 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Geometric View of Counterfactual Behavior: Interaction of Boundary Proximity and Local Support
Jun 02, 2026Counterfactual explanations seek small, semantically meaningful changes to an input that alter a model's prediction, and are widely used to interpret and audit machine learning systems. In modern vision, language, and multimodal systems, pretrained encoders map inputs to representation spaces, and downstream classifier heads impose decision boundaries within those spaces. As a result, the feasibility and distance of nearby counterfactuals depend on boundary placement relative to the data. Yet models with similar predictive performance can differ substantially in whether such changes are achievable and how far representations must move. This work examines this variation using a standardized local search probe across several pretrained encoders and linear classifier heads. Results show that despite similar predictive performance, models differ substantially in their counterfactual behavior. Under fixed representations, varying only the classifier head alters counterfactual outcomes while leaving predictive performance largely unchanged. This variation is explained by the interaction of decision-boundary proximity and local data support, which jointly determine whether prediction changes are both feasible and lie in regions supported by the data, and can also improve counterfactual search within fixed models. Together, these findings identify counterfactual behavior as a distinct dimension beyond predictive performance and show that it can be altered without changing accuracy, with implications for model selection, robustness, and the reliability of counterfactual methods.
Handling and Interpreting Missing Modalities in Patient Clinical Trajectories via Autoregressive Sequence Modeling
Apr 20, 2026An active challenge in developing multimodal machine learning (ML) models for healthcare is handling missing modalities during training and deployment. As clinical datasets are inherently temporal and sparse in terms of modality presence, capturing the underlying predictive signal via diagnostic multimodal ML models while retaining model explainability remains an ongoing challenge. In this work, we address this by re-framing clinical diagnosis as an autoregressive sequence modeling task, utilizing causal decoders from large language models (LLMs) to model a patient's multimodal trajectory. We first introduce a missingness-aware contrastive pre-training objective that integrates multiple modalities in datasets with missingness in a shared latent space. We then show that autoregressive sequence modeling with transformer-based architectures outperforms baselines on the MIMIC-IV and eICU fine-tuning benchmarks. Finally, we use interpretability techniques to move beyond performance boosts and find that across various patient stays, removing modalities leads to divergent behavior that our contrastive pre-training mitigates. By abstracting clinical diagnosis as sequence modeling and interpreting patient stay trajectories, we develop a framework to profile and handle missing modalities while addressing the canonical desideratum of safe, transparent clinical AI.
Is There Knowledge Left to Extract? Evidence of Fragility in Medically Fine-Tuned Vision-Language Models
Apr 10, 2026Vision-language models (VLMs) are increasingly adapted through domain-specific fine-tuning, yet it remains unclear whether this improves reasoning beyond superficial visual cues, particularly in high-stakes domains like medicine. We evaluate four paired open-source VLMs (LLaVA vs. LLaVA-Med; Gemma vs. MedGemma) across four medical imaging tasks of increasing difficulty: brain tumor, pneumonia, skin cancer, and histopathology classification. We find that performance degrades toward near-random levels as task difficulty increases, indicating limited clinical reasoning. Medical fine-tuning provides no consistent advantage, and models are highly sensitive to prompt formulation, with minor changes causing large swings in accuracy and refusal rates. To test whether closed-form VQA suppresses latent knowledge, we introduce a description-based pipeline where models generate image descriptions that a text-only model (GPT-5.1) uses for diagnosis. This recovers a limited additional signal but remains bounded by task difficulty. Analysis of vision encoder embeddings further shows that failures stem from both weak visual representations and downstream reasoning. Overall, medical VLM performance is fragile, prompt-dependent, and not reliably improved by domain-specific fine-tuning.
UbuntuGuard: A Culturally-Grounded Policy Benchmark for Equitable AI Safety in African Languages
Jan 19, 2026Current guardian models are predominantly Western-centric and optimized for high-resource languages, leaving low-resource African languages vulnerable to evolving harms, cross-lingual safety failures, and cultural misalignment. Moreover, most guardian models rely on rigid, predefined safety categories that fail to generalize across diverse linguistic and sociocultural contexts. Robust safety, therefore, requires flexible, runtime-enforceable policies and benchmarks that reflect local norms, harm scenarios, and cultural expectations. We introduce UbuntuGuard, the first African policy-based safety benchmark built from adversarial queries authored by 155 domain experts across sensitive fields, including healthcare. From these expert-crafted queries, we derive context-specific safety policies and reference responses that capture culturally grounded risk signals, enabling policy-aligned evaluation of guardian models. We evaluate 13 models, comprising six general-purpose LLMs and seven guardian models across three distinct variants: static, dynamic, and multilingual. Our findings reveal that existing English-centric benchmarks overestimate real-world multilingual safety, cross-lingual transfer provides partial but insufficient coverage, and dynamic models, while better equipped to leverage policies at inference time, still struggle to fully localize African-language contexts. These findings highlight the urgent need for multilingual, culturally grounded safety benchmarks to enable the development of reliable and equitable guardian models for low-resource languages. Our code can be found online.\footnote{Code repository available at https://github.com/hemhemoh/UbuntuGuard.
