 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs There Knowledge Left to Extract? Evidence of Fragility in Medically Fine-Tuned Vision-Language Models
Apr 10, 2026Vision-language models (VLMs) are increasingly adapted through domain-specific fine-tuning, yet it remains unclear whether this improves reasoning beyond superficial visual cues, particularly in high-stakes domains like medicine. We evaluate four paired open-source VLMs (LLaVA vs. LLaVA-Med; Gemma vs. MedGemma) across four medical imaging tasks of increasing difficulty: brain tumor, pneumonia, skin cancer, and histopathology classification. We find that performance degrades toward near-random levels as task difficulty increases, indicating limited clinical reasoning. Medical fine-tuning provides no consistent advantage, and models are highly sensitive to prompt formulation, with minor changes causing large swings in accuracy and refusal rates. To test whether closed-form VQA suppresses latent knowledge, we introduce a description-based pipeline where models generate image descriptions that a text-only model (GPT-5.1) uses for diagnosis. This recovers a limited additional signal but remains bounded by task difficulty. Analysis of vision encoder embeddings further shows that failures stem from both weak visual representations and downstream reasoning. Overall, medical VLM performance is fragile, prompt-dependent, and not reliably improved by domain-specific fine-tuning.
When to Call an Apple Red: Humans Follow Introspective Rules, VLMs Don't
Apr 07, 2026Understanding when Vision-Language Models (VLMs) will behave unexpectedly, whether models can reliably predict their own behavior, and if models adhere to their introspective reasoning are central challenges for trustworthy deployment. To study this, we introduce the Graded Color Attribution (GCA) dataset, a controlled benchmark designed to elicit decision rules and evaluate participant faithfulness to these rules. GCA consists of line drawings that vary pixel-level color coverage across three conditions: world-knowledge recolorings, counterfactual recolorings, and shapes with no color priors. Using GCA, both VLMs and human participants establish a threshold: the minimum percentage of pixels of a given color an object must have to receive that color label. We then compare these rules with their subsequent color attribution decisions. Our findings reveal that models systematically violate their own introspective rules. For example, GPT-5-mini violates its stated introspection rules in nearly 60\% of cases on objects with strong color priors. Human participants remain faithful to their stated rules, with any apparent violations being explained by a well-documented tendency to overestimate color coverage. In contrast, we find that VLMs are excellent estimators of color coverage, yet blatantly contradict their own reasoning in their final responses. Across all models and strategies for eliciting introspective rules, world-knowledge priors systematically degrade faithfulness in ways that do not mirror human cognition. Our findings challenge the view that VLM reasoning failures are difficulty-driven and suggest that VLM introspective self-knowledge is miscalibrated, with direct implications for high-stakes deployment.
Mechanisms of Prompt-Induced Hallucination in Vision-Language Models
Jan 08, 2026Large vision-language models (VLMs) are highly capable, yet often hallucinate by favoring textual prompts over visual evidence. We study this failure mode in a controlled object-counting setting, where the prompt overstates the number of objects in the image (e.g., asking a model to describe four waterlilies when only three are present). At low object counts, models often correct the overestimation, but as the number of objects increases, they increasingly conform to the prompt regardless of the discrepancy. Through mechanistic analysis of three VLMs, we identify a small set of attention heads whose ablation substantially reduces prompt-induced hallucinations (PIH) by at least 40% without additional training. Across models, PIH-heads mediate prompt copying in model-specific ways. We characterize these differences and show that PIH ablation increases correction toward visual evidence. Our findings offer insights into the internal mechanisms driving prompt-induced hallucinations, revealing model-specific differences in how these behaviors are implemented.
