 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Representation Steering for Language Models
May 27, 2025Steering methods for language models (LMs) seek to provide fine-grained and interpretable control over model generations by variously changing model inputs, weights, or representations to adjust behavior. Recent work has shown that adjusting weights or representations is often less effective than steering by prompting, for instance when wanting to introduce or suppress a particular concept. We demonstrate how to improve representation steering via our new Reference-free Preference Steering (RePS), a bidirectional preference-optimization objective that jointly does concept steering and suppression. We train three parameterizations of RePS and evaluate them on AxBench, a large-scale model steering benchmark. On Gemma models with sizes ranging from 2B to 27B, RePS outperforms all existing steering methods trained with a language modeling objective and substantially narrows the gap with prompting -- while promoting interpretability and minimizing parameter count. In suppression, RePS matches the language-modeling objective on Gemma-2 and outperforms it on the larger Gemma-3 variants while remaining resilient to prompt-based jailbreaking attacks that defeat prompting. Overall, our results suggest that RePS provides an interpretable and robust alternative to prompting for both steering and suppression.
The Same But Different: Structural Similarities and Differences in Multilingual Language Modeling
Oct 11, 2024We employ new tools from mechanistic interpretability in order to ask whether the internal structure of large language models (LLMs) shows correspondence to the linguistic structures which underlie the languages on which they are trained. In particular, we ask (1) when two languages employ the same morphosyntactic processes, do LLMs handle them using shared internal circuitry? and (2) when two languages require different morphosyntactic processes, do LLMs handle them using different internal circuitry? Using English and Chinese multilingual and monolingual models, we analyze the internal circuitry involved in two tasks. We find evidence that models employ the same circuit to handle the same syntactic process independently of the language in which it occurs, and that this is the case even for monolingual models trained completely independently. Moreover, we show that multilingual models employ language-specific components (attention heads and feed-forward networks) when needed to handle linguistic processes (e.g., morphological marking) that only exist in some languages. Together, our results provide new insights into how LLMs trade off between exploiting common structures and preserving linguistic differences when tasked with modeling multiple languages simultaneously.
