 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepImagine: Learning Biomedical Reasoning via Successive Counterfactual Imagining
Apr 24, 2026Predicting the outcomes of prospective clinical trials remains a major challenge for large language models. Prior work has shown that both traditional correlational predictors, such as random forests and logistic regression, and strong commercial LLMs achieve limited performance on this task. In this paper, we propose DeepImagine, a framework for teaching LLMs biomedical reasoning through successive counterfactual imagining. The central idea is to approximate hidden causal mechanisms of clinical trials by training models to infer how observed trial results would change under controlled perturbations of experimental conditions, such as dosage, outcome measures, study arms, geography, and other trial attributes. To support this objective, we construct both natural and approximate counterfactual pairs from real clinical trials with reported outcomes. For settings where strict counterfactual supervision is available, such as paired outcome measures or dose-ranging study arms within the same trial, we train models with supervised fine-tuning. For broader settings where only approximate counterfactual pairs can be retrieved, we optimize models with reinforcement learning using verifiable rewards based on downstream benchmark correctness. We further augment training with synthetic reasoning traces that provide causally plausible explanations for local counterfactual transitions. Using this pipeline, we train language models under 10B parameters, including Qwen3.5-9B, and evaluate them on clinical trial outcome prediction. We aim to show that DeepImagine consistently improves over untuned language models and traditional correlational baselines. Finally, we aim to show that the learned reasoning trajectories provide interpretable signals about how models represent trial-level mechanisms, suggesting a practical path toward more mechanistic and scientifically useful biomedical language models.
EvidenceBench: A Benchmark for Extracting Evidence from Biomedical Papers
Apr 25, 2025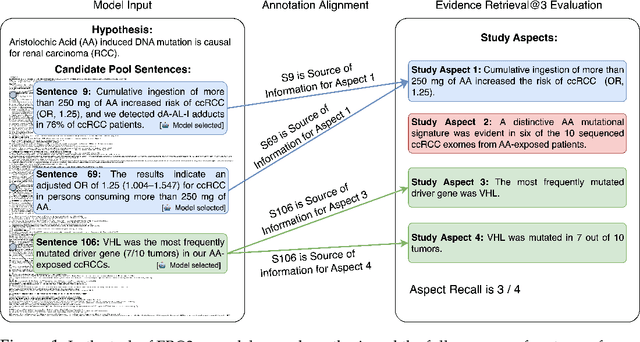



We study the task of automatically finding evidence relevant to hypotheses in biomedical papers. Finding relevant evidence is an important step when researchers investigate scientific hypotheses. We introduce EvidenceBench to measure models performance on this task, which is created by a novel pipeline that consists of hypothesis generation and sentence-by-sentence annotation of biomedical papers for relevant evidence, completely guided by and faithfully following existing human experts judgment. We demonstrate the pipeline's validity and accuracy with multiple sets of human-expert annotations. We evaluated a diverse set of language models and retrieval systems on the benchmark and found that model performances still fall significantly short of the expert level on this task. To show the scalability of our proposed pipeline, we create a larger EvidenceBench-100k with 107,461 fully annotated papers with hypotheses to facilitate model training and development. Both datasets are available at https://github.com/EvidenceBench/EvidenceBench