APP: Accelerated Path Patching with Task-Specific Pruning
Nov 07, 2025Circuit discovery is a key step in many mechanistic interpretability pipelines. Current methods, such as Path Patching, are computationally expensive and have limited in-depth circuit analysis for smaller models. In this study, we propose Accelerated Path Patching (APP), a hybrid approach leveraging our novel contrastive attention head pruning method to drastically reduce the search space of circuit discovery methods. Our Contrastive-FLAP pruning algorithm uses techniques from causal mediation analysis to assign higher pruning scores to task-specific attention heads, leading to higher performing sparse models compared to traditional pruning techniques. Although Contrastive-FLAP is successful at preserving task-specific heads that existing pruning algorithms remove at low sparsity ratios, the circuits found by Contrastive-FLAP alone are too large to satisfy the minimality constraint required in circuit analysis. APP first applies Contrastive-FLAP to reduce the search space on required for circuit discovery algorithms by, on average, 56\%. Next, APP, applies traditional Path Patching on the remaining attention heads, leading to a speed up of 59.63\%-93.27\% compared to Path Patching applied to the dense model. Despite the substantial computational saving that APP provides, circuits obtained from APP exhibit substantial overlap and similar performance to previously established Path Patching circuits
TRIM: Achieving Extreme Sparsity with Targeted Row-wise Iterative Metric-driven Pruning
May 22, 2025Large Language Models (LLMs) present significant computational and memory challenges due to their extensive size, making pruning essential for their efficient deployment. Existing one-shot pruning methods often apply uniform sparsity constraints across layers or within each layer, resulting in suboptimal performance, especially at high sparsity ratios. This work introduces TRIM (Targeted Row-wise Iterative Metric-driven pruning), a novel approach that applies varying sparsity ratios to individual output dimensions (rows) within each layer. TRIM employs an iterative adjustment process guided by quality metrics to optimize dimension-wise sparsity allocation, focusing on reducing variance in quality retention across outputs to preserve critical information. TRIM can be seamlessly integrated with existing layer-wise pruning strategies. Our evaluations on perplexity and zero-shot tasks across diverse LLM families (Qwen2.5, LLaMA-2, and OPT) and sparsity levels demonstrate that TRIM achieves new state-of-the-art results and enhances stability. For instance, at 80% sparsity, TRIM reduces perplexity by 48% for Qwen2.5-14B and over 90% for OPT-13B compared to baseline methods. We conclude that fine-grained, dimension-wise sparsity adaptation is crucial for pushing the limits of extreme LLM compression. Code available at: https://github.com/flobk/TRIM
Pixels Versus Priors: Controlling Knowledge Priors in Vision-Language Models through Visual Counterfacts
May 21, 2025Multimodal Large Language Models (MLLMs) perform well on tasks such as visual question answering, but it remains unclear whether their reasoning relies more on memorized world knowledge or on the visual information present in the input image. To investigate this, we introduce Visual CounterFact, a new dataset of visually-realistic counterfactuals that put world knowledge priors (e.g, red strawberry) into direct conflict with visual input (e.g, blue strawberry). Using Visual CounterFact, we show that model predictions initially reflect memorized priors, but shift toward visual evidence in mid-to-late layers. This dynamic reveals a competition between the two modalities, with visual input ultimately overriding priors during evaluation. To control this behavior, we propose Pixels Versus Priors (PvP) steering vectors, a mechanism for controlling model outputs toward either world knowledge or visual input through activation-level interventions. On average, PvP successfully shifts 92.5% of color and 74.6% of size predictions from priors to counterfactuals. Together, these findings offer new tools for interpreting and controlling factual behavior in multimodal models.
Forgotten Polygons: Multimodal Large Language Models are Shape-Blind
Feb 21, 2025Despite strong performance on vision-language tasks, Multimodal Large Language Models (MLLMs) struggle with mathematical problem-solving, with both open-source and state-of-the-art models falling short of human performance on visual-math benchmarks. To systematically examine visual-mathematical reasoning in MLLMs, we (1) evaluate their understanding of geometric primitives, (2) test multi-step reasoning, and (3) explore a potential solution to improve visual reasoning capabilities. Our findings reveal fundamental shortcomings in shape recognition, with top models achieving under 50% accuracy in identifying regular polygons. We analyze these failures through the lens of dual-process theory and show that MLLMs rely on System 1 (intuitive, memorized associations) rather than System 2 (deliberate reasoning). Consequently, MLLMs fail to count the sides of both familiar and novel shapes, suggesting they have neither learned the concept of sides nor effectively process visual inputs. Finally, we propose Visually Cued Chain-of-Thought (VC-CoT) prompting, which enhances multi-step mathematical reasoning by explicitly referencing visual annotations in diagrams, boosting GPT-4o's accuracy on an irregular polygon side-counting task from 7% to 93%. Our findings suggest that System 2 reasoning in MLLMs remains an open problem, and visually-guided prompting is essential for successfully engaging visual reasoning. Code available at: https://github.com/rsinghlab/Shape-Blind.
