 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Explainable Multi-Task Similarity Measure: Integrating Accumulated Local Effects and Weighted Fréchet Distance
Feb 08, 2026In many machine learning contexts, tasks are often treated as interconnected components with the goal of leveraging knowledge transfer between them, which is the central aim of Multi-Task Learning (MTL). Consequently, this multi-task scenario requires addressing critical questions: which tasks are similar, and how and why do they exhibit similarity? In this work, we propose a multi-task similarity measure based on Explainable Artificial Intelligence (XAI) techniques, specifically Accumulated Local Effects (ALE) curves. ALE curves are compared using the Fréchet distance, weighted by the data distribution, and the resulting similarity measure incorporates the importance of each feature. The measure is applicable in both single-task learning scenarios, where each task is trained separately, and multi-task learning scenarios, where all tasks are learned simultaneously. The measure is model-agnostic, allowing the use of different machine learning models across tasks. A scaling factor is introduced to account for differences in predictive performance across tasks, and several recommendations are provided for applying the measure in complex scenarios. We validate this measure using four datasets, one synthetic dataset and three real-world datasets. The real-world datasets include a well-known Parkinson's dataset and a bike-sharing usage dataset -- both structured in tabular format -- as well as the CelebA dataset, which is used to evaluate the application of concept bottleneck encoders in a multitask learning setting. The results demonstrate that the measure aligns with intuitive expectations of task similarity across both tabular and non-tabular data, making it a valuable tool for exploring relationships between tasks and supporting informed decision-making.
The challenge of generating and evolving real-life like synthetic test data without accessing real-world raw data -- a Systematic Review
Feb 06, 2026Background: High-level system testing of applications that use data from e-Government services as input requires test data that is real-life-like but where the privacy of personal information is guaranteed. Applications with such strong requirement include information exchange between countries, medicine, banking, etc. This review aims to synthesize the current state-of-the-practice in this domain. Objectives: The objective of this Systematic Review is to identify existing approaches for creating and evolving synthetic test data without using real-life raw data. Methods: We followed well-known methodologies for conducting systematic literature reviews, including the ones from Kitchenham as well as guidelines for analysing the limitations of our review and its threats to validity. Results: A variety of methods and tools exist for creating privacy-preserving test data. Our search found 1,013 publications in IEEE Xplore, ACM Digital Library, and SCOPUS. We extracted data from 75 of those publications and identified 37 approaches that answer our research question partly. A common prerequisite for using these methods and tools is direct access to real-life data for data anonymization or synthetic test data generation. Nine existing synthetic test data generation approaches were identified that were closest to answering our research question. Nevertheless, further work would be needed to add the ability to evolve synthetic test data to the existing approaches. Conclusions: None of the publications really covered our requirements completely, only partially. Synthetic test data evolution is a field that has not received much attention from researchers but needs to be explored in Digital Government Solutions, especially since new legal regulations are being placed in force in many countries.
* 22 pages
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Android in the Wild: A Large-Scale Dataset for Android Device Control
Jul 19, 2023



There is a growing interest in device-control systems that can interpret human natural language instructions and execute them on a digital device by directly controlling its user interface. We present a dataset for device-control research, Android in the Wild (AITW), which is orders of magnitude larger than current datasets. The dataset contains human demonstrations of device interactions, including the screens and actions, and corresponding natural language instructions. It consists of 715k episodes spanning 30k unique instructions, four versions of Android (v10-13),and eight device types (Pixel 2 XL to Pixel 6) with varying screen resolutions. It contains multi-step tasks that require semantic understanding of language and visual context. This dataset poses a new challenge: actions available through the user interface must be inferred from their visual appearance. And, instead of simple UI element-based actions, the action space consists of precise gestures (e.g., horizontal scrolls to operate carousel widgets). We organize our dataset to encourage robustness analysis of device-control systems, i.e., how well a system performs in the presence of new task descriptions, new applications, or new platform versions. We develop two agents and report performance across the dataset. The dataset is available at https://github.com/google-research/google-research/tree/master/android_in_the_wild.
