 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenPT: Beyond Self-Report for Reliable LLM Psychometrics via Generative Projective Testing
May 30, 2026Self-report questionnaires remain the prevailing tool for probing the psychological states of persona-conditioned agents (PC-Agents). However, classical instruments inherit two well-known threats: contamination from training corpora and directional bias driven by social-desirability or contextual framing. To overcome these methodological bottlenecks, we ask whether projective paradigms can be adapted into a robust psychometric tool. We introduce \textbf{GenPT} (Generative Projective Testing), which reformulates TAT, Rorschach, and SCT with newly generated stimuli and organizes assessment as a three-stage pipeline to derive standardized psychological indicators and target states. Evaluating PC-Agents induced via CharacterRAG and AnnaAgent profiles, we benchmark GenPT's reliability and validity against classical questionnaires. The results indicate that questionnaires exhibit systematic directional shifts under social-desirability framing, most strongly on suicide ideation. In contrast, GenPT's collected behavioral patterns stay near the symmetric baseline. Furthermore, under a longitudinal counselling context, GenPT-based depression assessment shifts by roughly an order of magnitude more than the questionnaire counterpart when Qwen3 serves as the backbone. Overall, GenPT complements self-report methods in scenarios where contamination resistance, bias asymmetry, and context sensitivity matter. Code and stimuli can be found at https://github.com/sci-m-wang/GenPT.
Translating Signals to Languages for sEMG-Based Activity Recognition
May 21, 2026Surface electromyography (sEMG) signal-based activity recognition has attracted increasing research attention in recent years. To develop accurate sEMG signal-based activity recognizers, numerous approaches have been proposed. Some studies focus on designing larger and more expressive model architectures to enhance the representational capacity of sEMG signals, while others aim to enrich model priors through large-scale pretraining, thereby improving recognition performance. Recently, large language models (LLMs) have shown remarkable generalization and reasoning capabilities in natural language processing, whose implicit knowledge, learned from extensive linguistic descriptions of actions, opens new possibilities for interpreting sEMG signals and inferring activity intentions. Motivated by this, we propose LLM-sEMG, a novel framework that leverages LLMs as sEMG activity recognizers. Within this framework, we design a language-oriented mapping mechanism that converts continuous sEMG sequences into sEMG language, integrating several strategies to further facilitate the signal-to-language mapping process. Extensive experiments demonstrate that the proposed framework achieves highly accurate sEMG signal-based activity recognition using large language models.
AgenticQwen: Training Small Agentic Language Models with Dual Data Flywheels for Industrial-Scale Tool Use
Apr 23, 2026Modern industrial applications increasingly demand language models that act as agents, capable of multi-step reasoning and tool use in real-world settings. These tasks are typically performed under strict cost and latency constraints, making small agentic models highly desirable. In this paper, we introduce the AgenticQwen family of models, trained via multi-round reinforcement learning (RL) on synthetic data and a limited amount of open-source data. Our training framework combines reasoning RL and agentic RL with dual data flywheels that automatically generate increasingly challenging tasks. The reasoning flywheel increases task difficulty by learning from errors, while the agentic flywheel expands linear workflows into multi-branch behavior trees that better reflect the decision complexity of real-world applications. We validate AgenticQwen on public benchmarks and in an industrial agent system. The models achieve strong performance on multiple agentic benchmarks, and in our industrial agent system, close the gap with much larger models on search and data analysis tasks. Model checkpoints and part of the synthetic data: https://huggingface.co/collections/alibaba-pai/agenticqwen. Data synthesis and RL training code: https://github.com/haruhi-sudo/data_synth_and_rl. The data synthesis pipeline is also integrated into EasyDistill: https://github.com/modelscope/easydistill.
A Systematic Analysis of the Impact of Persona Steering on LLM Capabilities
Apr 13, 2026Imbuing Large Language Models (LLMs) with specific personas is prevalent for tailoring interaction styles, yet the impact on underlying cognitive capabilities remains unexplored. We employ the Neuron-based Personality Trait Induction (NPTI) framework to induce Big Five personality traits in LLMs and evaluate performance across six cognitive benchmarks. Our findings reveal that persona induction produces stable, reproducible shifts in cognitive task performance beyond surface-level stylistic changes. These effects exhibit strong task dependence: certain personalities yield consistent gains on instruction-following, while others impair complex reasoning. Effect magnitude varies systematically by trait dimension, with Openness and Extraversion exerting the most robust influence. Furthermore, LLM effects show 73.68% directional consistency with human personality-cognition relationships. Capitalizing on these regularities, we propose Dynamic Persona Routing (DPR), a lightweight query-adaptive strategy that outperforms the best static persona without additional training.