LLM Circuit Analyses Are Consistent Across Training and Scale
Jul 15, 2024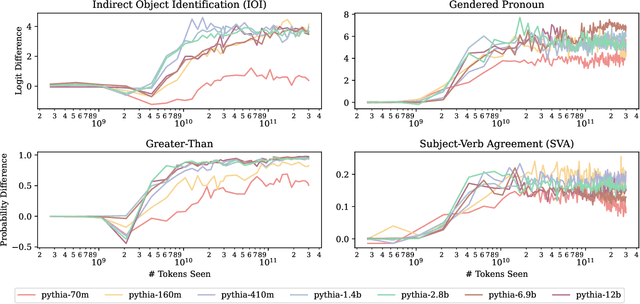
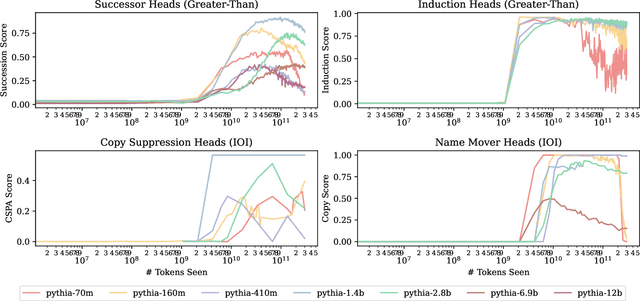
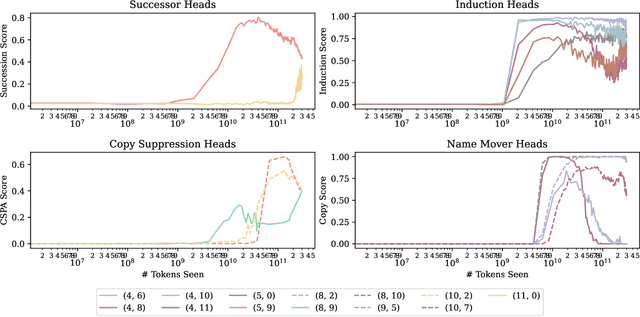
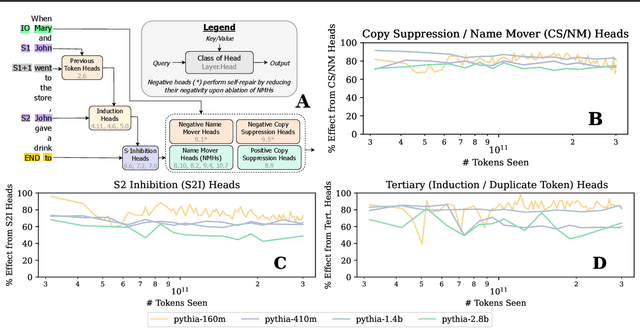
Most currently deployed large language models (LLMs) undergo continuous training or additional finetuning. By contrast, most research into LLMs' internal mechanisms focuses on models at one snapshot in time (the end of pre-training), raising the question of whether their results generalize to real-world settings. Existing studies of mechanisms over time focus on encoder-only or toy models, which differ significantly from most deployed models. In this study, we track how model mechanisms, operationalized as circuits, emerge and evolve across 300 billion tokens of training in decoder-only LLMs, in models ranging from 70 million to 2.8 billion parameters. We find that task abilities and the functional components that support them emerge consistently at similar token counts across scale. Moreover, although such components may be implemented by different attention heads over time, the overarching algorithm that they implement remains. Surprisingly, both these algorithms and the types of components involved therein can replicate across model scale. These results suggest that circuit analyses conducted on small models at the end of pre-training can provide insights that still apply after additional pre-training and over model scale.
Grokking Group Multiplication with Cosets
Dec 11, 2023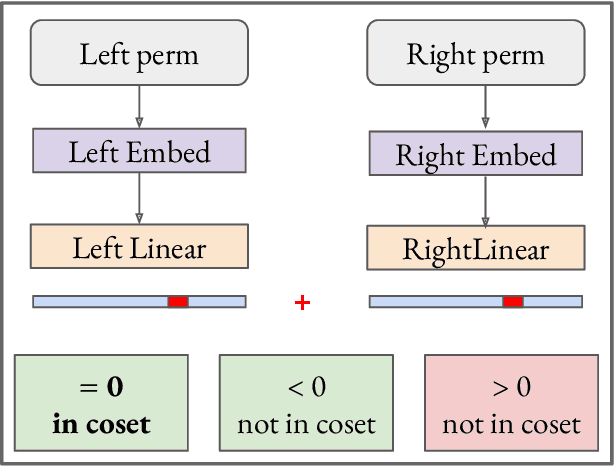
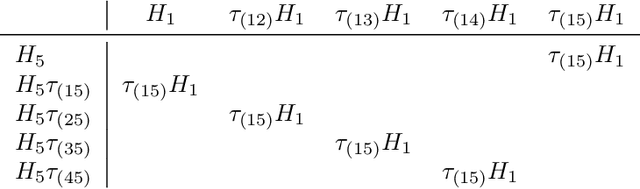
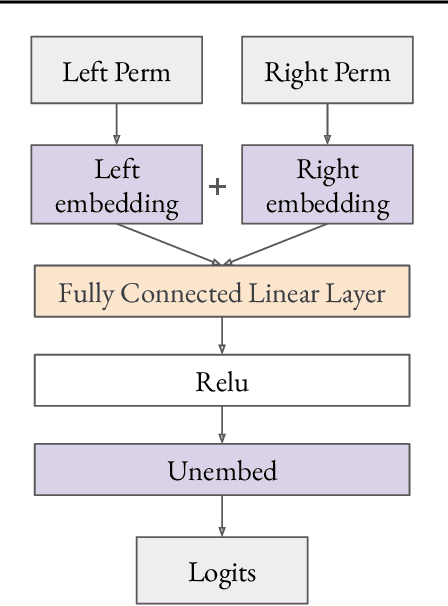
We use the group Fourier transform over the symmetric group $S_n$ to reverse engineer a 1-layer feedforward network that has "grokked" the multiplication of $S_5$ and $S_6$. Each model discovers the true subgroup structure of the full group and converges on circuits that decompose the group multiplication into the multiplication of the group's conjugate subgroups. We demonstrate the value of using the symmetries of the data and models to understand their mechanisms and hold up the ``coset circuit'' that the model uses as a fascinating example of the way neural networks implement computations. We also draw attention to current challenges in conducting mechanistic interpretability research by comparing our work to Chughtai et al. [6] which alleges to find a different algorithm for this same problem.