Single-Pass Document Scanning for Question Answering
Apr 04, 2025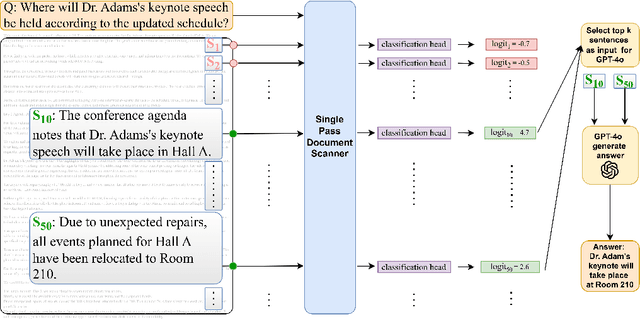
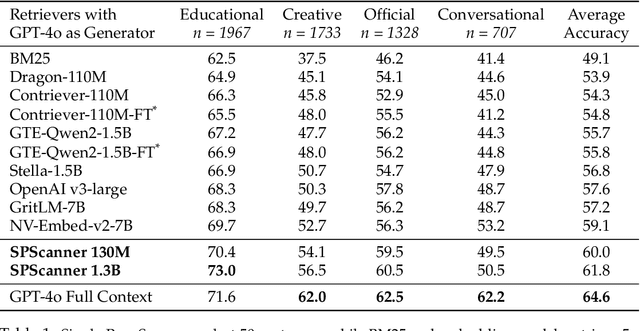
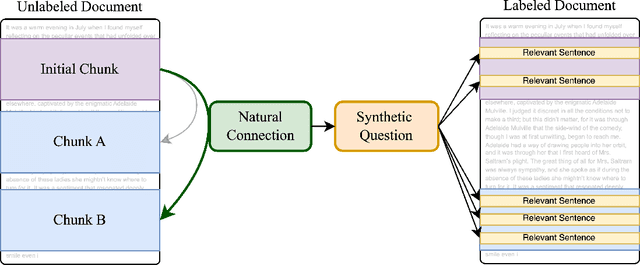
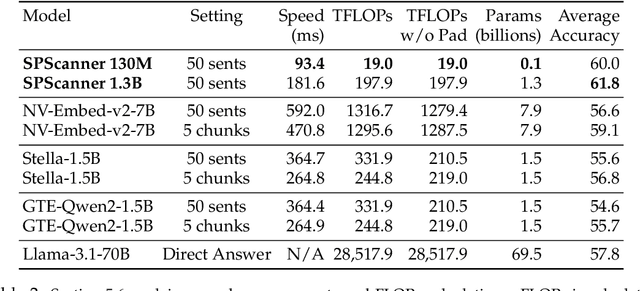
Handling extremely large documents for question answering is challenging: chunk-based embedding methods often lose track of important global context, while full-context transformers can be prohibitively expensive for hundreds of thousands of tokens. We propose a single-pass document scanning approach that processes the entire text in linear time, preserving global coherence while deciding which sentences are most relevant to the query. On 41 QA benchmarks, our single-pass scanner consistently outperforms chunk-based embedding methods and competes with large language models at a fraction of the computational cost. By conditioning on the entire preceding context without chunk breaks, the method preserves global coherence, which is especially important for long documents. Overall, single-pass document scanning offers a simple solution for question answering over massive text. All code, datasets, and model checkpoints are available at https://github.com/MambaRetriever/MambaRetriever
Measuring Risk of Bias in Biomedical Reports: The RoBBR Benchmark
Nov 28, 2024



Systems that answer questions by reviewing the scientific literature are becoming increasingly feasible. To draw reliable conclusions, these systems should take into account the quality of available evidence, placing more weight on studies that use a valid methodology. We present a benchmark for measuring the methodological strength of biomedical papers, drawing on the risk-of-bias framework used for systematic reviews. The four benchmark tasks, drawn from more than 500 papers, cover the analysis of research study methodology, followed by evaluation of risk of bias in these studies. The benchmark contains 2000 expert-generated bias annotations, and a human-validated pipeline for fine-grained alignment with research paper content. We evaluate a range of large language models on the benchmark, and find that these models fall significantly short of expert-level performance. By providing a standardized tool for measuring judgments of study quality, the benchmark can help to guide systems that perform large-scale aggregation of scientific data. The dataset is available at https://github.com/RoBBR-Benchmark/RoBBR.