What Do VLMs NOTICE? A Mechanistic Interpretability Pipeline for Noise-free Text-Image Corruption and Evaluation
Jun 24, 2024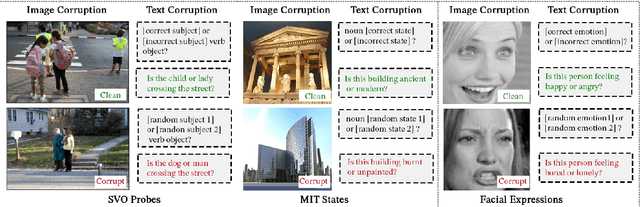

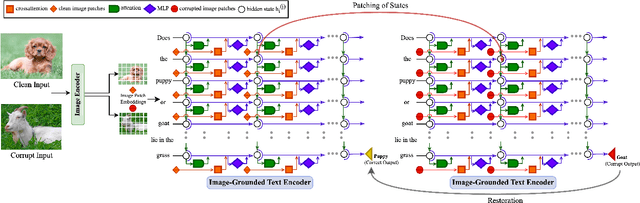
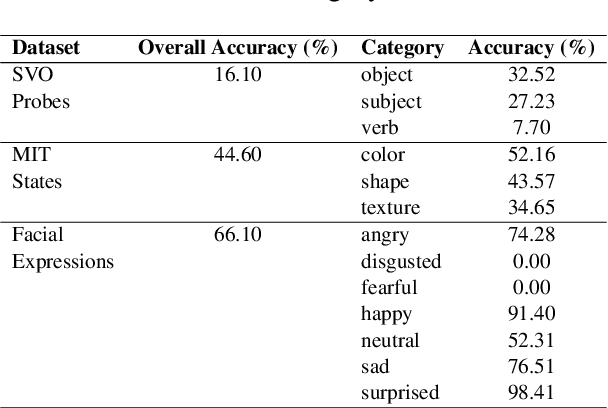
Vision-Language Models (VLMs) have gained community-spanning prominence due to their ability to integrate visual and textual inputs to perform complex tasks. Despite their success, the internal decision-making processes of these models remain opaque, posing challenges in high-stakes applications. To address this, we introduce NOTICE, the first Noise-free Text-Image Corruption and Evaluation pipeline for mechanistic interpretability in VLMs. NOTICE incorporates a Semantic Minimal Pairs (SMP) framework for image corruption and Symmetric Token Replacement (STR) for text. This approach enables semantically meaningful causal mediation analysis for both modalities, providing a robust method for analyzing multimodal integration within models like BLIP. Our experiments on the SVO-Probes, MIT-States, and Facial Expression Recognition datasets reveal crucial insights into VLM decision-making, identifying the significant role of middle-layer cross-attention heads. Further, we uncover a set of ``universal cross-attention heads'' that consistently contribute across tasks and modalities, each performing distinct functions such as implicit image segmentation, object inhibition, and outlier inhibition. This work paves the way for more transparent and interpretable multimodal systems.
Outlier Dimensions Encode Task-Specific Knowledge
Oct 26, 2023Representations from large language models (LLMs) are known to be dominated by a small subset of dimensions with exceedingly high variance. Previous works have argued that although ablating these outlier dimensions in LLM representations hurts downstream performance, outlier dimensions are detrimental to the representational quality of embeddings. In this study, we investigate how fine-tuning impacts outlier dimensions and show that 1) outlier dimensions that occur in pre-training persist in fine-tuned models and 2) a single outlier dimension can complete downstream tasks with a minimal error rate. Our results suggest that outlier dimensions can encode crucial task-specific knowledge and that the value of a representation in a single outlier dimension drives downstream model decisions.
Stable Anisotropic Regularization
May 30, 2023Given the success of Large Language Models (LLMs), there has been considerable interest in studying the properties of model activations. The literature overwhelmingly agrees that LLM representations are dominated by a few ``outlier dimensions'' with exceedingly high variance and magnitude. Several studies in Natural Language Processing (NLP) have sought to mitigate the impact of such outlier dimensions and force LLMs to be isotropic (i.e., have uniform variance across all dimensions in embedding space). Isotropy is thought to be a desirable property for LLMs that improves model performance and more closely aligns textual representations with human intuition. However, many of the claims regarding isotropy in NLP have been based on the average cosine similarity of embeddings, which has recently been shown to be a flawed measure of isotropy. In this paper, we propose I-STAR: IsoScore$^{\star}$-based STable Anisotropic Regularization, a novel regularization method that can be used to increase or decrease levels of isotropy in embedding space during training. I-STAR uses IsoScore$^{\star}$, the first accurate measure of isotropy that is both differentiable and stable on mini-batch computations. In contrast to several previous works, we find that \textit{decreasing} isotropy in contextualized embeddings improves performance on the majority of tasks and models considered in this paper.