 15, 2025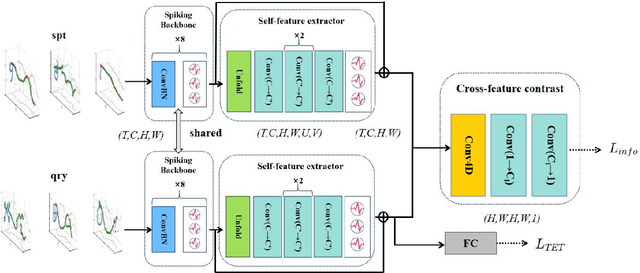
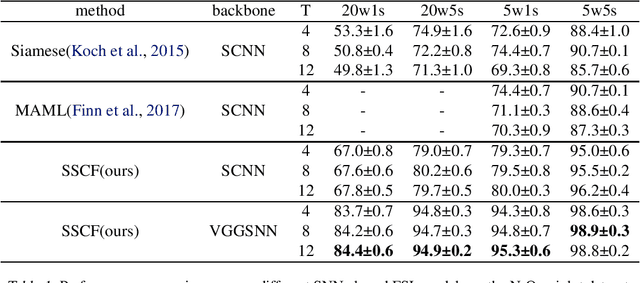
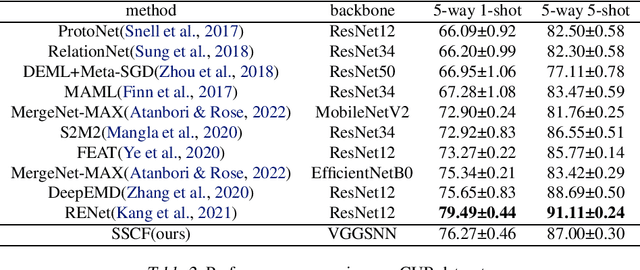
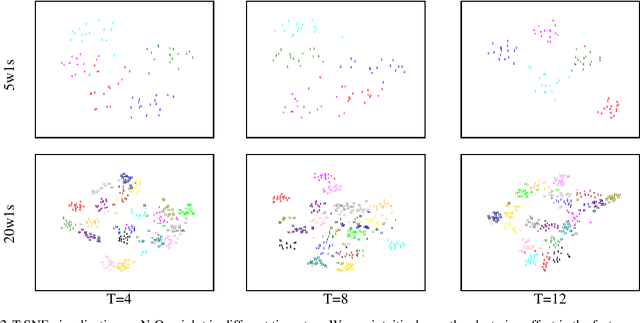
Deep neural networks (DNNs) excel in computer vision tasks, especially, few-shot learning (FSL), which is increasingly important for generalizing from limited examples. However, DNNs are computationally expensive with scalability issues in real world. Spiking Neural Networks (SNNs), with their event-driven nature and low energy consumption, are particularly efficient in processing sparse and dynamic data, though they still encounter difficulties in capturing complex spatiotemporal features and performing accurate cross-class comparisons. To further enhance the performance and efficiency of SNNs in few-shot learning, we propose a few-shot learning framework based on SNNs, which combines a self-feature extractor module and a cross-feature contrastive module to refine feature representation and reduce power consumption. We apply the combination of temporal efficient training loss and InfoNCE loss to optimize the temporal dynamics of spike trains and enhance the discriminative power. Experimental results show that the proposed FSL-SNN significantly improves the classification performance on the neuromorphic dataset N-Omniglot, and also achieves competitive performance to ANNs on static datasets such as CUB and miniImageNet with low power consumption.
Hybrid Spiking Vision Transformer for Object Detection with Event Cameras
May 12, 2025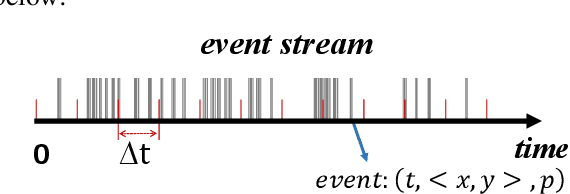
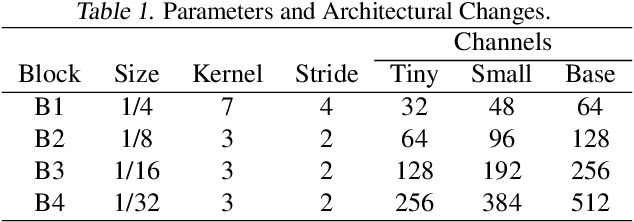

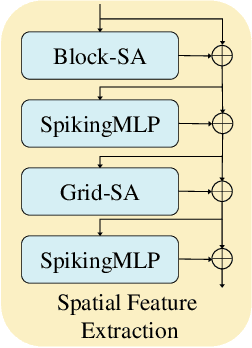
Event-based object detection has gained increasing attention due to its advantages such as high temporal resolution, wide dynamic range, and asynchronous address-event representation. Leveraging these advantages, Spiking Neural Networks (SNNs) have emerged as a promising approach, offering low energy consumption and rich spatiotemporal dynamics. To further enhance the performance of event-based object detection, this study proposes a novel hybrid spike vision Transformer (HsVT) model. The HsVT model integrates a spatial feature extraction module to capture local and global features, and a temporal feature extraction module to model time dependencies and long-term patterns in event sequences. This combination enables HsVT to capture spatiotemporal features, improving its capability to handle complex event-based object detection tasks. To support research in this area, we developed and publicly released The Fall Detection Dataset as a benchmark for event-based object detection tasks. This dataset, captured using an event-based camera, ensures facial privacy protection and reduces memory usage due to the event representation format. We evaluated the HsVT model on GEN1 and Fall Detection datasets across various model sizes. Experimental results demonstrate that HsVT achieves significant performance improvements in event detection with fewer parameters.
ALADE-SNN: Adaptive Logit Alignment in Dynamically Expandable Spiking Neural Networks for Class Incremental Learning
Dec 17, 2024