Synthetic or Authentic? Building Mental Patient Simulators from Longitudinal Evidence
Mar 24, 2026Patient simulation is essential for developing and evaluating mental health dialogue systems. As most existing approaches rely on snapshot-style prompts with limited profile information, homogeneous behaviors and incoherent disease progression in multi-turn interactions have become key chellenges. In this work, we propose DEPROFILE, a data-grounded patient simulation framework that constructs unified, multi-source patient profiles by integrating demographic attributes, standardized clinical symptoms, counseling dialogues, and longitudinal life-event histories from real-world data. We further introduce a Chain-of-Change agent to transform noisy longitudinal records into structured, temporally grounded memory representations for simulation. Experiments across multiple large language model (LLM) backbones show that with more comprehensive profile constructed by DEPROFILE, the dialogue realism, behavioral diversity, and event richness have consistently improved and exceed state-of-the-art baselines, highlighting the importance of grounding patient simulation in verifiable longitudinal evidence.
Fine-grained Verbal Attack Detection via a Hierarchical Divide-and-Conquer Framework
Jan 11, 2026In the digital era, effective identification and analysis of verbal attacks are essential for maintaining online civility and ensuring social security. However, existing research is limited by insufficient modeling of conversational structure and contextual dependency, particularly in Chinese social media where implicit attacks are prevalent. Current attack detection studies often emphasize general semantic understanding while overlooking user response relationships, hindering the identification of implicit and context-dependent attacks. To address these challenges, we present the novel "Hierarchical Attack Comment Detection" dataset and propose a divide-and-conquer, fine-grained framework for verbal attack recognition based on spatiotemporal information. The proposed dataset explicitly encodes hierarchical reply structures and chronological order, capturing complex interaction patterns in multi-turn discussions. Building on this dataset, the framework decomposes attack detection into hierarchical subtasks, where specialized lightweight models handle explicit detection, implicit intent inference, and target identification under constrained context. Extensive experiments on the proposed dataset and benchmark intention detection datasets show that smaller models using our framework significantly outperform larger monolithic models relying on parameter scaling, demonstrating the effectiveness of structured task decomposition.
MindChat: A Privacy-preserving Large Language Model for Mental Health Support
Jan 05, 2026Large language models (LLMs) have shown promise for mental health support, yet training such models is constrained by the scarcity and sensitivity of real counseling dialogues. In this article, we present MindChat, a privacy-preserving LLM for mental health support, together with MindCorpus, a synthetic multi-turn counseling dataset constructed via a multi-agent role-playing framework. To synthesize high-quality counseling data, the developed dialogue-construction framework employs a dual closed-loop feedback design to integrate psychological expertise and counseling techniques through role-playing: (i) turn-level critique-and-revision to improve coherence and counseling appropriateness within a session, and (ii) session-level strategy refinement to