 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Surprising Soupability of Documents in State Space Models
May 29, 2025We investigate whether hidden states from Structured State Space Models (SSMs) can be merged post-hoc to support downstream reasoning. Inspired by model souping, we propose a strategy where documents are encoded independently and their representations are pooled -- via simple operations like averaging -- into a single context state. This approach, which we call document souping, enables modular encoding and reuse without reprocessing the full input for each query. We finetune Mamba2 models to produce soupable representations and find that they support multi-hop QA, sparse retrieval, and long-document reasoning with strong accuracy. On HotpotQA, souping ten independently encoded documents nearly matches the performance of a cross-encoder trained on the same inputs.
Quiet Feature Learning in Algorithmic Tasks
May 06, 2025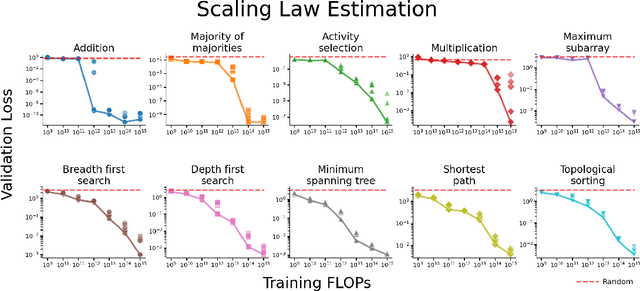
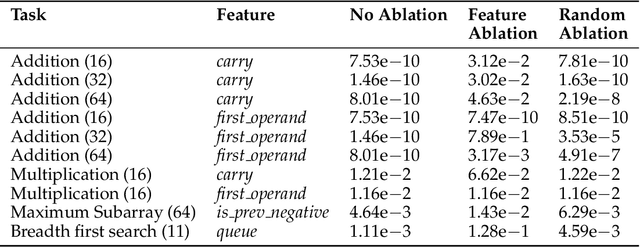
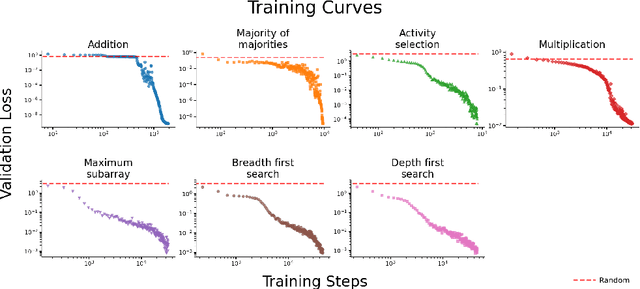
We train Transformer-based language models on ten foundational algorithmic tasks and observe pronounced phase transitions in their loss curves that deviate from established power-law scaling trends. Over large ranges of compute, the validation loss barely improves, then abruptly decreases. Probing the models' internal representations reveals the learning of quiet features during the stagnant phase, followed by sudden acquisition of loud features that coincide with the sharp drop in loss. Our ablation experiments show that disrupting a single learned feature can dramatically degrade performance, providing evidence of their causal role in task performance. These findings challenge the prevailing assumption that next-token predictive loss reliably tracks incremental progress; instead, key internal features may be developing below the surface until they coalesce, triggering a rapid performance gain.
