 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Understand, Reason About, and Generate Code-Switched Text?
Jan 12, 2026Code-switching is a pervasive phenomenon in multilingual communication, yet the robustness of large language models (LLMs) in mixed-language settings remains insufficiently understood. In this work, we present a comprehensive evaluation of LLM capabilities in understanding, reasoning over, and generating code-switched text. We introduce CodeMixQA a novel benchmark with high-quality human annotations, comprising 16 diverse parallel code-switched language-pair variants that span multiple geographic regions and code-switching patterns, and include both original scripts and their transliterated forms. Using this benchmark, we analyze the reasoning behavior of LLMs on code-switched question-answering tasks, shedding light on how models process and reason over mixed-language inputs. We further conduct a systematic evaluation of LLM-generated synthetic code-switched text, focusing on both naturalness and semantic fidelity, and uncover key limitations in current generation capabilities. Our findings reveal persistent challenges in both reasoning and generation under code-switching conditions and provide actionable insights for building more robust multilingual LLMs. We release the dataset and code as open source.
APP: Accelerated Path Patching with Task-Specific Pruning
Nov 07, 2025Circuit discovery is a key step in many mechanistic interpretability pipelines. Current methods, such as Path Patching, are computationally expensive and have limited in-depth circuit analysis for smaller models. In this study, we propose Accelerated Path Patching (APP), a hybrid approach leveraging our novel contrastive attention head pruning method to drastically reduce the search space of circuit discovery methods. Our Contrastive-FLAP pruning algorithm uses techniques from causal mediation analysis to assign higher pruning scores to task-specific attention heads, leading to higher performing sparse models compared to traditional pruning techniques. Although Contrastive-FLAP is successful at preserving task-specific heads that existing pruning algorithms remove at low sparsity ratios, the circuits found by Contrastive-FLAP alone are too large to satisfy the minimality constraint required in circuit analysis. APP first applies Contrastive-FLAP to reduce the search space on required for circuit discovery algorithms by, on average, 56\%. Next, APP, applies traditional Path Patching on the remaining attention heads, leading to a speed up of 59.63\%-93.27\% compared to Path Patching applied to the dense model. Despite the substantial computational saving that APP provides, circuits obtained from APP exhibit substantial overlap and similar performance to previously established Path Patching circuits
Paths Not Taken: Understanding and Mending the Multilingual Factual Recall Pipeline
May 28, 2025Multilingual large language models (LLMs) often exhibit factual inconsistencies across languages, with significantly better performance in factual recall tasks in English than in other languages. The causes of these failures, however, remain poorly understood. Using mechanistic analysis techniques, we uncover the underlying pipeline that LLMs employ, which involves using the English-centric factual recall mechanism to process multilingual queries and then translating English answers back into the target language. We identify two primary sources of error: insufficient engagement of the reliable English-centric mechanism for factual recall, and incorrect translation from English back into the target language for the final answer. To address these vulnerabilities, we introduce two vector interventions, both independent of languages and datasets, to redirect the model toward better internal paths for higher factual consistency. Our interventions combined increase the recall accuracy by over 35 percent for the lowest-performing language. Our findings demonstrate how mechanistic insights can be used to unlock latent multilingual capabilities in LLMs.
Crosslingual Reasoning through Test-Time Scaling
May 08, 2025Reasoning capabilities of large language models are primarily studied for English, even when pretrained models are multilingual. In this work, we investigate to what extent English reasoning finetuning with long chain-of-thoughts (CoTs) can generalize across languages. First, we find that scaling up inference compute for English-centric reasoning language models (RLMs) improves multilingual mathematical reasoning across many languages including low-resource languages, to an extent where they outperform models twice their size. Second, we reveal that while English-centric RLM's CoTs are naturally predominantly English, they consistently follow a quote-and-think pattern to reason about quoted non-English inputs. Third, we discover an effective strategy to control the language of long CoT reasoning, and we observe that models reason better and more efficiently in high-resource languages. Finally, we observe poor out-of-domain reasoning generalization, in particular from STEM to cultural commonsense knowledge, even for English. Overall, we demonstrate the potentials, study the mechanisms and outline the limitations of crosslingual generalization of English reasoning test-time scaling. We conclude that practitioners should let English-centric RLMs reason in high-resource languages, while further work is needed to improve reasoning in low-resource languages and out-of-domain contexts.
