 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Finetuning for Continual Learning
Mar 11, 2026The world is inherently dynamic, and continual learning aims to enable models to adapt to ever-evolving data streams. While pre-trained models have shown powerful performance in continual learning, they still require finetuning to adapt effectively to downstream tasks. However, prevailing Parameter-Efficient Fine-Tuning (PEFT) methods operate through empirical, black-box optimization at the weight level. These approaches lack explicit control over representation drift, leading to sensitivity to domain shifts and catastrophic forgetting in continual learning scenarios. In this work, we introduce Continual Representation Learning (CoRe), a novel framework that for the first time shifts the finetuning paradigm from weight space to representation space. Unlike conventional methods, CoRe performs task-specific interventions within a low-rank linear subspace of hidden representations, adopting a learning process with explicit objectives, which ensures stability for past tasks while maintaining plasticity for new ones. By constraining updates to a low-rank subspace, CoRe achieves exceptional parameter efficiency. Extensive experiments across multiple continual learning benchmarks demonstrate that CoRe not only preserves parameter efficiency but also significantly outperforms existing state-of-the-art methods. Our work introduces representation finetuning as a new, more effective and interpretable paradigm for continual learning.
Reversible Lifelong Model Editing via Semantic Routing-Based LoRA
Mar 11, 2026The dynamic evolution of real-world necessitates model editing within Large Language Models. While existing methods explore modular isolation or parameter-efficient strategies, they still suffer from semantic drift or knowledge forgetting due to continual updating. To address these challenges, we propose SoLA, a Semantic routing-based LoRA framework for lifelong model editing. In SoLA, each edit is encapsulated as an independent LoRA module, which is frozen after training and mapped to input by semantic routing, allowing dynamic activation of LoRA modules via semantic matching. This mechanism avoids semantic drift caused by cluster updating and mitigates catastrophic forgetting from parameter sharing. More importantly, SoLA supports precise revocation of specific edits by removing key from semantic routing, which restores model's original behavior. To our knowledge, this reversible rollback editing capability is the first to be achieved in existing literature. Furthermore, SoLA integrates decision-making process into edited layer, eliminating the need for auxiliary routing networks and enabling end-to-end decision-making process. Extensive experiments demonstrate that SoLA effectively learns and retains edited knowledge, achieving accurate, efficient, and reversible lifelong model editing.
A Simple Efficiency Incremental Learning Framework via Vision-Language Model with Nonlinear Multi-Adapters
Mar 11, 2026Incremental Learning (IL) aims to learn new tasks while preserving previously acquired knowledge. Integrating the zero-shot learning capabilities of pre-trained vision-language models into IL methods has marked a significant advancement. However, these methods face three primary challenges: (1) the need for improved training efficiency; (2) reliance on a memory bank to store previous data; and (3) the necessity of a strong backbone to augment the model's capabilities. In this paper, we propose SimE, a Simple and Efficient framework that employs a vision-language model with adapters designed specifically for the IL task. We report a remarkable phenomenon: there is a nonlinear correlation between the number of adaptive adapter connections and the model's IL capabilities. While increasing adapter connections between transformer blocks improves model performance, adding more adaptive connections within transformer blocks during smaller incremental steps does not enhance, and may even degrade the model's IL ability. Extensive experimental results show that SimE surpasses traditional methods by 9.6% on TinyImageNet and outperforms other CLIP-based methods by 5.3% on CIFAR-100. Furthermore, we conduct a systematic study to enhance the utilization of the zero-shot capabilities of CLIP. We suggest replacing SimE's encoder with a CLIP model trained on larger datasets (e.g., LAION2B) and stronger architectures (e.g., ViT-L/14).
Key-Value Pair-Free Continual Learner via Task-Specific Prompt-Prototype
Jan 08, 2026Continual learning aims to enable models to acquire new knowledge while retaining previously learned information. Prompt-based methods have shown remarkable performance in this domain; however, they typically rely on key-value pairing, which can introduce inter-task interference and hinder scalability. To overcome these limitations, we propose a novel approach employing task-specific Prompt-Prototype (ProP), thereby eliminating the need for key-value pairs. In our method, task-specific prompts facilitate more effective feature learning for the current task, while corresponding prototypes capture the representative features of the input. During inference, predictions are generated by binding each task-specific prompt with its associated prototype. Additionally, we introduce regularization constraints during prompt initialization to penalize excessively large values, thereby enhancing stability. Experiments on several widely used datasets demonstrate the effectiveness of the proposed method. In contrast to mainstream prompt-based approaches, our framework removes the dependency on key-value pairs, offering a fresh perspective for future continual learning research.