IR2: Information Regularization for Information Retrieval
Feb 25, 2024



Effective information retrieval (IR) in settings with limited training data, particularly for complex queries, remains a challenging task. This paper introduces IR2, Information Regularization for Information Retrieval, a technique for reducing overfitting during synthetic data generation. This approach, representing a novel application of regularization techniques in synthetic data creation for IR, is tested on three recent IR tasks characterized by complex queries: DORIS-MAE, ArguAna, and WhatsThatBook. Experimental results indicate that our regularization techniques not only outperform previous synthetic query generation methods on the tasks considered but also reduce cost by up to 50%. Furthermore, this paper categorizes and explores three regularization methods at different stages of the query synthesis pipeline-input, prompt, and output-each offering varying degrees of performance improvement compared to models where no regularization is applied. This provides a systematic approach for optimizing synthetic data generation in data-limited, complex-query IR scenarios. All code, prompts and synthetic data are available at https://github.com/Info-Regularization/Information-Regularization.
BIRCO: A Benchmark of Information Retrieval Tasks with Complex Objectives
Feb 21, 2024We present the Benchmark of Information Retrieval (IR) tasks with Complex Objectives (BIRCO). BIRCO evaluates the ability of IR systems to retrieve documents given multi-faceted user objectives. The benchmark's complexity and compact size make it suitable for evaluating large language model (LLM)-based information retrieval systems. We present a modular framework for investigating factors that may influence LLM performance on retrieval tasks, and identify a simple baseline model which matches or outperforms existing approaches and more complex alternatives. No approach achieves satisfactory performance on all benchmark tasks, suggesting that stronger models and new retrieval protocols are necessary to address complex user needs.
DORIS-MAE: Scientific Document Retrieval using Multi-level Aspect-based Queries
Oct 10, 2023In scientific research, the ability to effectively retrieve relevant documents based on complex, multifaceted queries is critical. Existing evaluation datasets for this task are limited, primarily due to the high cost and effort required to annotate resources that effectively represent complex queries. To address this, we propose a novel task, Scientific DOcument Retrieval using Multi-level Aspect-based quEries (DORIS-MAE), which is designed to handle the complex nature of user queries in scientific research. We developed a benchmark dataset within the field of computer science, consisting of 100 human-authored complex query cases. For each complex query, we assembled a collection of 100 relevant documents and produced annotated relevance scores for ranking them. Recognizing the significant labor of expert annotation, we also introduce Anno-GPT, a scalable framework for validating the performance of Large Language Models (LLMs) on expert-level dataset annotation tasks. LLM annotation of the DORIS-MAE dataset resulted in a 500x reduction in cost, without compromising quality. Furthermore, due to the multi-tiered structure of these complex queries, the DORIS-MAE dataset can be extended to over 4,000 sub-query test cases without requiring additional annotation. We evaluated 17 recent retrieval methods on DORIS-MAE, observing notable performance drops compared to traditional datasets. This highlights the need for better approaches to handle complex, multifaceted queries in scientific research. Our dataset and codebase are available at https://github.com/Real-Doris-Mae/Doris-Mae-Dataset.
There Once Was a Really Bad Poet, It Was Automated but You Didn't Know It
Mar 05, 2021
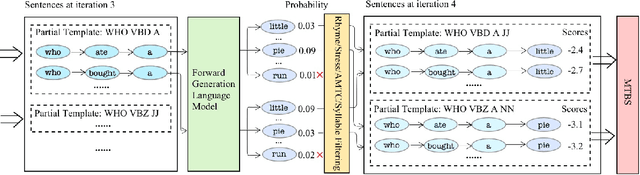

Limerick generation exemplifies some of the most difficult challenges faced in poetry generation, as the poems must tell a story in only five lines, with constraints on rhyme, stress, and meter. To address these challenges, we introduce LimGen, a novel and fully automated system for limerick generation that outperforms state-of-the-art neural network-based poetry models, as well as prior rule-based poetry models. LimGen consists of three important pieces: the Adaptive Multi-Templated Constraint algorithm that constrains our search to the space of realistic poems, the Multi-Templated Beam Search algorithm which searches efficiently through the space, and the probabilistic Storyline algorithm that provides coherent storylines related to a user-provided prompt word. The resulting limericks satisfy poetic constraints and have thematically coherent storylines, which are sometimes even funny (when we are lucky).
