 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheMCPCompany: Creating General-purpose Agents with Task-specific Tools
Oct 22, 2025Since the introduction of the Model Context Protocol (MCP), the number of available tools for Large Language Models (LLMs) has increased significantly. These task-specific tool sets offer an alternative to general-purpose tools such as web browsers, while being easier to develop and maintain than GUIs. However, current general-purpose agents predominantly rely on web browsers for interacting with the environment. Here, we introduce TheMCPCompany, a benchmark for evaluating tool-calling agents on tasks that involve interacting with various real-world services. We use the REST APIs of these services to create MCP servers, which include over 18,000 tools. We also provide manually annotated ground-truth tools for each task. In our experiments, we use the ground truth tools to show the potential of tool-calling agents for both improving performance and reducing costs assuming perfect tool retrieval. Next, we explore agent performance using tool retrieval to study the real-world practicality of tool-based agents. While all models with tool retrieval perform similarly or better than browser-based agents, smaller models cannot take full advantage of the available tools through retrieval. On the other hand, GPT-5's performance with tool retrieval is very close to its performance with ground-truth tools. Overall, our work shows that the most advanced reasoning models are effective at discovering tools in simpler environments, but seriously struggle with navigating complex enterprise environments. TheMCPCompany reveals that navigating tens of thousands of tools and combining them in non-trivial ways to solve complex problems is still a challenging task for current models and requires both better reasoning and better retrieval models.
Can We Predict Alignment Before Models Finish Thinking? Towards Monitoring Misaligned Reasoning Models
Jul 16, 2025Open-weights reasoning language models generate long chains-of-thought (CoTs) before producing a final response, which improves performance but introduces additional alignment risks, with harmful content often appearing in both the CoTs and the final outputs. In this work, we investigate if we can use CoTs to predict final response misalignment. We evaluate a range of monitoring approaches, including humans, highly-capable large language models, and text classifiers, using either CoT text or activations. First, we find that a simple linear probe trained on CoT activations can significantly outperform all text-based methods in predicting whether a final response will be safe or unsafe. CoT texts are often unfaithful and can mislead humans and classifiers, while model latents (i.e., CoT activations) offer a more reliable predictive signal. Second, the probe makes accurate predictions before reasoning completes, achieving strong performance even when applied to early CoT segments. These findings generalize across model sizes, families, and safety benchmarks, suggesting that lightweight probes could enable real-time safety monitoring and early intervention during generation.
The State of Multilingual LLM Safety Research: From Measuring the Language Gap to Mitigating It
May 30, 2025This paper presents a comprehensive analysis of the linguistic diversity of LLM safety research, highlighting the English-centric nature of the field. Through a systematic review of nearly 300 publications from 2020--2024 across major NLP conferences and workshops at *ACL, we identify a significant and growing language gap in LLM safety research, with even high-resource non-English languages receiving minimal attention. We further observe that non-English languages are rarely studied as a standalone language and that English safety research exhibits poor language documentation practice. To motivate future research into multilingual safety, we make several recommendations based on our survey, and we then pose three concrete future directions on safety evaluation, training data generation, and crosslingual safety generalization. Based on our survey and proposed directions, the field can develop more robust, inclusive AI safety practices for diverse global populations.
Crosslingual Reasoning through Test-Time Scaling
May 08, 2025Reasoning capabilities of large language models are primarily studied for English, even when pretrained models are multilingual. In this work, we investigate to what extent English reasoning finetuning with long chain-of-thoughts (CoTs) can generalize across languages. First, we find that scaling up inference compute for English-centric reasoning language models (RLMs) improves multilingual mathematical reasoning across many languages including low-resource languages, to an extent where they outperform models twice their size. Second, we reveal that while English-centric RLM's CoTs are naturally predominantly English, they consistently follow a quote-and-think pattern to reason about quoted non-English inputs. Third, we discover an effective strategy to control the language of long CoT reasoning, and we observe that models reason better and more efficiently in high-resource languages. Finally, we observe poor out-of-domain reasoning generalization, in particular from STEM to cultural commonsense knowledge, even for English. Overall, we demonstrate the potentials, study the mechanisms and outline the limitations of crosslingual generalization of English reasoning test-time scaling. We conclude that practitioners should let English-centric RLMs reason in high-resource languages, while further work is needed to improve reasoning in low-resource languages and out-of-domain contexts.