progressively enrich counselor behaviors across sessions. To mitigate privacy risks under decentralized data ownership, we fine-tune the base model using federated learning with parameter-efficient LoRA adapters and incorporate differentially private optimization to reduce membership and memorization risks. Experiments on synthetic-data quality assessment and counseling capability evaluation show that MindCorpus improves training effectiveness and that MindChat is competitive with existing general and counseling-oriented LLM baselines under both automatic LLM-judge and human evaluation protocols, while exhibiting reduced privacy leakage under membership inference attacks.
REPAIR: Robust Editing via Progressive Adaptive Intervention and Reintegration
Oct 02, 2025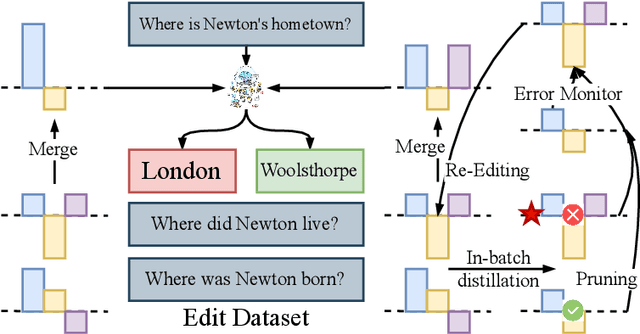
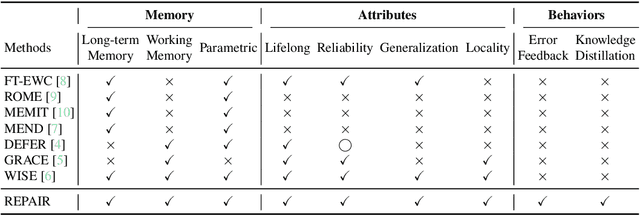
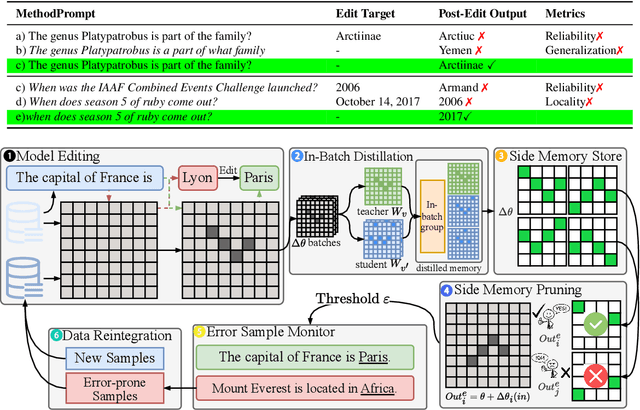
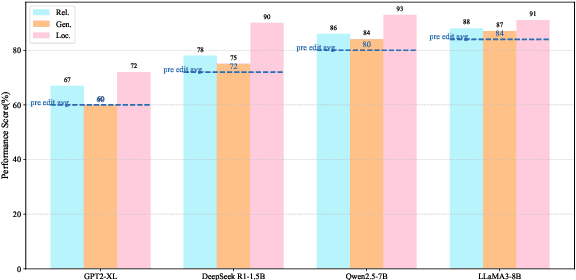
Post-training for large language models (LLMs) is constrained by the high cost of acquiring new knowledge or correcting errors and by the unintended side effects that frequently arise from retraining. To address these issues, we introduce REPAIR (Robust Editing via Progressive Adaptive Intervention and Reintegration), a lifelong editing framework designed to support precise and low-cost model updates while preserving non-target knowledge. REPAIR mitigates the instability and conflicts of large-scale sequential edits through a closed-loop feedback mechanism coupled with dynamic memory management. Furthermore, by incorporating frequent knowledge fusion and enforcing strong locality guards, REPAIR effectively addresses the shortcomings of traditional distribution-agnostic approaches that often overlook unintended ripple effects. Our experiments demonstrate that REPAIR boosts editing accuracy by 10%-30% across multiple model families and significantly reduces knowledge forgetting. This work introduces a robust framework for developing reliable, scalable, and continually evolving LLMs.
DIFNet: Decentralized Information Filtering Fusion Neural Network with Unknown Correlation in Sensor Measurement Noises
Aug 26, 2025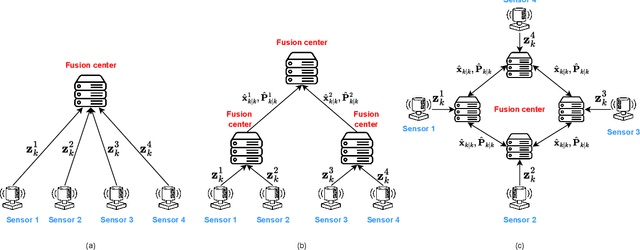
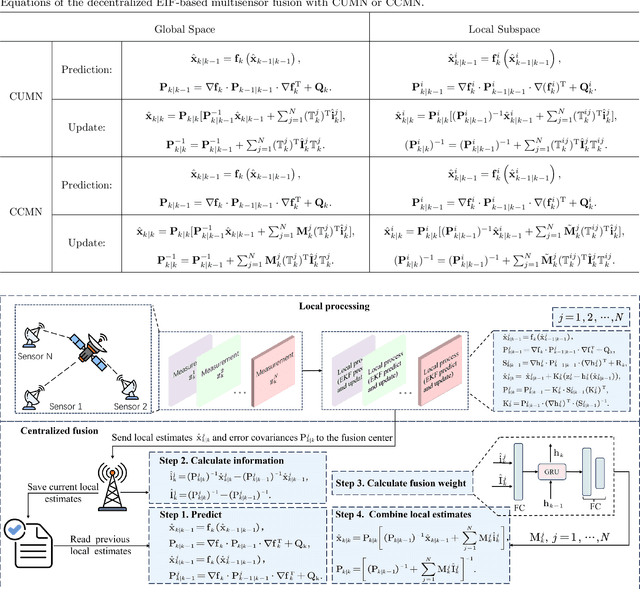
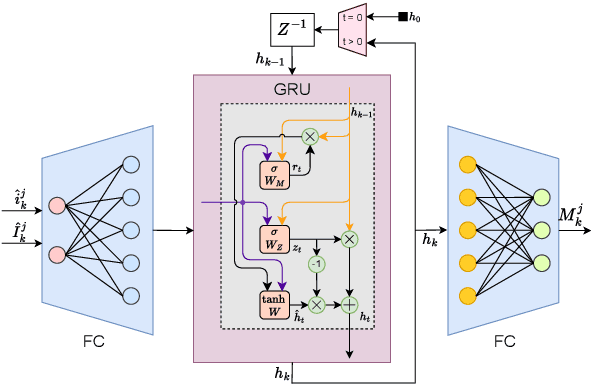
In recent years, decentralized sensor networks have garnered significant attention in the field of state estimation owing to enhanced robustness, scalability, and fault tolerance. Optimal fusion performance can be achieved under fully connected communication and known noise correlation structures. To mitigate communication overhead, the global state estimation problem is decomposed into local subproblems through structured observation model. This ensures that even when the communication network is not fully connected, each sensor can achieve locally optimal estimates of its observable state components. To address the degradation of fusion accuracy induced by unknown correlations in measurement noise, this paper proposes a data-driven method, termed Decentralized Information Filter Neural Network (DIFNet), to learn unknown noise correlations in data for discrete-time nonlinear state space models with cross-correlated measurement noises. Numerical simulations demonstrate that DIFNet achieves superior fusion performance compared to conventional filtering methods and exhibits robust characteristics in more complex scenarios, such as the presence of time-varying noise. The source code used in our numerical experiment can be found online at https://wisdom-estimation.github.io/DIFNet_Demonstrate/.