Software defect prediction with zero-inflated Poisson models
Oct 30, 2019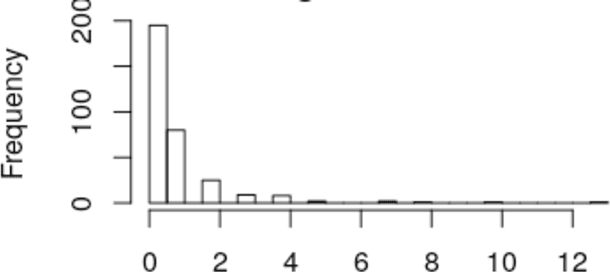
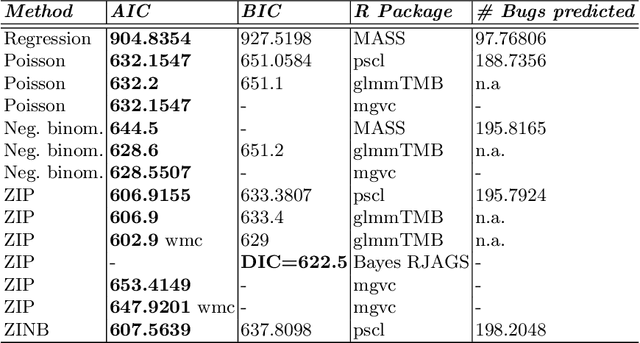
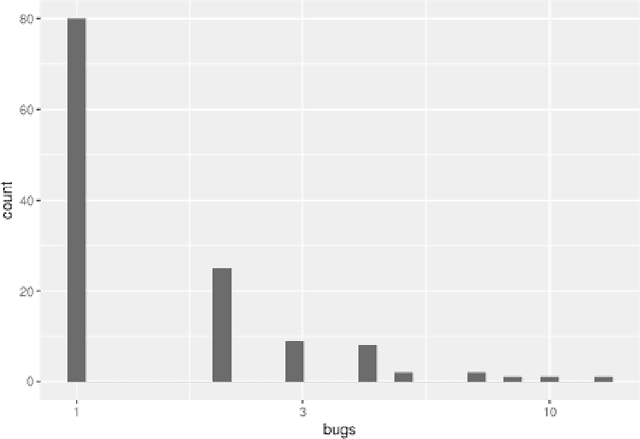
In this work we apply several Poisson and zero-inflated models for software defect prediction. We apply different functions from several R packages such as pscl, MASS, R2Jags and the recent glmmTMB. We test the functions using the Equinox dataset. The results show that Zero-inflated models, fitted with either maximum likelihood estimation or with Bayesian approach, are slightly better than other models, using the AIC as selection criterion.
