 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effects of Data Scale on Computer Control Agents
Jun 06, 2024
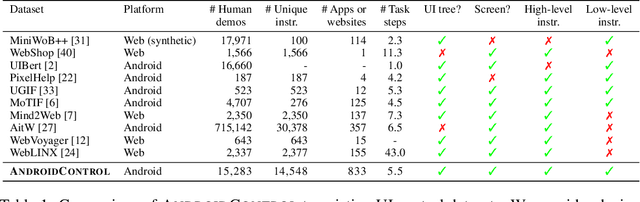
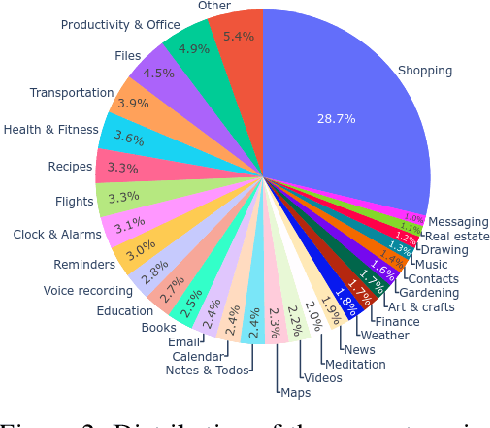

Autonomous agents that control computer interfaces to accomplish human tasks are emerging. Leveraging LLMs to power such agents has been of special interest, but unless fine-tuned on human-collected task demonstrations, performance is still relatively low. In this work we study whether fine-tuning alone is a viable approach for building real-world computer control agents. %In particularly, we investigate how performance measured on both high and low-level tasks in domain and out of domain scales as more training data is collected. To this end we collect and release a new dataset, AndroidControl, consisting of 15,283 demonstrations of everyday tasks with Android apps. Compared to existing datasets, each AndroidControl task instance includes both high and low-level human-generated instructions, allowing us to explore the level of task complexity an agent can handle. Moreover, AndroidControl is the most diverse computer control dataset to date, including 15,283 unique tasks over 833 Android apps, thus allowing us to conduct in-depth analysis of the model performance in and out of the domain of the training data. Using the dataset, we find that when tested in domain fine-tuned models outperform zero and few-shot baselines and scale in such a way that robust performance might feasibly be obtained simply by collecting more data. Out of domain, performance scales significantly more slowly and suggests that in particular for high-level tasks, fine-tuning on more data alone may be insufficient for achieving robust out-of-domain performance.
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
May 23, 2024



Autonomous agents that execute human tasks by controlling computers can enhance human productivity and application accessibility. Yet, progress in this field will be driven by realistic and reproducible benchmarks. We present AndroidWorld, a fully functioning Android environment that provides reward signals for 116 programmatic task workflows across 20 real world Android applications. Unlike existing interactive environments, which provide a static test set, AndroidWorld dynamically constructs tasks that are parameterized and expressed in natural language in unlimited ways, thus enabling testing on a much larger and realistic suite of tasks. Reward signals are derived from the computer's system state, making them durable across task variations and extensible across different apps. To demonstrate AndroidWorld's benefits and mode of operation, we introduce a new computer control agent, M3A. M3A can complete 30.6% of the AndroidWorld's tasks, leaving ample room for future work. Furthermore, we adapt a popular desktop web agent to work on Android, which we find to be less effective on mobile, suggesting future research is needed to achieve universal, cross-domain agents. Finally, we conduct a robustness analysis by testing M3A against a range of task variations on a representative subset of tasks, demonstrating that variations in task parameters can significantly alter the complexity of a task and therefore an agent's performance, highlighting the importance of testing agents under diverse conditions. AndroidWorld and the experiments in this paper are available at https://github.com/google-research/android_world.
Dissociation of Faithful and Unfaithful Reasoning in LLMs
May 23, 2024