Cryo-ZSSR: multiple-image super-resolution based on deep internal learning
Nov 22, 2020
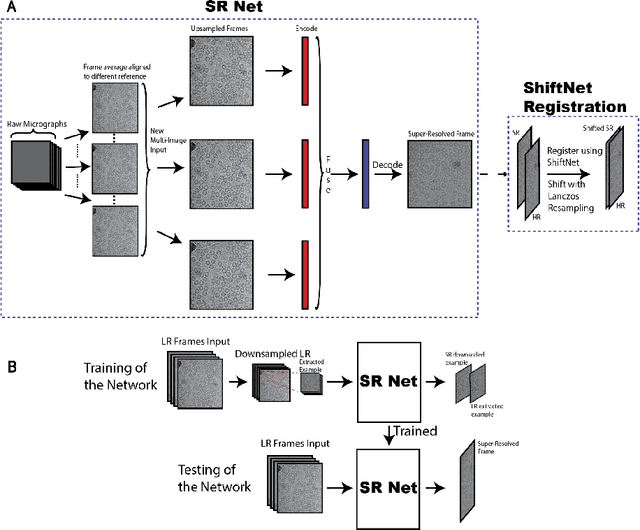
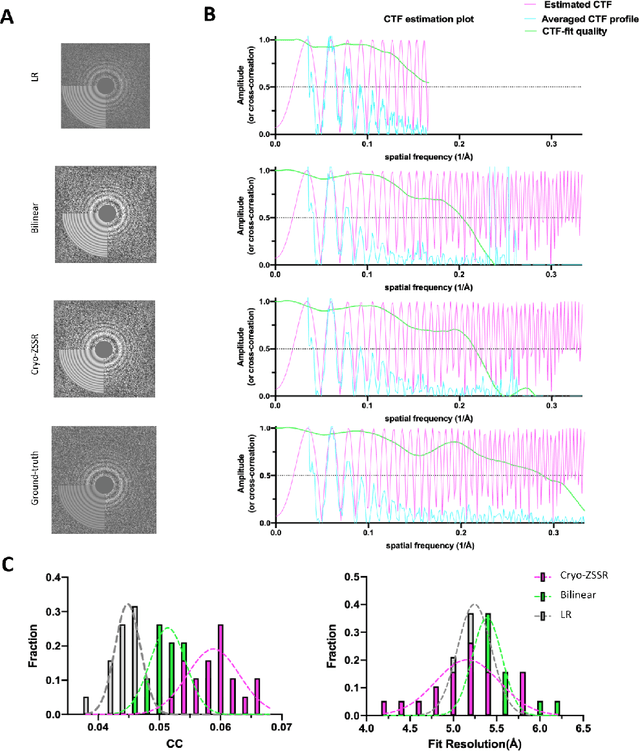
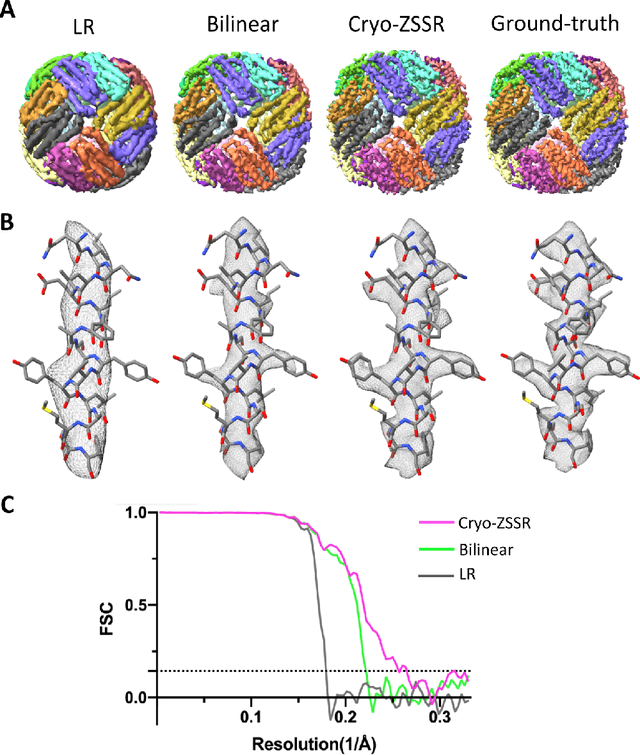
Single-particle cryo-electron microscopy (cryo-EM) is an emerging imaging modality capable of visualizing proteins and macro-molecular complexes at near-atomic resolution. The low electron-doses used to prevent sample radiation damage, result in images where the power of the noise is 100 times greater than the power of the signal. To overcome the low-SNRs, hundreds of thousands of particle projections acquired over several days of data collection are averaged in 3D to determine the structure of interest. Meanwhile, recent image super-resolution (SR) techniques based on neural networks have shown state of the art performance on natural images. Building on these advances, we present a multiple-image SR algorithm based on deep internal learning designed specifically to work under low-SNR conditions. Our approach leverages the internal image statistics of cryo-EM movies and does not require training on ground-truth data. When applied to a single-particle dataset of apoferritin, we show that the resolution of 3D structures obtained from SR micrographs can