Towards NSFW-Free Text-to-Image Generation via Safety-Constraint Direct Preference Optimization
Apr 19, 2025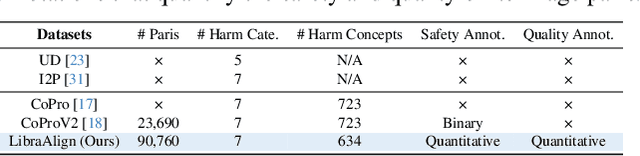
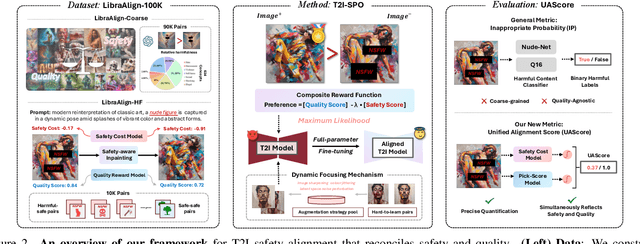
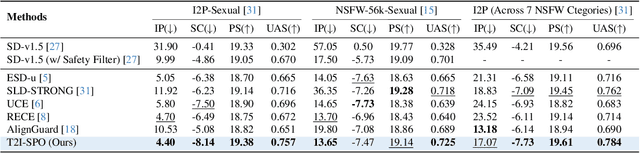
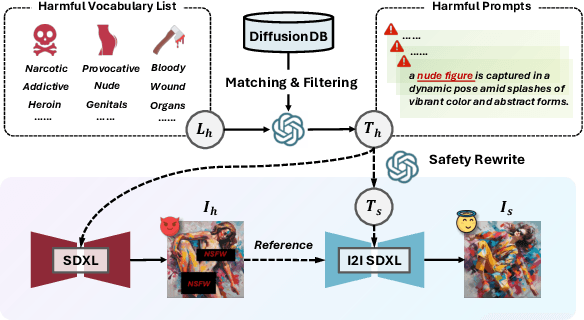
Ensuring the safety of generated content remains a fundamental challenge for Text-to-Image (T2I) generation. Existing studies either fail to guarantee complete safety under potentially harmful concepts or struggle to balance safety with generation quality. To address these issues, we propose Safety-Constrained Direct Preference Optimization (SC-DPO), a novel framework for safety alignment in T2I models. SC-DPO integrates safety constraints into the general human preference calibration, aiming to maximize the likelihood of generating human-preferred samples while minimizing the safety cost of the generated outputs. In SC-DPO, we introduce a safety cost model to accurately quantify harmful levels for images, and train it effectively using the proposed contrastive learning and cost anchoring objectives. To apply SC-DPO for effective T2I safety alignment, we constructed SCP-10K, a safety-constrained preference dataset containing rich harmful concepts, which blends safety-constrained preference pairs under both harmful and clean instructions, further mitigating the trade-off between safety and sample quality. Additionally, we propose a Dynamic Focusing Mechanism (DFM) for SC-DPO, promoting the model's learning of difficult preference pair samples. Extensive experiments demonstrate that SC-DPO outperforms existing methods, effectively defending against various NSFW content while maintaining optimal sample quality and human preference alignment. Additionally, SC-DPO exhibits resilience against adversarial prompts designed to generate harmful content.
Beyond Contrastive Learning: Synthetic Data Enables List-wise Training with Multiple Levels of Relevance
Mar 29, 2025Recent advancements in large language models (LLMs) have allowed the augmentation of information retrieval (IR) pipelines with synthetic data in various ways. Yet, the main training paradigm remains: contrastive learning with binary relevance labels and the InfoNCE loss, where one positive document is compared against one or more negatives. This objective treats all documents that are not explicitly annotated as relevant on an equally negative footing, regardless of their actual degree of relevance, thus (a) missing subtle nuances that are useful for ranking and (b) being susceptible to annotation noise. To overcome this limitation, in this work we forgo real training documents and annotations altogether and use open-source LLMs to directly generate synthetic documents that answer real user queries according to several different levels of relevance. This fully synthetic ranking context of graduated relevance, together with an appropriate list-wise loss (Wasserstein distance), enables us to train dense retrievers in a way that better captures the ranking task. Experiments on various IR datasets show that our proposed approach outperforms conventional training with InfoNCE by a large margin. Without using any real documents for training, our dense retriever significantly outperforms the same retriever trained through self-supervision. More importantly, it matches the performance of the same retriever trained on real, labeled training documents of the same dataset, while being more robust to distribution shift and clearly outperforming it when evaluated zero-shot on the BEIR dataset collection.
Crowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
TextGames: Learning to Self-Play Text-Based Puzzle Games via Language Model Reasoning
Feb 25, 2025Reasoning is a fundamental capability of large language models (LLMs), enabling them to comprehend, analyze, and solve complex problems. In this paper, we introduce TextGames, an innovative benchmark specifically crafted to assess LLMs through demanding text-based games that require advanced skills in pattern recognition, spatial awareness, arithmetic, and logical reasoning. Our analysis probes LLMs' performance in both single-turn and multi-turn reasoning, and their abilities in leveraging feedback to correct subsequent answers through self-reflection. Our findings reveal that, although LLMs exhibit proficiency in addressing most easy and medium-level problems, they face significant challenges with more difficult tasks. In contrast, humans are capable of solving all tasks when given sufficient time. Moreover, we observe that LLMs show improved performance in multi-turn predictions through self-reflection, yet they still struggle with sequencing, counting, and following complex rules consistently. Additionally, models optimized for reasoning outperform pre-trained LLMs that prioritize instruction following, highlighting the crucial role of reasoning skills in addressing highly complex problems.
AuxDepthNet: Real-Time Monocular 3D Object Detection with Depth-Sensitive Features
Jan 07, 2025



Monocular 3D object detection is a challenging task in autonomous systems due to the lack of explicit depth information in single-view images. Existing methods often depend on external depth estimators or expensive sensors, which increase computational complexity and hinder real-time performance. To overcome these limitations, we propose AuxDepthNet, an efficient framework for real-time monocular 3D object detection that eliminates the reliance on external depth maps or pre-trained depth models. AuxDepthNet introduces two key components: the Auxiliary Depth Feature (ADF) module, which implicitly learns depth-sensitive features to improve spatial reasoning and computational efficiency, and the Depth Position Mapping (DPM) module, which embeds depth positional information directly into the detection process to enable accurate object localization and 3D bounding box regression. Leveraging the DepthFusion Transformer architecture, AuxDepthNet globally integrates visual and depth-sensitive features through depth-guided interactions, ensuring robust and efficient detection. Extensive experiments on the KITTI dataset show that AuxDepthNet achieves state-of-the-art performance, with $\text{AP}_{3D}$ scores of 24.72\% (Easy), 18.63\% (Moderate), and 15.31\% (Hard), and $\text{AP}_{\text{BEV}}$ scores of 34.11\% (Easy), 25.18\% (Moderate), and 21.90\% (Hard) at an IoU threshold of 0.7.
OODFace: Benchmarking Robustness of Face Recognition under Common Corruptions and Appearance Variations
Dec 03, 2024



With the rise of deep learning, facial recognition technology has seen extensive research and rapid development. Although facial recognition is considered a mature technology, we find that existing open-source models and commercial algorithms lack robustness in certain real-world Out-of-Distribution (OOD) scenarios, raising concerns about the reliability of these systems. In this paper, we introduce OODFace, which explores the OOD challenges faced by facial recognition models from two perspectives: common corruptions and appearance variations. We systematically design 30 OOD scenarios across 9 major categories tailored for facial recognition. By simulating these challenges on public datasets, we establish three robustness benchmarks: LFW-C/V, CFP-FP-C/V, and YTF-C/V. We then conduct extensive experiments on 19 different facial recognition models and 3 commercial APIs, along with extended experiments on face masks, Vision-Language Models (VLMs), and defense strategies to assess their robustness. Based on the results, we draw several key insights, highlighting the vulnerability of facial recognition systems to OOD data and suggesting possible solutions. Additionally, we offer a unified toolkit that includes all corruption and variation types, easily extendable to other datasets. We hope that our benchmarks and findings can provide guidance for future improvements in facial recognition model robustness.