Beyond Contrastive Learning: Synthetic Data Enables List-wise Training with Multiple Levels of Relevance
Mar 29, 2025Recent advancements in large language models (LLMs) have allowed the augmentation of information retrieval (IR) pipelines with synthetic data in various ways. Yet, the main training paradigm remains: contrastive learning with binary relevance labels and the InfoNCE loss, where one positive document is compared against one or more negatives. This objective treats all documents that are not explicitly annotated as relevant on an equally negative footing, regardless of their actual degree of relevance, thus (a) missing subtle nuances that are useful for ranking and (b) being susceptible to annotation noise. To overcome this limitation, in this work we forgo real training documents and annotations altogether and use open-source LLMs to directly generate synthetic documents that answer real user queries according to several different levels of relevance. This fully synthetic ranking context of graduated relevance, together with an appropriate list-wise loss (Wasserstein distance), enables us to train dense retrievers in a way that better captures the ranking task. Experiments on various IR datasets show that our proposed approach outperforms conventional training with InfoNCE by a large margin. Without using any real documents for training, our dense retriever significantly outperforms the same retriever trained through self-supervision. More importantly, it matches the performance of the same retriever trained on real, labeled training documents of the same dataset, while being more robust to distribution shift and clearly outperforming it when evaluated zero-shot on the BEIR dataset collection.
K-Paths: Reasoning over Graph Paths for Drug Repurposing and Drug Interaction Prediction
Feb 18, 2025Drug discovery is a complex and time-intensive process that requires identifying and validating new therapeutic candidates. Computational approaches using large-scale biomedical knowledge graphs (KGs) offer a promising solution to accelerate this process. However, extracting meaningful insights from large-scale KGs remains challenging due to the complexity of graph traversal. Existing subgraph-based methods are tailored to graph neural networks (GNNs), making them incompatible with other models, such as large language models (LLMs). We introduce K-Paths, a retrieval framework that extracts structured, diverse, and biologically meaningful paths from KGs. Integrating these paths enables LLMs and GNNs to effectively predict unobserved drug-drug and drug-disease interactions. Unlike traditional path-ranking approaches, K-Paths retrieves and transforms paths into a structured format that LLMs can directly process, facilitating explainable reasoning. K-Paths employs a diversity-aware adaptation of Yen's algorithm to retrieve the K shortest loopless paths between entities in an interaction query, prioritizing biologically relevant and diverse relationships. Our experiments on benchmark datasets show that K-Paths improves the zero-shot performance of Llama 8.1B's F1-score by 12.45 points on drug repurposing and 13.42 points on interaction severity prediction. We also show that Llama 70B achieves F1-score gains of 6.18 and 8.46 points, respectively. K-Paths also improves the supervised training efficiency of EmerGNN, a state-of-the-art GNN, by reducing KG size by 90% while maintaining strong predictive performance. Beyond its scalability and efficiency, K-Paths uniquely bridges the gap between KGs and LLMs, providing explainable rationales for predicted interactions. These capabilities show that K-Paths is a valuable tool for efficient data-driven drug discovery.
$100K or 100 Days: Trade-offs when Pre-Training with Academic Resources
Oct 30, 2024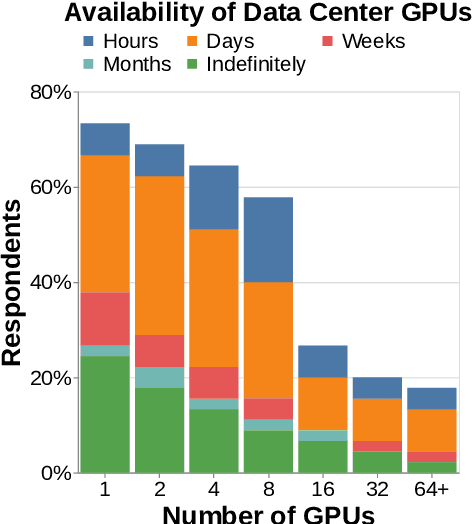
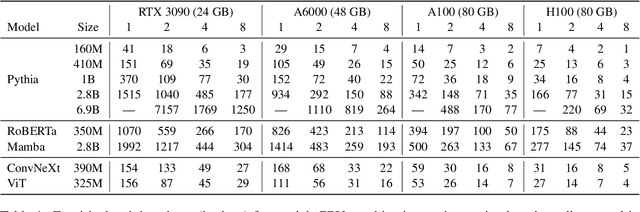
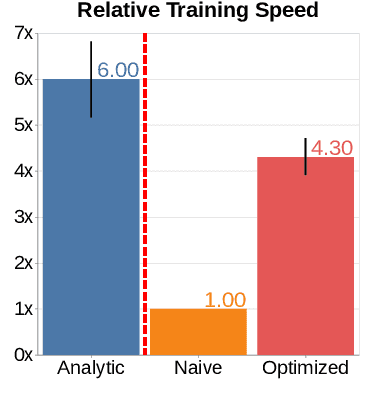
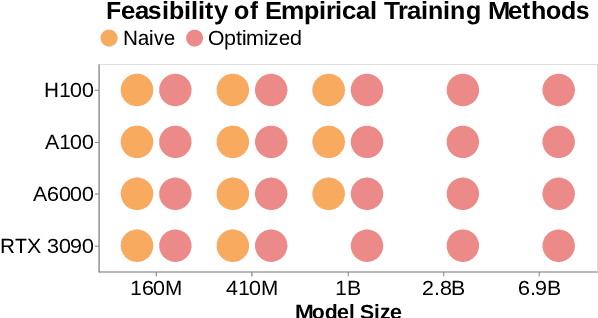
Pre-training is notoriously compute-intensive and academic researchers are notoriously under-resourced. It is, therefore, commonly assumed that academics can't pre-train models. In this paper, we seek to clarify this assumption. We first survey academic researchers to learn about their available compute and then empirically measure the time to replicate models on such resources. We introduce a benchmark to measure the time to pre-train models on given GPUs and also identify ideal settings for maximizing training speed. We run our benchmark on a range of models and academic GPUs, spending 2,000 GPU-hours on our experiments. Our results reveal a brighter picture for academic pre-training: for example, although Pythia-1B was originally trained on 64 GPUs for 3 days, we find it is also possible to replicate this model (with the same hyper-parameters) in 3x fewer GPU-days: i.e. on 4 GPUs in 18 days. We conclude with a cost-benefit analysis to help clarify the trade-offs between price and pre-training time. We believe our benchmark will help academic researchers conduct experiments that require training larger models on more data. We fully release our codebase at: https://github.com/apoorvkh/academic-pretraining.