Large language models (LLMs) improve their performance in downstream tasks when they generate Chain of Thought reasoning text before producing an answer. Our research investigates how LLMs recover from errors in Chain of Thought, reaching the correct final answer despite mistakes in the reasoning text. Through analysis of these error recovery behaviors, we find evidence for unfaithfulness in Chain of Thought, but we also identify many clear examples of faithful error recovery behaviors. We identify factors that shift LLM recovery behavior: LLMs recover more frequently from obvious errors and in contexts that provide more evidence for the correct answer. However, unfaithful recoveries show the opposite behavior, occurring more frequently for more difficult error positions. Our results indicate that there are distinct mechanisms driving faithful and unfaithful error recoveries. Our results challenge the view that LLM reasoning is a uniform, coherent process.
Generative AI Search Engines as Arbiters of Public Knowledge: An Audit of Bias and Authority
May 22, 2024This paper reports on an audit study of generative AI systems (ChatGPT, Bing Chat, and Perplexity) which investigates how these new search engines construct responses and establish authority for topics of public importance. We collected system responses using a set of 48 authentic queries for 4 topics over a 7-day period and analyzed the data using sentiment analysis, inductive coding and source classification. Results provide an overview of the nature of system responses across these systems and provide evidence of sentiment bias based on the queries and topics, and commercial and geographic bias in sources. The quality of sources used to support claims is uneven, relying heavily on News and Media, Business and Digital Media websites. Implications for system users emphasize the need to critically examine Generative AI system outputs when making decisions related to public interest and personal well-being.
Latent State Estimation Helps UI Agents to Reason
May 17, 2024



A common problem for agents operating in real-world environments is that the response of an environment to their actions may be non-deterministic and observed through noise. This renders environmental state and progress towards completing a task latent. Despite recent impressive demonstrations of LLM's reasoning abilities on various benchmarks, whether LLMs can build estimates of latent state and leverage them for reasoning has not been explicitly studied. We investigate this problem in the real-world domain of autonomous UI agents. We establish that appropriately prompting LLMs in a zero-shot manner can be formally understood as forming point estimates of latent state in a textual space. In the context of autonomous UI agents we then show that LLMs used in this manner are more than $76\%$ accurate at inferring various aspects of latent state, such as performed (vs. commanded) actions and task progression. Using both public and internal benchmarks and three reasoning methods (zero-shot, CoT-SC & ReAct), we show that LLM-powered agents that explicitly estimate and reason about latent state are able to successfully complete up to 1.6x more tasks than those that do not.
Android in the Wild: A Large-Scale Dataset for Android Device Control
Jul 19, 2023