Characterizing Mechanisms for Factual Recall in Language Models
Oct 24, 2023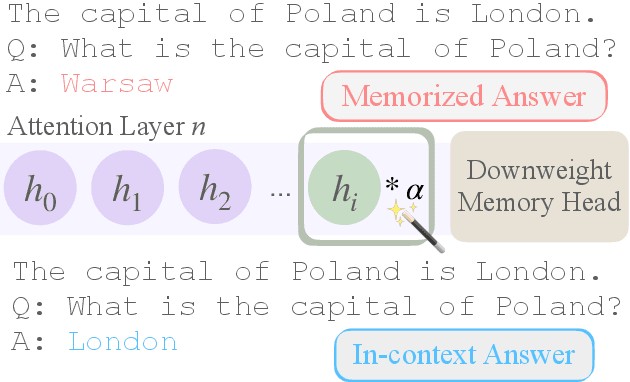

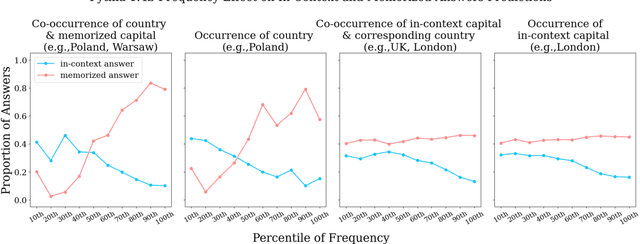
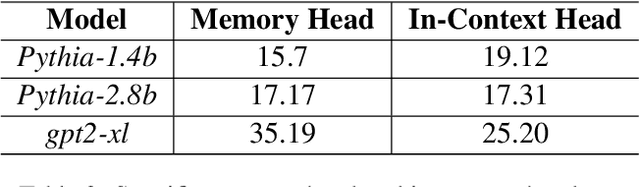
Language Models (LMs) often must integrate facts they memorized in pretraining with new information that appears in a given context. These two sources can disagree, causing competition within the model, and it is unclear how an LM will resolve the conflict. On a dataset that queries for knowledge of world capitals, we investigate both distributional and mechanistic determinants of LM behavior in such situations. Specifically, we measure the proportion of the time an LM will use a counterfactual prefix (e.g., "The capital of Poland is London") to overwrite what it learned in pretraining ("Warsaw"). On Pythia and GPT2, the training frequency of both the query country ("Poland") and the in-context city ("London") highly affect the models' likelihood of using the counterfactual. We then use head attribution to identify individual attention heads that either promote the memorized answer or the in-context answer in the logits. By scaling up or down the value vector of these heads, we can control the likelihood of using the in-context answer on new data. This method can increase the rate of generating the in-context answer to 88\% of the time simply by scaling a single head at runtime. Our work contributes to a body of evidence showing that we can often localize model behaviors to specific components and provides a proof of concept for how future methods might control model behavior dynamically at runtime.
Are Language Models Worse than Humans at Following Prompts? It's Complicated
Jan 17, 2023Prompts have been the center of progress in advancing language models' zero-shot and few-shot performance. However, recent work finds that models can perform surprisingly well when given intentionally irrelevant or misleading prompts. Such results may be interpreted as evidence that model behavior is not "human like". In this study, we challenge a central assumption in such work: that humans would perform badly when given pathological instructions. We find that humans are able to reliably ignore irrelevant instructions and thus, like models, perform well on the underlying task despite an apparent lack of signal regarding the task they are being asked to do. However, when given deliberately misleading instructions, humans follow the instructions faithfully, whereas models do not. Thus, our conclusion is mixed with respect to prior work. We argue against the earlier claim that high performance with irrelevant prompts constitutes evidence against models' instruction understanding, but we reinforce the claim that models' failure to follow misleading instructions raises concerns. More broadly, we caution that future research should not idealize human behaviors as a monolith and should not train or evaluate models to mimic assumptions about these behaviors without first validating humans' behaviors empirically.