Planetarium: A Rigorous Benchmark for Translating Text to Structured Planning Languages
Jul 03, 2024



Many recent works have explored using language models for planning problems. One line of research focuses on translating natural language descriptions of planning tasks into structured planning languages, such as the planning domain definition language (PDDL). While this approach is promising, accurately measuring the quality of generated PDDL code continues to pose significant challenges. First, generated PDDL code is typically evaluated using planning validators that check whether the problem can be solved with a planner. This method is insufficient because a language model might generate valid PDDL code that does not align with the natural language description of the task. Second, existing evaluation sets often have natural language descriptions of the planning task that closely resemble the ground truth PDDL, reducing the challenge of the task. To bridge this gap, we introduce \benchmarkName, a benchmark designed to evaluate language models' ability to generate PDDL code from natural language descriptions of planning tasks. We begin by creating a PDDL equivalence algorithm that rigorously evaluates the correctness of PDDL code generated by language models by flexibly comparing it against a ground truth PDDL. Then, we present a dataset of $132,037$ text-to-PDDL pairs across 13 different tasks, with varying levels of difficulty. Finally, we evaluate several API-access and open-weight language models that reveal this task's complexity. For example, $87.6\%$ of the PDDL problem descriptions generated by GPT-4o are syntactically parseable, $82.2\%$ are valid, solve-able problems, but only $35.1\%$ are semantically correct, highlighting the need for a more rigorous benchmark for this problem.
Preference Tuning For Toxicity Mitigation Generalizes Across Languages
Jun 23, 2024



Detoxifying multilingual Large Language Models (LLMs) has become crucial due to their increasing global use. In this work, we explore zero-shot cross-lingual generalization of preference tuning in detoxifying LLMs. Unlike previous studies that show limited cross-lingual generalization for other safety tasks, we demonstrate that Direct Preference Optimization (DPO) training with only English data can significantly reduce toxicity in multilingual open-ended generations. For example, the probability of mGPT-1.3B generating toxic continuations drops from 46.8% to 3.9% across 17 different languages after training. Our results also extend to other multilingual LLMs, such as BLOOM, Llama3, and Aya-23. Using mechanistic interpretability tools like causal intervention and activation analysis, we identified the dual multilinguality property of MLP layers in LLMs, which explains the cross-lingual generalization of DPO. Finally, we show that bilingual sentence retrieval can predict the cross-lingual transferability of DPO preference tuning.
If CLIP Could Talk: Understanding Vision-Language Model Representations Through Their Preferred Concept Descriptions
Mar 25, 2024Recent works often assume that Vision-Language Model (VLM) representations are based on visual attributes like shape. However, it is unclear to what extent VLMs prioritize this information to represent concepts. We propose Extract and Explore (EX2), a novel approach to characterize important textual features for VLMs. EX2 uses reinforcement learning to align a large language model with VLM preferences and generates descriptions that incorporate the important features for the VLM. Then, we inspect the descriptions to identify the features that contribute to VLM representations. We find that spurious descriptions have a major role in VLM representations despite providing no helpful information, e.g., Click to enlarge photo of CONCEPT. More importantly, among informative descriptions, VLMs rely significantly on non-visual attributes like habitat to represent visual concepts. Also, our analysis reveals that different VLMs prioritize different attributes in their representations. Overall, we show that VLMs do not simply match images to scene descriptions and that non-visual or even spurious descriptions significantly influence their representations.