There is a growing interest in device-control systems that can interpret human natural language instructions and execute them on a digital device by directly controlling its user interface. We present a dataset for device-control research, Android in the Wild (AITW), which is orders of magnitude larger than current datasets. The dataset contains human demonstrations of device interactions, including the screens and actions, and corresponding natural language instructions. It consists of 715k episodes spanning 30k unique instructions, four versions of Android (v10-13),and eight device types (Pixel 2 XL to Pixel 6) with varying screen resolutions. It contains multi-step tasks that require semantic understanding of language and visual context. This dataset poses a new challenge: actions available through the user interface must be inferred from their visual appearance. And, instead of simple UI element-based actions, the action space consists of precise gestures (e.g., horizontal scrolls to operate carousel widgets). We organize our dataset to encourage robustness analysis of device-control systems, i.e., how well a system performs in the presence of new task descriptions, new applications, or new platform versions. We develop two agents and report performance across the dataset. The dataset is available at https://github.com/google-research/google-research/tree/master/android_in_the_wild.
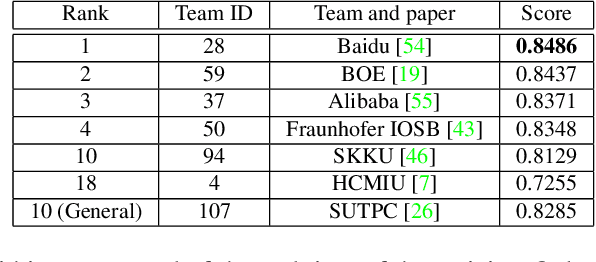
The 7th AI City Challenge
Apr 15, 2023
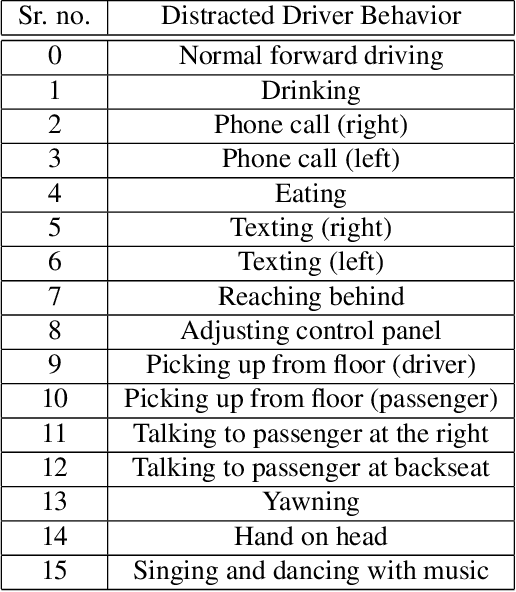

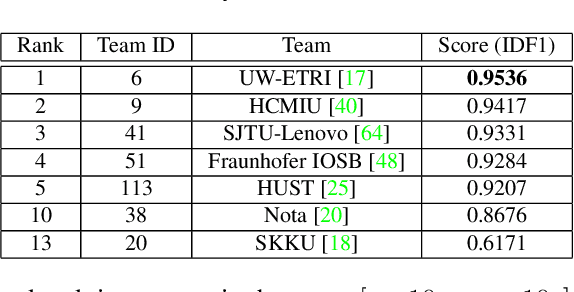
The AI City Challenge's seventh edition emphasizes two domains at the intersection of computer vision and artificial intelligence - retail business and Intelligent Traffic Systems (ITS) - that have considerable untapped potential. The 2023 challenge had five tracks, which drew a record-breaking number of participation requests from 508 teams across 46 countries. Track 1 was a brand new track that focused on multi-target multi-camera (MTMC) people tracking, where teams trained and evaluated using both real and highly realistic synthetic data. Track 2 centered around natural-language-based vehicle track retrieval. Track 3 required teams to classify driver actions in naturalistic driving analysis. Track 4 aimed to develop an automated checkout system for retail stores using a single view camera. Track 5, another new addition, tasked teams with detecting violations of the helmet rule for motorcyclists. Two leader boards were released for submissions based on different methods: a public leader board for the contest where external private data wasn't allowed and a general leader board for all results submitted. The participating teams' top performances established strong baselines and even outperformed the state-of-the-art in the proposed challenge tracks.
Productivity Assessment of Neural Code Completion
May 13, 2022