Does CLIP Bind Concepts? Probing Compositionality in Large Image Models
Dec 20, 2022
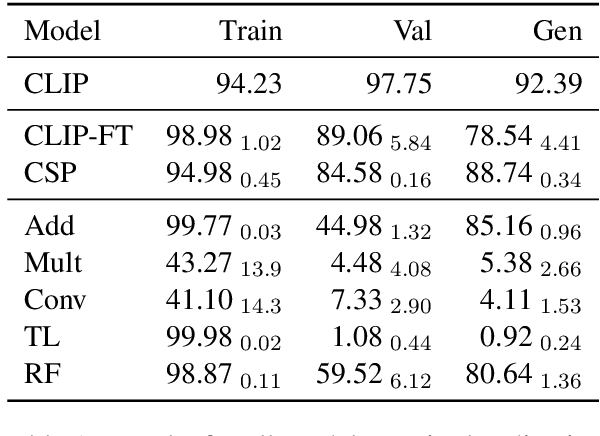
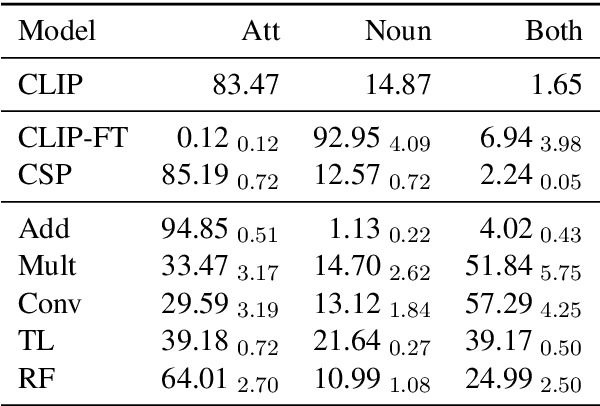
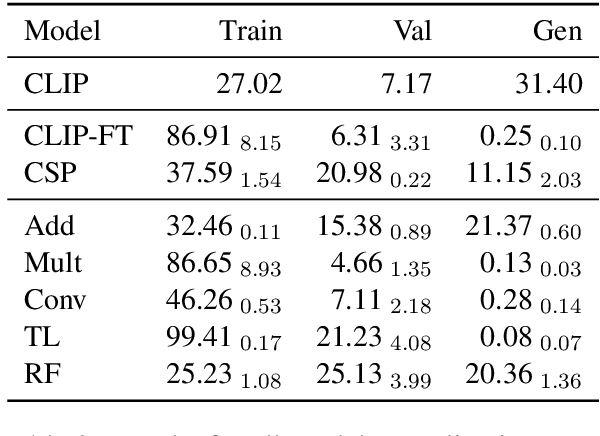
Large-scale models combining text and images have made incredible progress in recent years. However, they can still fail at tasks requiring compositional knowledge, such as correctly picking out a red cube from a picture of multiple shapes. We examine the ability of CLIP (Radford et al., 2021), to caption images requiring compositional knowledge. We implement five compositional language models to probe the kinds of structure that CLIP may be using, and develop a novel training algorithm, Compositional Skipgram for Images (CoSI), to train these models. We look at performance in attribute-based tasks, requiring the identification of a particular combination of attribute and object (such as "red cube"), and in relational settings, where the spatial relation between two shapes (such as "cube behind sphere") must be identified. We find that in some conditions, CLIP is able to learn attribute-object labellings, and to generalize to unseen attribute-object combinations. However, we also see evidence that CLIP is not able to bind features together reliably. Moreover, CLIP is not able to reliably learn relations between objects, whereas some compositional models are able to learn these perfectly. Of the five models we developed, none were able to generalize to unseen relations.