Distributed Correlation-Based Feature Selection in Spark
Jan 31, 2019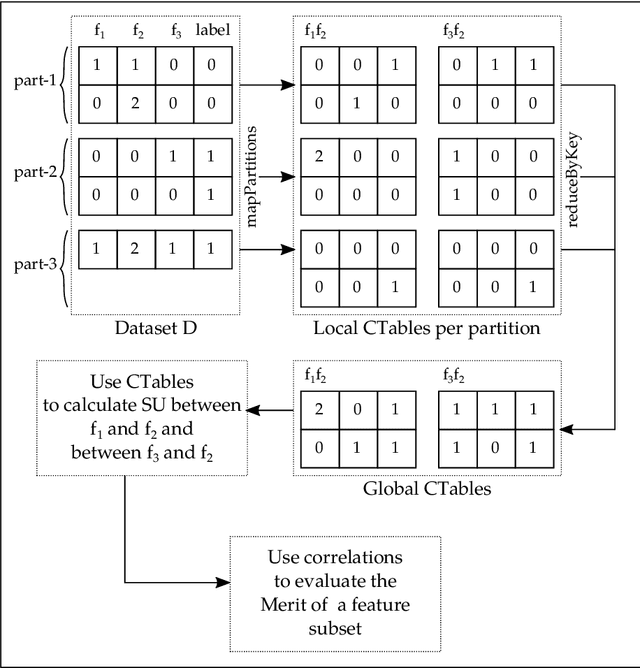
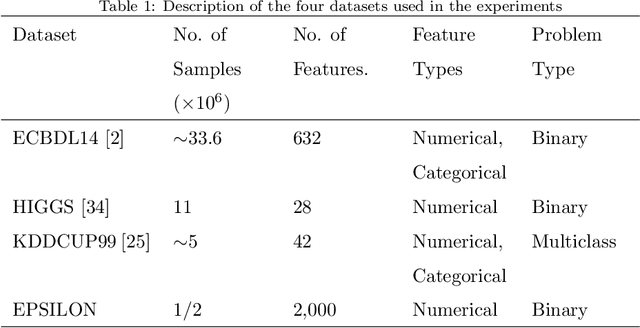
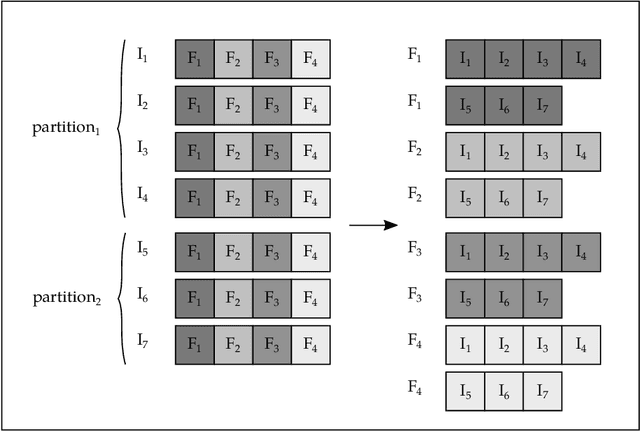
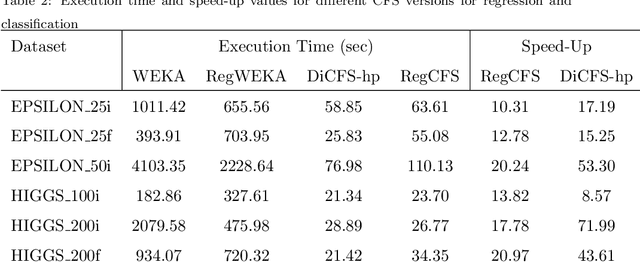
CFS (Correlation-Based Feature Selection) is an FS algorithm that has been successfully applied to classification problems in many domains. We describe Distributed CFS (DiCFS) as a completely redesigned, scalable, parallel and distributed version of the CFS algorithm, capable of dealing with the large volumes of data typical of big data applications. Two versions of the algorithm were implemented and compared using the Apache Spark cluster computing model, currently gaining popularity due to its much faster processing times than Hadoop's MapReduce model. We tested our algorithms on four publicly available datasets, each consisting of a large number of instances and two also consisting of a large number of features. The results show that our algorithms were superior in terms of both time-efficiency and scalability. In leveraging a computer cluster, they were able to handle larger datasets than the non-distributed WEKA version while maintaining the quality of the results, i.e., exactly the same features were returned by our algorithms when compared to the original algorithm available in WEKA.