Neural code synthesis has reached a point where snippet generation is accurate enough to be considered for integration into human software development workflows. Commercial products aim to increase programmers' productivity, without being able to measure it directly. In this case study, we asked users of GitHub Copilot about its impact on their productivity, and sought to find a reflection of their perception in directly measurable user data. We find that the rate with which shown suggestions are accepted, rather than more specific metrics regarding the persistence of completions in the code over time, drives developers' perception of productivity.
The 6th AI City Challenge
Apr 21, 2022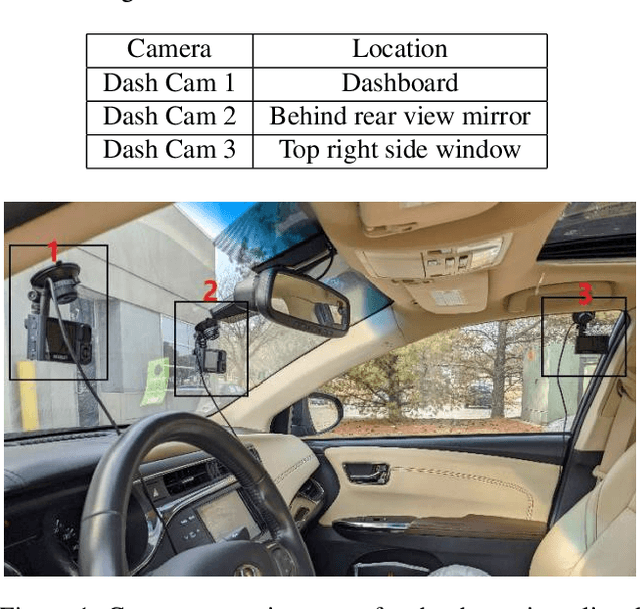
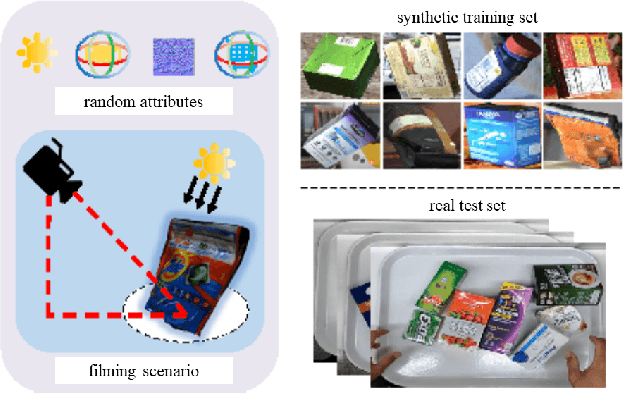
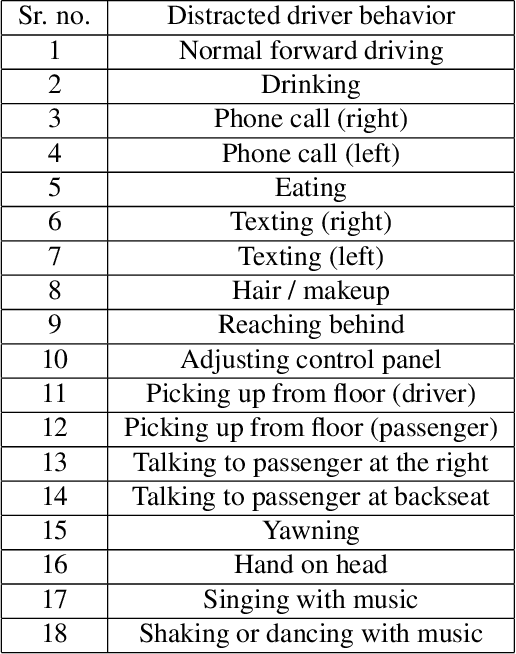
The 6th edition of the AI City Challenge specifically focuses on problems in two domains where there is tremendous unlocked potential at the intersection of computer vision and artificial intelligence: Intelligent Traffic Systems (ITS), and brick and mortar retail businesses. The four challenge tracks of the 2022 AI City Challenge received participation requests from 254 teams across 27 countries. Track 1 addressed city-scale multi-target multi-camera (MTMC) vehicle tracking. Track 2 addressed natural-language-based vehicle track retrieval. Track 3 was a brand new track for naturalistic driving analysis, where the data were captured by several cameras mounted inside the vehicle focusing on driver safety, and the task was to classify driver actions. Track 4 was another new track aiming to achieve retail store automated checkout using only a single view camera. We released two leader boards for submissions based on different methods, including a public leader board for the contest, where no use of external data is allowed, and a general leader board for all submitted results. The top performance of participating teams established strong baselines and even outperformed the state-of-the-art in the proposed challenge tracks.