AVM: Towards Structure-Preserving Neural Response Modeling in the Visual Cortex Across Stimuli and Individuals
Dec 17, 2025While deep learning models have shown strong performance in simulating neural responses, they often fail to clearly separate stable visual encoding from condition-specific adaptation, which limits their ability to generalize across stimuli and individuals. We introduce the Adaptive Visual Model (AVM), a structure-preserving framework that enables condition-aware adaptation through modular subnetworks, without modifying the core representation. AVM keeps a Vision Transformer-based encoder frozen to capture consistent visual features, while independently trained modulation paths account for neural response variations driven by stimulus content and subject identity. We evaluate AVM in three experimental settings, including stimulus-level variation, cross-subject generalization, and cross-dataset adaptation, all of which involve structured changes in inputs and individuals. Across two large-scale mouse V1 datasets, AVM outperforms the state-of-the-art V1T model by approximately 2% in predictive correlation, demonstrating robust generalization, interpretable condition-wise modulation, and high architectural efficiency. Specifically, AVM achieves a 9.1% improvement in explained variance (FEVE) under the cross-dataset adaptation setting. These results suggest that AVM provides a unified framework for adaptive neural modeling across biological and experimental conditions, offering a scalable solution under structural constraints. Its design may inform future approaches to cortical modeling in both neuroscience and biologically inspired AI systems.
Distillation-Guided Structural Transfer for Continual Learning Beyond Sparse Distributed Memory
Dec 17, 2025Sparse neural systems are gaining traction for efficient continual learning due to their modularity and low interference. Architectures such as Sparse Distributed Memory Multi-Layer Perceptrons (SDMLP) construct task-specific subnetworks via Top-K activation and have shown resilience against catastrophic forgetting. However, their rigid modularity limits cross-task knowledge reuse and leads to performance degradation under high sparsity. We propose Selective Subnetwork Distillation (SSD), a structurally guided continual learning framework that treats distillation not as a regularizer but as a topology-aligned information conduit. SSD identifies neurons with high activation frequency and selectively distills knowledge within previous Top-K subnetworks and output logits, without requiring replay or task labels. This enables structural realignment while preserving sparse modularity. Experiments on Split CIFAR-10, CIFAR-100, and MNIST demonstrate that SSD improves accuracy, retention, and representation coverage, offering a structurally grounded solution for sparse continual learning.
REPAIR: Robust Editing via Progressive Adaptive Intervention and Reintegration
Oct 02, 2025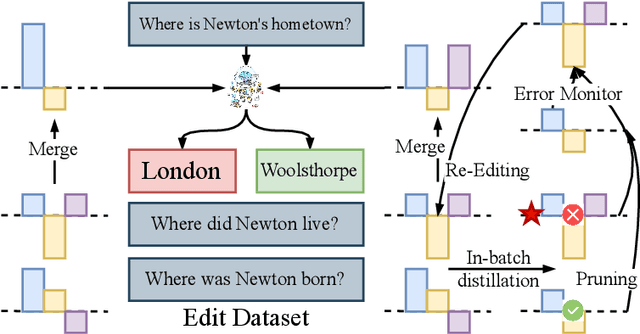
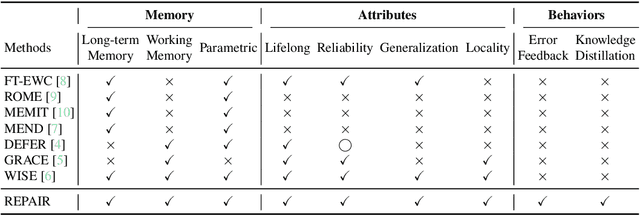
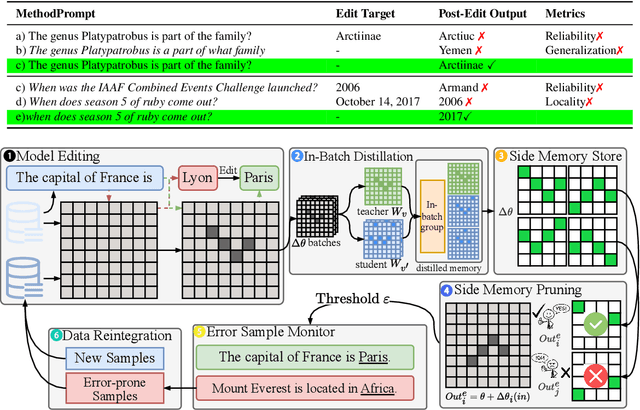
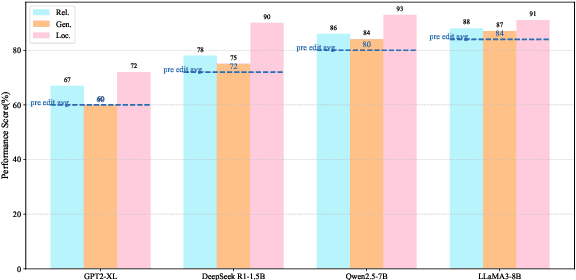