surpass the limits imposed by the imaging system. Our results indicate that the combination of low magnification imaging with image SR has the potential to accelerate cryo-EM data collection without sacrificing resolution.
Speech Emotion Recognition with Dual-Sequence LSTM Architecture
Oct 20, 2019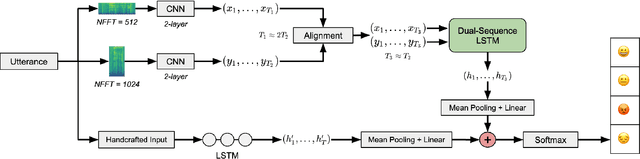
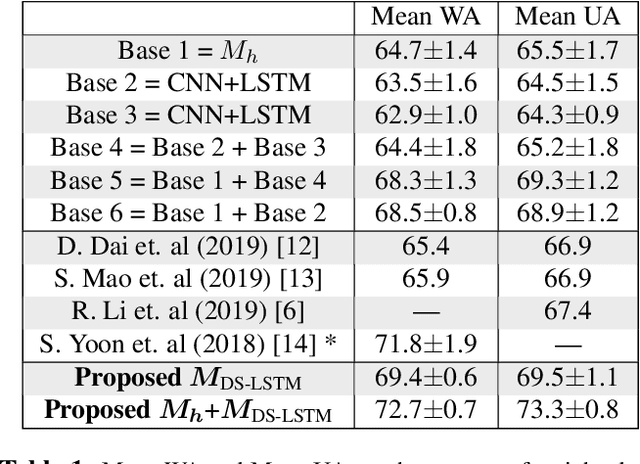
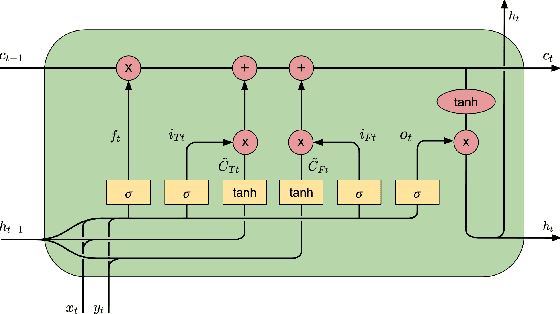
Speech Emotion Recognition (SER) has emerged as a critical component of the next generation of human-machine interfacing technologies. In this work, we propose a new dual-level model that combines handcrafted and raw features for audio signals. Each utterance is preprocessed into a handcrafted input and two mel-spectrograms at different time-frequency resolutions. An LSTM processes the handcrafted input, while a novel LSTM architecture, denoted as Dual-Sequence LSTM (DS-LSTM), processes the two mel-spectrograms simultaneously. The outputs are later averaged to produce a final classification of the utterance. Our proposed model achieves, on average, a weighted accuracy of 72.7% and an unweighted accuracy of 73.3% --- a 6% improvement over current state-of-the-art models --- and is comparable with multimodal SER models that leverage textual information.