Artificial Intelligence-Based Multiscale Temporal Modeling for Anomaly Detection in Cloud Services
Aug 20, 2025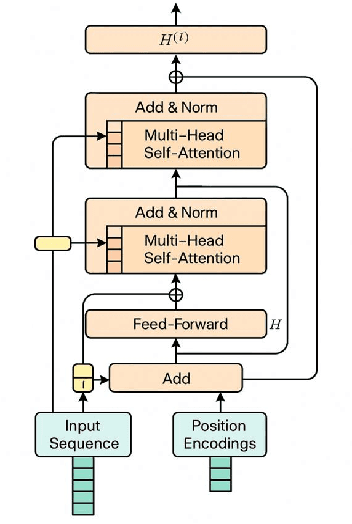
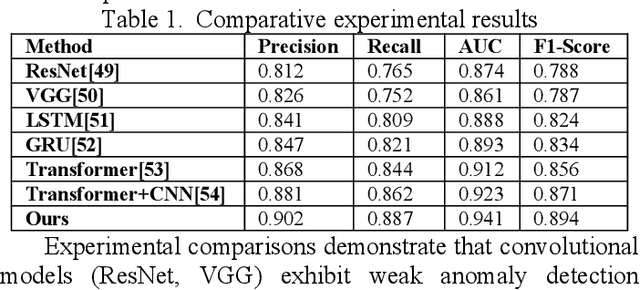
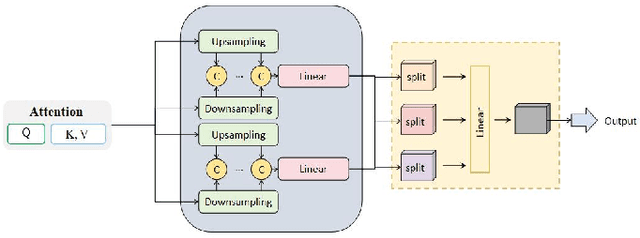
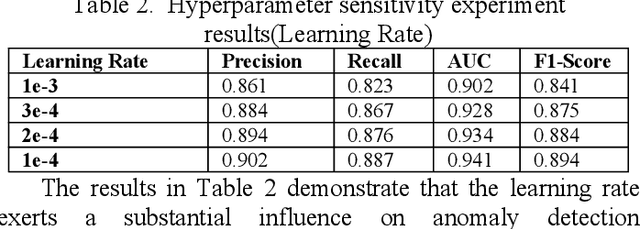
This study proposes an anomaly detection method based on the Transformer architecture with integrated multiscale feature perception, aiming to address the limitations of temporal modeling and scale-aware feature representation in cloud service environments. The method first employs an improved Transformer module to perform temporal modeling on high-dimensional monitoring data, using a self-attention mechanism to capture long-range dependencies and contextual semantics. Then, a multiscale feature construction path is introduced to extract temporal features at different granularities through downsampling and parallel encoding. An attention-weighted fusion module is designed to dynamically adjust the contribution of each scale to the final decision, enhancing the model's robustness in anomaly pattern modeling. In the input modeling stage, standardized multidimensional time series are constructed, covering core signals such as CPU utilization, memory usage, and task scheduling states, while positional encoding is used to strengthen the model's temporal awareness. A systematic experimental setup is designed to evaluate performance, including comparative experiments and hyperparameter sensitivity analysis, focusing on the impact of optimizers, learning rates, anomaly ratios, and noise levels. Experimental results show that the proposed method outperforms mainstream baseline models in key metrics, including precision, recall, AUC, and F1-score, and maintains strong stability and detection performance under various perturbation conditions, demonstrating its superior capability in complex cloud environments.