EvidenceBench: A Benchmark for Extracting Evidence from Biomedical Papers
Apr 25, 2025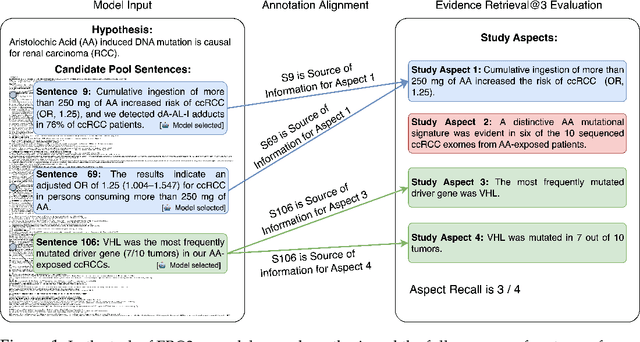



We study the task of automatically finding evidence relevant to hypotheses in biomedical papers. Finding relevant evidence is an important step when researchers investigate scientific hypotheses. We introduce EvidenceBench to measure models performance on this task, which is created by a novel pipeline that consists of hypothesis generation and sentence-by-sentence annotation of biomedical papers for relevant evidence, completely guided by and faithfully following existing human experts judgment. We demonstrate the pipeline's validity and accuracy with multiple sets of human-expert annotations. We evaluated a diverse set of language models and retrieval systems on the benchmark and found that model performances still fall significantly short of the expert level on this task. To show the scalability of our proposed pipeline, we create a larger EvidenceBench-100k with 107,461 fully annotated papers with hypotheses to facilitate model training and development. Both datasets are available at https://github.com/EvidenceBench/EvidenceBench
Single-Pass Document Scanning for Question Answering
Apr 04, 2025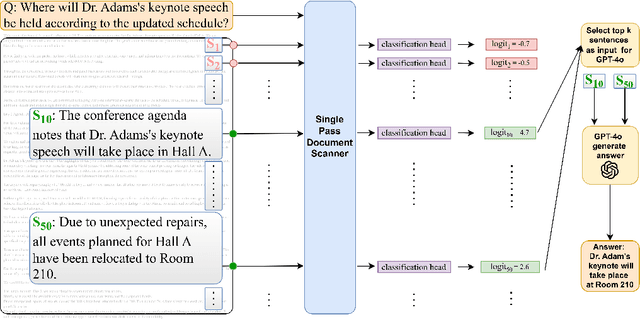
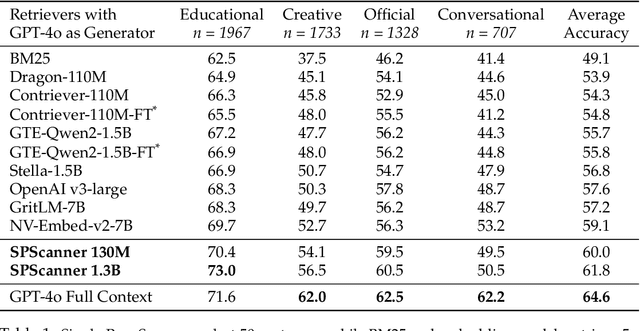
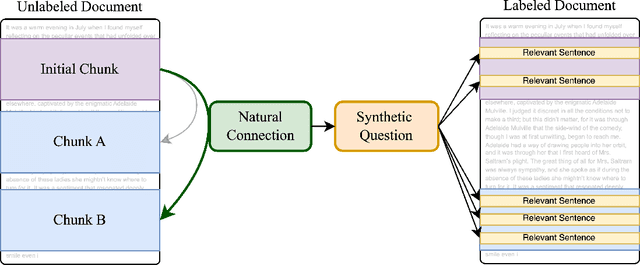
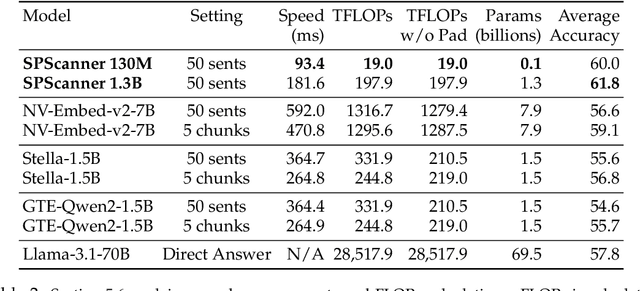
Handling extremely large documents for question answering is challenging: chunk-based embedding methods often lose track of important global context, while full-context transformers can be prohibitively expensive for hundreds of thousands of tokens. We propose a single-pass document scanning approach that processes the entire text in linear time, preserving global coherence while deciding which sentences are most relevant to the query. On 41 QA benchmarks, our single-pass scanner consistently outperforms chunk-based embedding methods and competes with large language models at a fraction of the computational cost. By conditioning on the entire preceding context without chunk breaks, the method preserves global coherence, which is especially important for long documents. Overall, single-pass document scanning offers a simple solution for question answering over massive text. All code, datasets, and model checkpoints are available at https://github.com/MambaRetriever/MambaRetriever
Measuring Risk of Bias in Biomedical Reports: The RoBBR Benchmark
Nov 28, 2024



Systems that answer questions by reviewing the scientific literature are becoming increasingly feasible. To draw reliable conclusions, these systems should take into account the quality of available evidence, placing more weight on studies that use a valid methodology. We present a benchmark for measuring the methodological strength of biomedical papers, drawing on the risk-of-bias framework used for systematic reviews. The four benchmark tasks, drawn from more than 500 papers, cover the analysis of research study methodology, followed by evaluation of risk of bias in these studies. The benchmark contains 2000 expert-generated bias annotations, and a human-validated pipeline for fine-grained alignment with research paper content. We evaluate a range of large language models on the benchmark, and find that these models fall significantly short of expert-level performance. By providing a standardized tool for measuring judgments of study quality, the benchmark can help to guide systems that perform large-scale aggregation of scientific data. The dataset is available at https://github.com/RoBBR-Benchmark/RoBBR.