Post-training for large language models (LLMs) is constrained by the high cost of acquiring new knowledge or correcting errors and by the unintended side effects that frequently arise from retraining. To address these issues, we introduce REPAIR (Robust Editing via Progressive Adaptive Intervention and Reintegration), a lifelong editing framework designed to support precise and low-cost model updates while preserving non-target knowledge. REPAIR mitigates the instability and conflicts of large-scale sequential edits through a closed-loop feedback mechanism coupled with dynamic memory management. Furthermore, by incorporating frequent knowledge fusion and enforcing strong locality guards, REPAIR effectively addresses the shortcomings of traditional distribution-agnostic approaches that often overlook unintended ripple effects. Our experiments demonstrate that REPAIR boosts editing accuracy by 10%-30% across multiple model families and significantly reduces knowledge forgetting. This work introduces a robust framework for developing reliable, scalable, and continually evolving LLMs.
Brain-inspired continual pre-trained learner via silent synaptic consolidation
Oct 08, 2024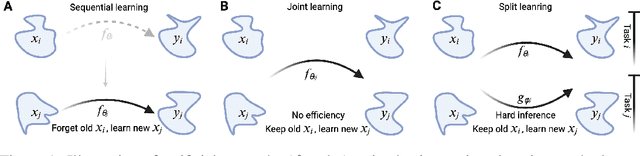
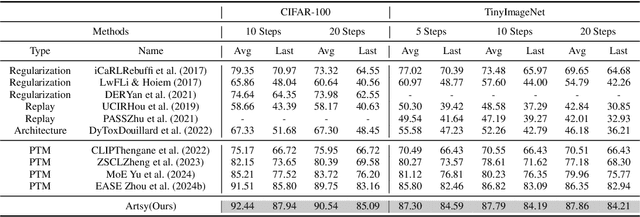
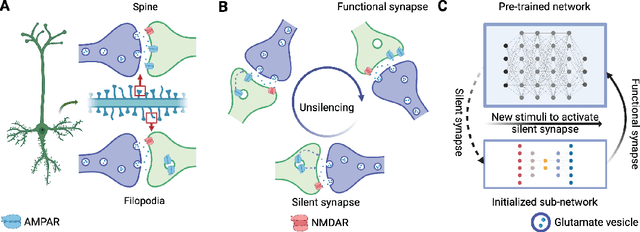
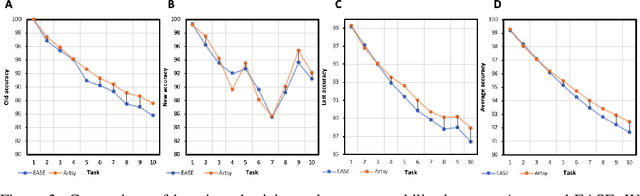
Pre-trained models have demonstrated impressive generalization capabilities, yet they remain vulnerable to catastrophic forgetting when incrementally trained on new tasks. Existing architecture-based strategies encounter two primary challenges: 1) Integrating a pre-trained network with a trainable sub-network complicates the delicate balance between learning plasticity and memory stability across evolving tasks during learning. 2) The absence of robust interconnections between pre-trained networks and various sub-networks limits the effective retrieval of pertinent information during inference. In this study, we introduce the Artsy, inspired by the activation mechanisms of silent synapses via spike-timing-dependent plasticity observed in mature brains, to enhance the continual learning capabilities of pre-trained models. The Artsy integrates two key components: During training, the Artsy mimics mature brain dynamics by maintaining memory stability for previously learned knowledge within the pre-trained network while simultaneously promoting learning plasticity in task-specific sub-networks. During inference, artificial silent and functional synapses are utilized to establish precise connections between the pre-synaptic neurons in the pre-trained network and the post-synaptic neurons in the sub-networks, facilitated through synaptic consolidation, thereby enabling effective extraction of relevant information from test samples. Comprehensive experimental evaluations reveal that our model significantly outperforms conventional methods on class-incremental learning tasks, while also providing enhanced biological interpretability for architecture-based approaches. Moreover, we propose that the Artsy offers a promising avenue for simulating biological synaptic mechanisms, potentially advancing our understanding of neural plasticity in both artificial and biological systems.