Snorkel DryBell: A Case Study in Deploying Weak Supervision at Industrial Scale
Dec 02, 2018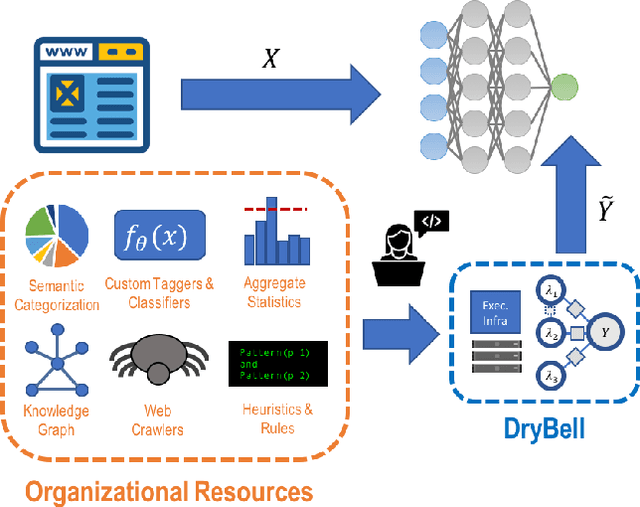

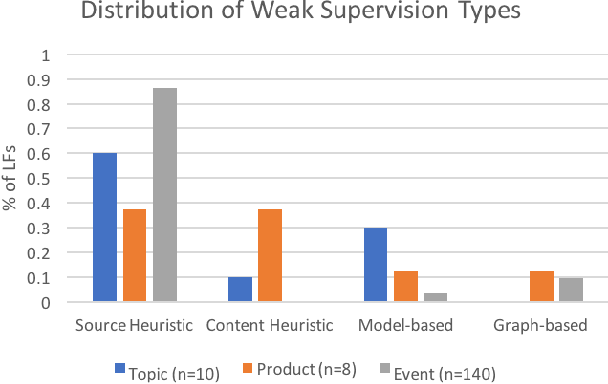

Labeling training data is one of the most costly bottlenecks in developing or modifying machine learning-based applications. We survey how resources from across an organization can be used as weak supervision sources for three classification tasks at Google, in order to bring development time and cost down by an order of magnitude. We build on the Snorkel framework, extending it as a new system, Snorkel DryBell, which integrates with Google's distributed production systems and enables engineers to develop and execute weak supervision strategies over millions of examples in less than thirty minutes. We find that Snorkel DryBell creates classifiers of comparable quality to ones trained using up to tens of thousands of hand-labeled examples, in part by leveraging organizational resources not servable in production which contribute an average 52% performance improvement to the weakly supervised classifiers.
Distributed ReliefF based Feature Selection in Spark
Nov 01, 2018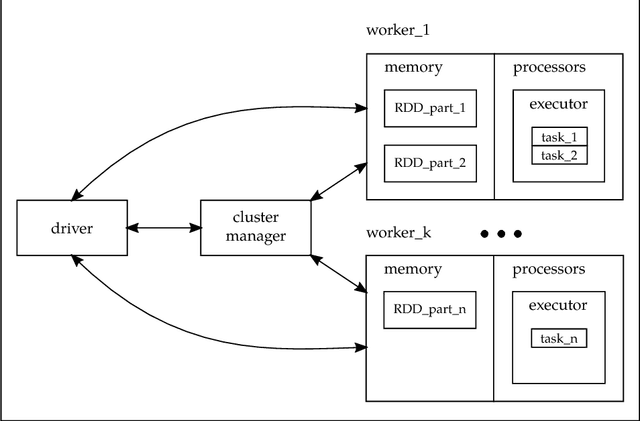
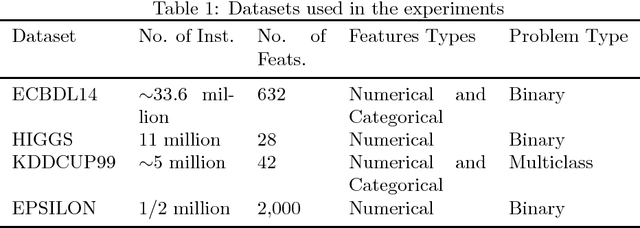
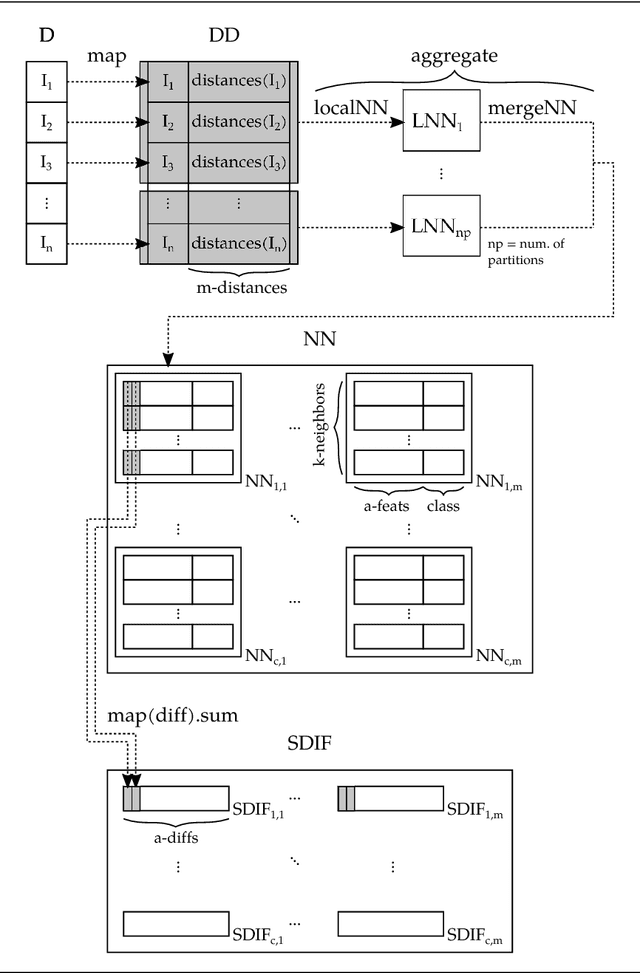
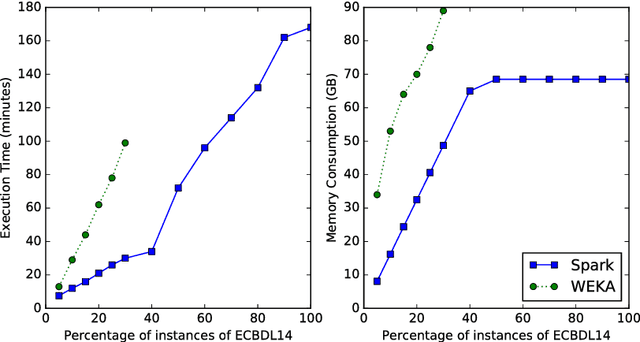
Feature selection (FS) is a key research area in the machine learning and data mining fields, removing irrelevant and redundant features usually helps to reduce the effort required to process a dataset while maintaining or even improving the processing algorithm's accuracy. However, traditional algorithms designed for executing on a single machine lack scalability to deal with the increasing amount of data that has become available in the current Big Data era. ReliefF is one of the most important algorithms successfully implemented in many FS applications. In this paper, we present a completely redesigned distributed version of the popular ReliefF algorithm based on the novel Spark cluster computing model that we have called DiReliefF. Spark is increasing its popularity due to its much faster processing times compared with Hadoop's MapReduce model implementation. The effectiveness of our proposal is tested on four publicly available datasets, all of them with a large number of instances and two of them with also a large number of features. Subsets of these datasets were also used to compare the results to a non-distributed implementation of the algorithm. The results show that the non-distributed implementation is unable to handle such large volumes of data without specialized hardware, while our design can process them in a scalable way with much better processing times and memory usage.