Adapting While Learning: Grounding LLMs for Scientific Problems with Intelligent Tool Usage Adaptation
Nov 01, 2024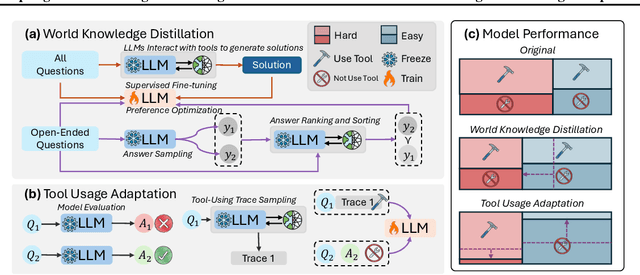
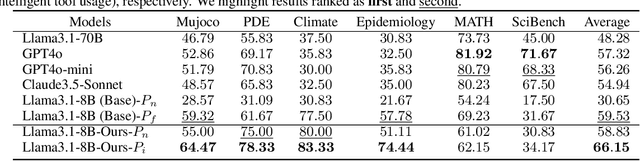
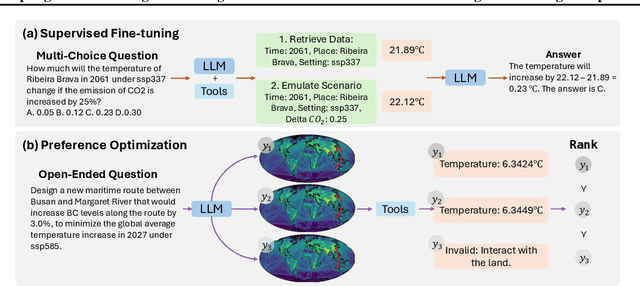
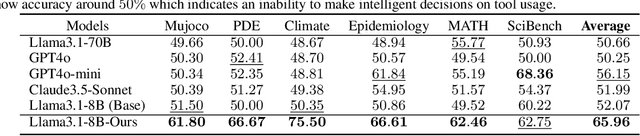
Large Language Models (LLMs) demonstrate promising capabilities in solving simple scientific problems but often produce hallucinations for complex ones. While integrating LLMs with tools can increase reliability, this approach typically results in over-reliance on tools, diminishing the model's ability to solve simple problems through basic reasoning. In contrast, human experts first assess problem complexity using domain knowledge before choosing an appropriate solution approach. Inspired by this human problem-solving process, we propose a novel two-component fine-tuning method. In the first component World Knowledge Distillation (WKD), LLMs learn directly from solutions generated using tool's information to internalize domain knowledge. In the second component Tool Usage Adaptation (TUA), we partition problems into easy and hard categories based on the model's direct answering accuracy. While maintaining the same alignment target for easy problems as in WKD, we train the model to intelligently switch to tool usage for more challenging problems. We validate our method on six scientific benchmark datasets, spanning mathematics, climate science and epidemiology. On average, our models demonstrate a 28.18% improvement in answer accuracy and a 13.89% increase in tool usage precision across all datasets, surpassing state-of-the-art models including GPT-4o and Claude-3.5.