Mechanisms of Prompt-Induced Hallucination in Vision-Language Models
Jan 08, 2026Large vision-language models (VLMs) are highly capable, yet often hallucinate by favoring textual prompts over visual evidence. We study this failure mode in a controlled object-counting setting, where the prompt overstates the number of objects in the image (e.g., asking a model to describe four waterlilies when only three are present). At low object counts, models often correct the overestimation, but as the number of objects increases, they increasingly conform to the prompt regardless of the discrepancy. Through mechanistic analysis of three VLMs, we identify a small set of attention heads whose ablation substantially reduces prompt-induced hallucinations (PIH) by at least 40% without additional training. Across models, PIH-heads mediate prompt copying in model-specific ways. We characterize these differences and show that PIH ablation increases correction toward visual evidence. Our findings offer insights into the internal mechanisms driving prompt-induced hallucinations, revealing model-specific differences in how these behaviors are implemented.
Pixels Versus Priors: Controlling Knowledge Priors in Vision-Language Models through Visual Counterfacts
May 21, 2025Multimodal Large Language Models (MLLMs) perform well on tasks such as visual question answering, but it remains unclear whether their reasoning relies more on memorized world knowledge or on the visual information present in the input image. To investigate this, we introduce Visual CounterFact, a new dataset of visually-realistic counterfactuals that put world knowledge priors (e.g, red strawberry) into direct conflict with visual input (e.g, blue strawberry). Using Visual CounterFact, we show that model predictions initially reflect memorized priors, but shift toward visual evidence in mid-to-late layers. This dynamic reveals a competition between the two modalities, with visual input ultimately overriding priors during evaluation. To control this behavior, we propose Pixels Versus Priors (PvP) steering vectors, a mechanism for controlling model outputs toward either world knowledge or visual input through activation-level interventions. On average, PvP successfully shifts 92.5% of color and 74.6% of size predictions from priors to counterfactuals. Together, these findings offer new tools for interpreting and controlling factual behavior in multimodal models.
Forgotten Polygons: Multimodal Large Language Models are Shape-Blind
Feb 21, 2025Despite strong performance on vision-language tasks, Multimodal Large Language Models (MLLMs) struggle with mathematical problem-solving, with both open-source and state-of-the-art models falling short of human performance on visual-math benchmarks. To systematically examine visual-mathematical reasoning in MLLMs, we (1) evaluate their understanding of geometric primitives, (2) test multi-step reasoning, and (3) explore a potential solution to improve visual reasoning capabilities. Our findings reveal fundamental shortcomings in shape recognition, with top models achieving under 50% accuracy in identifying regular polygons. We analyze these failures through the lens of dual-process theory and show that MLLMs rely on System 1 (intuitive, memorized associations) rather than System 2 (deliberate reasoning). Consequently, MLLMs fail to count the sides of both familiar and novel shapes, suggesting they have neither learned the concept of sides nor effectively process visual inputs. Finally, we propose Visually Cued Chain-of-Thought (VC-CoT) prompting, which enhances multi-step mathematical reasoning by explicitly referencing visual annotations in diagrams, boosting GPT-4o's accuracy on an irregular polygon side-counting task from 7% to 93%. Our findings suggest that System 2 reasoning in MLLMs remains an open problem, and visually-guided prompting is essential for successfully engaging visual reasoning. Code available at: https://github.com/rsinghlab/Shape-Blind.