Inspired by the human brain's ability to adapt to new tasks without erasing prior knowledge, we develop spiking neural networks (SNNs) with dynamic structures for Class Incremental Learning (CIL). Our comparative experiments reveal that limited datasets introduce biases in logits distributions among tasks. Fixed features from frozen past-task extractors can cause overfitting and hinder the learning of new tasks. To address these challenges, we propose the ALADE-SNN framework, which includes adaptive logit alignment for balanced feature representation and OtoN suppression to manage weights mapping frozen old features to new classes during training, releasing them during fine-tuning. This approach dynamically adjusts the network architecture based on analytical observations, improving feature extraction and balancing performance between new and old tasks. Experiment results show that ALADE-SNN achieves an average incremental accuracy of 75.42 on the CIFAR100-B0 benchmark over 10 incremental steps. ALADE-SNN not only matches the performance of DNN-based methods but also surpasses state-of-the-art SNN-based continual learning algorithms. This advancement enhances continual learning in neuromorphic computing, offering a brain-inspired, energy-efficient solution for real-time data processing.
Context Gating in Spiking Neural Networks: Achieving Lifelong Learning through Integration of Local and Global Plasticity
Jun 04, 2024Humans learn multiple tasks in succession with minimal mutual interference, through the context gating mechanism in the prefrontal cortex (PFC). The brain-inspired models of spiking neural networks (SNN) have drawn massive attention for their energy efficiency and biological plausibility. To overcome catastrophic forgetting when learning multiple tasks in sequence, current SNN models for lifelong learning focus on memory reserving or regularization-based modification, while lacking SNN to replicate human experimental behavior. Inspired by biological context-dependent gating mechanisms found in PFC, we propose SNN with context gating trained by the local plasticity rule (CG-SNN) for lifelong learning. The iterative training between global and local plasticity for task units is designed to strengthen the connections between task neurons and hidden neurons and preserve the multi-task relevant information. The experiments show that the proposed model is effective in maintaining the past learning experience and has better task-selectivity than other methods during lifelong learning. Our results provide new insights that the CG-SNN model can extend context gating with good scalability on different SNN architectures with different spike-firing mechanisms. Thus, our models have good potential for parallel implementation on neuromorphic hardware and model human's behavior.
Towards Efficient Deep Spiking Neural Networks Construction with Spiking Activity based Pruning
Jun 03, 2024



The emergence of deep and large-scale spiking neural networks (SNNs) exhibiting high performance across diverse complex datasets has led to a need for compressing network models due to the presence of a significant number of redundant structural units, aiming to more effectively leverage their low-power consumption and biological interpretability advantages. Currently, most model compression techniques for SNNs are based on unstructured pruning of individual connections, which requires specific hardware support. Hence, we propose a structured pruning approach based on the activity levels of convolutional kernels named Spiking Channel Activity-based (SCA) network pruning framework. Inspired by synaptic plasticity mechanisms, our method dynamically adjusts the network's structure by pruning and regenerating convolutional kernels during training, enhancing the model's adaptation to the current target task. While maintaining model performance, this approach refines the network architecture, ultimately reducing computational load and accelerating the inference process. This indicates that structured dynamic sparse learning methods can better facilitate the application of deep SNNs in low-power and high-efficiency scenarios.
Enhancing Adaptive History Reserving by Spiking Convolutional Block Attention Module in Recurrent Neural Networks
Jan 08, 2024

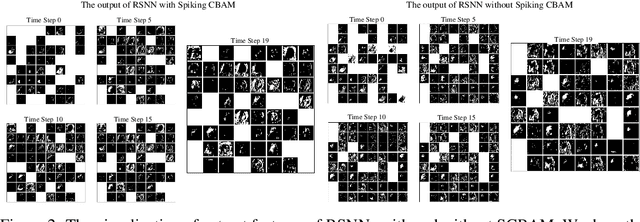
Spiking neural networks (SNNs) serve as one type of efficient model to process spatio-temporal patterns in time series, such as the Address-Event Representation data collected from Dynamic Vision Sensor (DVS). Although convolutional SNNs have achieved remarkable performance on these AER datasets, benefiting from the predominant spatial feature extraction ability of convolutional structure, they ignore temporal features related to sequential time points. In this paper, we develop a recurrent spiking neural network (RSNN) model embedded with an advanced spiking convolutional block attention module (SCBAM) component to combine both spatial and temporal features of spatio-temporal patterns. It invokes the history information in spatial and temporal channels adaptively through SCBAM, which brings the advantages of efficient memory calling and history redundancy elimination. The performance of our model was evaluated in DVS128-Gesture dataset and other time-series datasets. The experimental results show that the proposed SRNN-SCBAM model makes better use of the history information in spatial and temporal dimensions with less memory space, and achieves higher accuracy compared to other models.