Merge Non-Dominated Sorting Algorithm for Many-Objective Optimization
Sep 17, 2018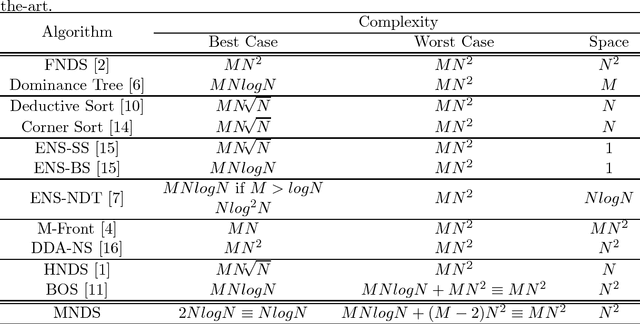
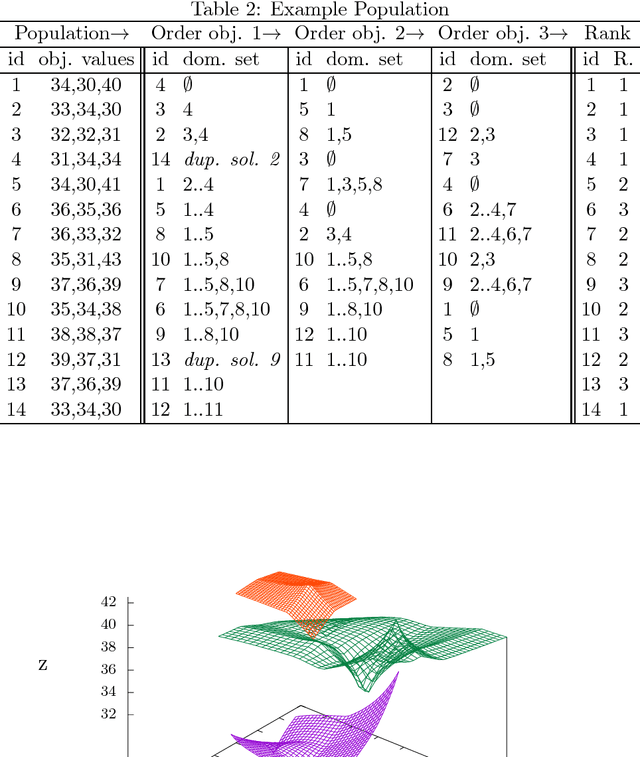
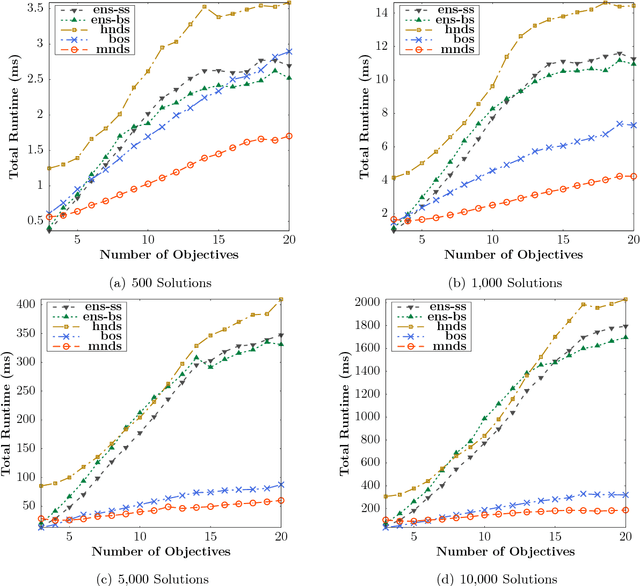
Many Pareto-based multi-objective evolutionary algorithms require to rank the solutions of the population in each iteration according to the dominance principle, what can become a costly operation particularly in the case of dealing with many-objective optimization problems. In this paper, we present a new efficient algorithm for computing the non-dominated sorting procedure, called Merge Non-Dominated Sorting (MNDS), which has a best computational complexity of $\Theta(NlogN)$ and a worst computational complexity of $\Theta(MN^2)$. Our approach is based on the computation of the dominance set of each solution by taking advantage of the characteristics of the merge sort algorithm. We compare the MNDS against four well-known techniques that can be considered as the state-of-the-art. The results indicate that the MNDS algorithm outperforms the other techniques in terms of number of comparisons as well as the total running time.