 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes CLIP Bind Concepts? Probing Compositionality in Large Image Models
Paper and Code

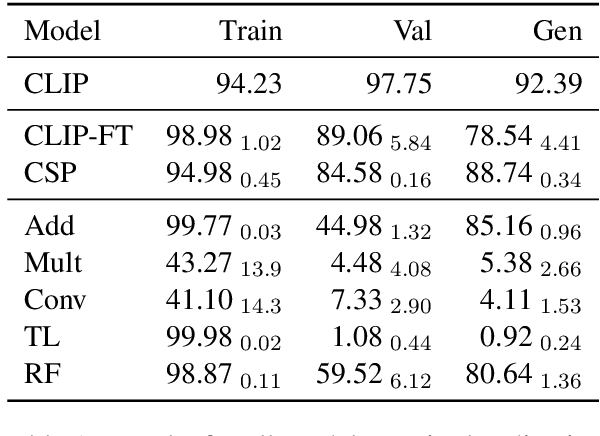
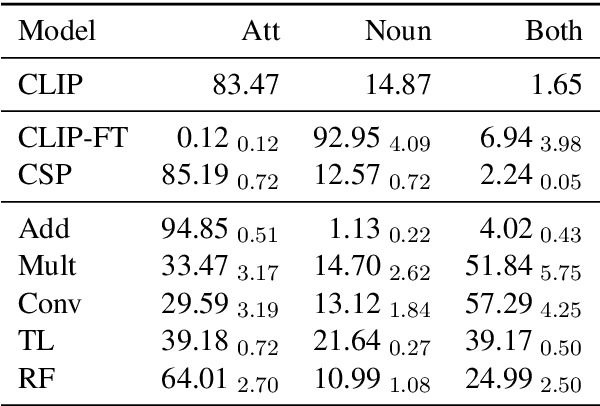
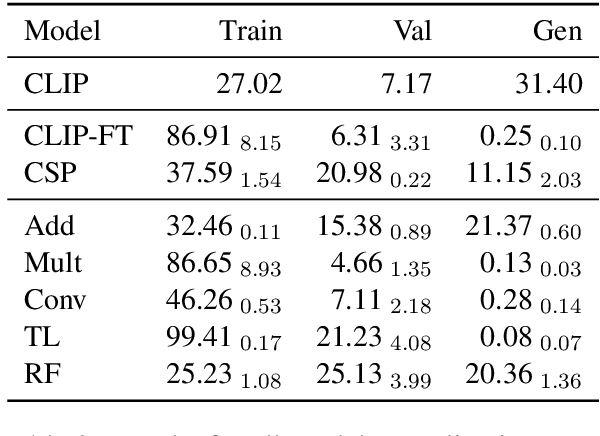
Large-scale models combining text and images have made incredible progress in recent years. However, they can still fail at tasks requiring compositional knowledge, such as correctly picking out a red cube from a picture of multiple shapes. We examine the ability of CLIP (Radford et al., 2021), to caption images requiring compositional knowledge. We implement five compositional language models to probe the kinds of structure that CLIP may be using, and develop a novel training algorithm, Compositional Skipgram for Images (CoSI), to train these models. We look at performance in attribute-based tasks, requiring the identification of a particular combination of attribute and object (such as "red cube"), and in relational settings, where the spatial relation between two shapes (such as "cube behind sphere") must be identified. We find that in some conditions, CLIP is able to learn attribute-object labellings, and to generalize to unseen attribute-object combinations. However, we also see evidence that CLIP is not able to bind features together reliably. Moreover, CLIP is not able to reliably learn relations between objects, whereas some compositional models are able to learn these perfectly. Of the five models we developed, none were able to generalize to unseen relations.