K-Paths: Reasoning over Graph Paths for Drug Repurposing and Drug Interaction Prediction
Feb 18, 2025Drug discovery is a complex and time-intensive process that requires identifying and validating new therapeutic candidates. Computational approaches using large-scale biomedical knowledge graphs (KGs) offer a promising solution to accelerate this process. However, extracting meaningful insights from large-scale KGs remains challenging due to the complexity of graph traversal. Existing subgraph-based methods are tailored to graph neural networks (GNNs), making them incompatible with other models, such as large language models (LLMs). We introduce K-Paths, a retrieval framework that extracts structured, diverse, and biologically meaningful paths from KGs. Integrating these paths enables LLMs and GNNs to effectively predict unobserved drug-drug and drug-disease interactions. Unlike traditional path-ranking approaches, K-Paths retrieves and transforms paths into a structured format that LLMs can directly process, facilitating explainable reasoning. K-Paths employs a diversity-aware adaptation of Yen's algorithm to retrieve the K shortest loopless paths between entities in an interaction query, prioritizing biologically relevant and diverse relationships. Our experiments on benchmark datasets show that K-Paths improves the zero-shot performance of Llama 8.1B's F1-score by 12.45 points on drug repurposing and 13.42 points on interaction severity prediction. We also show that Llama 70B achieves F1-score gains of 6.18 and 8.46 points, respectively. K-Paths also improves the supervised training efficiency of EmerGNN, a state-of-the-art GNN, by reducing KG size by 90% while maintaining strong predictive performance. Beyond its scalability and efficiency, K-Paths uniquely bridges the gap between KGs and LLMs, providing explainable rationales for predicted interactions. These capabilities show that K-Paths is a valuable tool for efficient data-driven drug discovery.
BetaExplainer: A Probabilistic Method to Explain Graph Neural Networks
Dec 16, 2024Graph neural networks (GNNs) are powerful tools for conducting inference on graph data but are often seen as "black boxes" due to difficulty in extracting meaningful subnetworks driving predictive performance. Many interpretable GNN methods exist, but they cannot quantify uncertainty in edge weights and suffer in predictive accuracy when applied to challenging graph structures. In this work, we proposed BetaExplainer which addresses these issues by using a sparsity-inducing prior to mask unimportant edges during model training. To evaluate our approach, we examine various simulated data sets with diverse real-world characteristics. Not only does this implementation provide a notion of edge importance uncertainty, it also improves upon evaluation metrics for challenging datasets compared to state-of-the art explainer methods.
What Do VLMs NOTICE? A Mechanistic Interpretability Pipeline for Noise-free Text-Image Corruption and Evaluation
Jun 24, 2024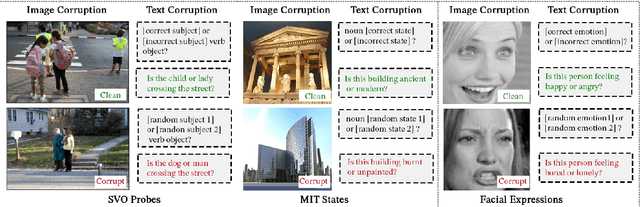

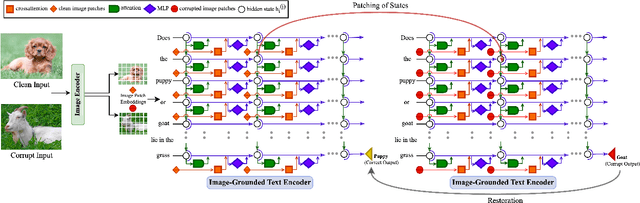
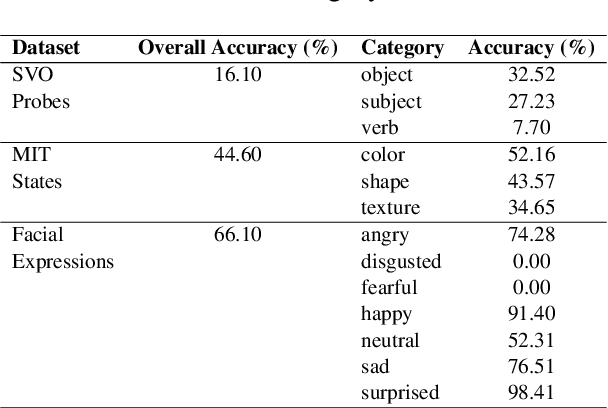
Vision-Language Models (VLMs) have gained community-spanning prominence due to their ability to integrate visual and textual inputs to perform complex tasks. Despite their success, the internal decision-making processes of these models remain opaque, posing challenges in high-stakes applications. To address this, we introduce NOTICE, the first Noise-free Text-Image Corruption and Evaluation pipeline for mechanistic interpretability in VLMs. NOTICE incorporates a Semantic Minimal Pairs (SMP) framework for image corruption and Symmetric Token Replacement (STR) for text. This approach enables semantically meaningful causal mediation analysis for both modalities, providing a robust method for analyzing multimodal integration within models like BLIP. Our experiments on the SVO-Probes, MIT-States, and Facial Expression Recognition datasets reveal crucial insights into VLM decision-making, identifying the significant role of middle-layer cross-attention heads. Further, we uncover a set of ``universal cross-attention heads'' that consistently contribute across tasks and modalities, each performing distinct functions such as implicit image segmentation, object inhibition, and outlier inhibition. This work paves the way for more transparent and interpretable multimodal systems.