ClimaQA: An Automated Evaluation Framework for Climate Foundation Models
Oct 22, 2024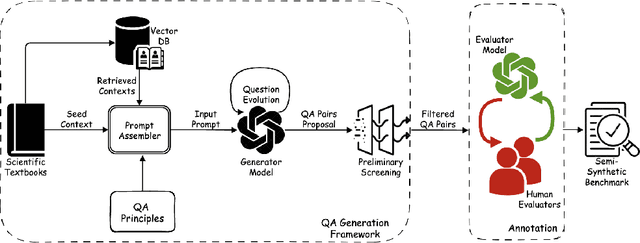
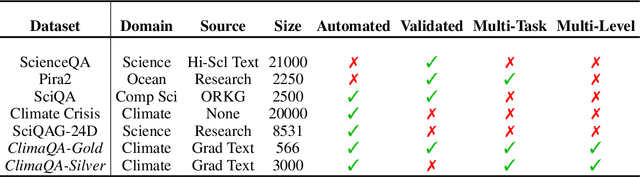

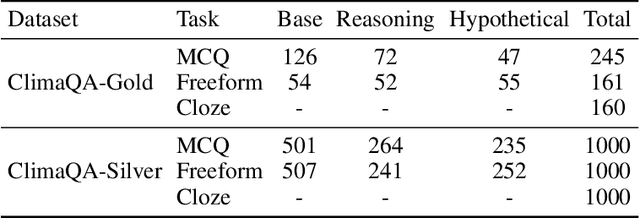
The use of foundation models in climate science has recently gained significant attention. However, a critical issue remains: the lack of a comprehensive evaluation framework capable of assessing the quality and scientific validity of model outputs. To address this issue, we develop ClimaGen (Climate QA Generator), an automated algorithmic framework that generates question-answer pairs from graduate textbooks with climate scientists in the loop. As a result, we present ClimaQA-Gold, an expert-annotated benchmark dataset alongside ClimaQA-Silver, a large-scale, comprehensive synthetic QA dataset for climate science. Finally, we develop evaluation strategies and compare different Large Language Models (LLMs) on our benchmarks. Our results offer novel insights into various approaches used to enhance climate foundation models.
Dissociation of Faithful and Unfaithful Reasoning in LLMs
May 23, 2024



Large language models (LLMs) improve their performance in downstream tasks when they generate Chain of Thought reasoning text before producing an answer. Our research investigates how LLMs recover from errors in Chain of Thought, reaching the correct final answer despite mistakes in the reasoning text. Through analysis of these error recovery behaviors, we find evidence for unfaithfulness in Chain of Thought, but we also identify many clear examples of faithful error recovery behaviors. We identify factors that shift LLM recovery behavior: LLMs recover more frequently from obvious errors and in contexts that provide more evidence for the correct answer. However, unfaithful recoveries show the opposite behavior, occurring more frequently for more difficult error positions. Our results indicate that there are distinct mechanisms driving faithful and unfaithful error recoveries. Our results challenge the view that LLM reasoning is a uniform, coherent process.
IR2: Information Regularization for Information Retrieval
Feb 25, 2024



Effective information retrieval (IR) in settings with limited training data, particularly for complex queries, remains a challenging task. This paper introduces IR2, Information Regularization for Information Retrieval, a technique for reducing overfitting during synthetic data generation. This approach, representing a novel application of regularization techniques in synthetic data creation for IR, is tested on three recent IR tasks characterized by complex queries: DORIS-MAE, ArguAna, and WhatsThatBook. Experimental results indicate that our regularization techniques not only outperform previous synthetic query generation methods on the tasks considered but also reduce cost by up to 50%. Furthermore, this paper categorizes and explores three regularization methods at different stages of the query synthesis pipeline-input, prompt, and output-each offering varying degrees of performance improvement compared to models where no regularization is applied. This provides a systematic approach for optimizing synthetic data generation in data-limited, complex-query IR scenarios. All code, prompts and synthetic data are available at https://github.com/Info-Regularization/Information-Regularization.
BIRCO: A Benchmark of Information Retrieval Tasks with Complex Objectives
Feb 21, 2024We present the Benchmark of Information Retrieval (IR) tasks with Complex Objectives (BIRCO). BIRCO evaluates the ability of IR systems to retrieve documents given multi-faceted user objectives. The benchmark's complexity and compact size make it suitable for evaluating large language model (LLM)-based information retrieval systems. We present a modular framework for investigating factors that may influence LLM performance on retrieval tasks, and identify a simple baseline model which matches or outperforms existing approaches and more complex alternatives. No approach achieves satisfactory performance on all benchmark tasks, suggesting that stronger models and new retrieval protocols are necessary to address complex user needs.