AdaViPro: Region-based Adaptive Visual Prompt for Large-Scale Models Adapting
Mar 20, 2024



Recently, prompt-based methods have emerged as a new alternative `parameter-efficient fine-tuning' paradigm, which only fine-tunes a small number of additional parameters while keeping the original model frozen. However, despite achieving notable results, existing prompt methods mainly focus on `what to add', while overlooking the equally important aspect of `where to add', typically relying on the manually crafted placement. To this end, we propose a region-based Adaptive Visual Prompt, named AdaViPro, which integrates the `where to add' optimization of the prompt into the learning process. Specifically, we reconceptualize the `where to add' optimization as a problem of regional decision-making. During inference, AdaViPro generates a regionalized mask map for the whole image, which is composed of 0 and 1, to designate whether to apply or discard the prompt in each specific area. Therefore, we employ Gumbel-Softmax sampling to enable AdaViPro's end-to-end learning through standard back-propagation. Extensive experiments demonstrate that our AdaViPro yields new efficiency and accuracy trade-offs for adapting pre-trained models.
Enhancing Adaptive History Reserving by Spiking Convolutional Block Attention Module in Recurrent Neural Networks
Jan 08, 2024

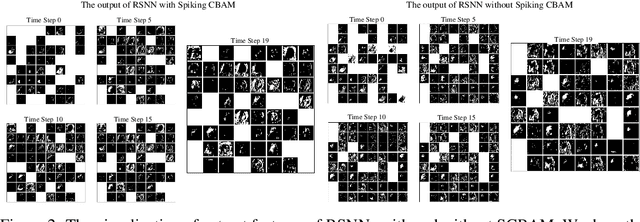
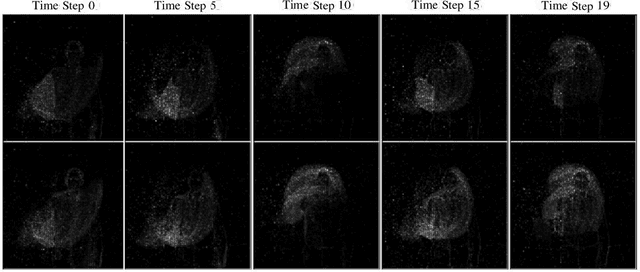
Spiking neural networks (SNNs) serve as one type of efficient model to process spatio-temporal patterns in time series, such as the Address-Event Representation data collected from Dynamic Vision Sensor (DVS). Although convolutional SNNs have achieved remarkable performance on these AER datasets, benefiting from the predominant spatial feature extraction ability of convolutional structure, they ignore temporal features related to sequential time points. In this paper, we develop a recurrent spiking neural network (RSNN) model embedded with an advanced spiking convolutional block attention module (SCBAM) component to combine both spatial and temporal features of spatio-temporal patterns. It invokes the history information in spatial and temporal channels adaptively through SCBAM, which brings the advantages of efficient memory calling and history redundancy elimination. The performance of our model was evaluated in DVS128-Gesture dataset and other time-series datasets. The experimental results show that the proposed SRNN-SCBAM model makes better use of the history information in spatial and temporal dimensions with less memory space, and achieves higher accuracy compared to other models.