 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer See, Transformer Do: Copying as an Intermediate Step in Learning Analogical Reasoning
Apr 07, 2026Analogical reasoning is a hallmark of human intelligence, enabling us to solve new problems by transferring knowledge from one situation to another. Yet, developing artificial intelligence systems capable of robust human-like analogical reasoning has proven difficult. In this work, we train transformers using Meta-Learning for Compositionality (MLC) on an analogical reasoning task (letter-string analogies) and assess their generalization capabilities. We find that letter-string analogies become learnable when guiding the models to attend to the most informative problem elements induced by including copying tasks in the training data. Furthermore, generalization to new alphabets becomes better when models are trained with more heterogeneous datasets, where our 3-layer encoder-decoder model outperforms most frontier models. The MLC approach also enables some generalization to compositions of trained transformations, but not to completely novel transformations. To understand how the model operates, we identify an algorithm that approximates the model's computations. We verify this using interpretability analyses and show that the model can be steered precisely according to expectations derived from the algorithm. Finally, we discuss implications of our findings for generalization capabilities of larger models and parallels to human analogical reasoning.
Compositional Concept Generalization with Variational Quantum Circuits
Sep 11, 2025Compositional generalization is a key facet of human cognition, but lacking in current AI tools such as vision-language models. Previous work examined whether a compositional tensor-based sentence semantics can overcome the challenge, but led to negative results. We conjecture that the increased training efficiency of quantum models will improve performance in these tasks. We interpret the representations of compositional tensor-based models in Hilbert spaces and train Variational Quantum Circuits to learn these representations on an image captioning task requiring compositional generalization. We used two image encoding techniques: a multi-hot encoding (MHE) on binary image vectors and an angle/amplitude encoding on image vectors taken from the vision-language model CLIP. We achieve good proof-of-concept results using noisy MHE encodings. Performance on CLIP image vectors was more mixed, but still outperformed classical compositional models.
Evaluating Compositional Generalisation in VLMs and Diffusion Models
Aug 28, 2025



A fundamental aspect of the semantics of natural language is that novel meanings can be formed from the composition of previously known parts. Vision-language models (VLMs) have made significant progress in recent years, however, there is evidence that they are unable to perform this kind of composition. For example, given an image of a red cube and a blue cylinder, a VLM such as CLIP is likely to incorrectly label the image as a red cylinder or a blue cube, indicating it represents the image as a `bag-of-words' and fails to capture compositional semantics. Diffusion models have recently gained significant attention for their impressive generative abilities, and zero-shot classifiers based on diffusion models have been shown to perform competitively with CLIP in certain compositional tasks. In this work we explore whether the generative Diffusion Classifier has improved compositional generalisation abilities compared to discriminative models. We assess three models -- Diffusion Classifier, CLIP, and ViLT -- on their ability to bind objects with attributes and relations in both zero-shot learning (ZSL) and generalised zero-shot learning (GZSL) settings. Our results show that the Diffusion Classifier and ViLT perform well at concept binding tasks, but that all models struggle significantly with the relational GZSL task, underscoring the broader challenges VLMs face with relational reasoning. Analysis of CLIP embeddings suggests that the difficulty may stem from overly similar representations of relational concepts such as left and right. Code and dataset are available at: https://github.com/otmive/diffusion_classifier_clip
Behavioural vs. Representational Systematicity in End-to-End Models: An Opinionated Survey
Jun 04, 2025A core aspect of compositionality, systematicity is a desirable property in ML models as it enables strong generalization to novel contexts. This has led to numerous studies proposing benchmarks to assess systematic generalization, as well as models and training regimes designed to enhance it. Many of these efforts are framed as addressing the challenge posed by Fodor and Pylyshyn. However, while they argue for systematicity of representations, existing benchmarks and models primarily focus on the systematicity of behaviour. We emphasize the crucial nature of this distinction. Furthermore, building on Hadley's (1994) taxonomy of systematic generalization, we analyze the extent to which behavioural systematicity is tested by key benchmarks in the literature across language and vision. Finally, we highlight ways of assessing systematicity of representations in ML models as practiced in the field of mechanistic interpretability.
Evaluating the Robustness of Analogical Reasoning in Large Language Models
Nov 21, 2024

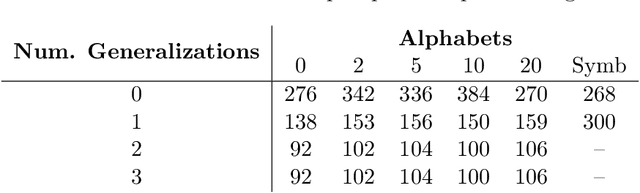

LLMs have performed well on several reasoning benchmarks, including ones that test analogical reasoning abilities. However, there is debate on the extent to which they are performing general abstract reasoning versus employing non-robust processes, e.g., that overly rely on similarity to pre-training data. Here we investigate the robustness of analogy-making abilities previously claimed for LLMs on three of four domains studied by Webb, Holyoak, and Lu (2023): letter-string analogies, digit matrices, and story analogies. For each domain we test humans and GPT models on robustness to variants of the original analogy problems that test the same abstract reasoning abilities but are likely dissimilar from tasks in the pre-training data. The performance of a system that uses robust abstract reasoning should not decline substantially on these variants. On simple letter-string analogies, we find that while the performance of humans remains high for two types of variants we tested, the GPT models' performance declines sharply. This pattern is less pronounced as the complexity of these problems is increased, as both humans and GPT models perform poorly on both the original and variant problems requiring more complex analogies. On digit-matrix problems, we find a similar pattern but only on one out of the two types of variants we tested. On story-based analogy problems, we find that, unlike humans, the performance of GPT models are susceptible to answer-order effects, and that GPT models also may be more sensitive than humans to paraphrasing. This work provides evidence that LLMs often lack the robustness of zero-shot human analogy-making, exhibiting brittleness on most of the variations we tested. More generally, this work points to the importance of carefully evaluating AI systems not only for accuracy but also robustness when testing their cognitive capabilities.
Density Matrices for Metaphor Understanding
Aug 12, 2024


In physics, density matrices are used to represent mixed states, i.e. probabilistic mixtures of pure states. This concept has previously been used to model lexical ambiguity. In this paper, we consider metaphor as a type of lexical ambiguity, and examine whether metaphorical meaning can be effectively modelled using mixtures of word senses. We find that modelling metaphor is significantly more difficult than other kinds of lexical ambiguity, but that our best-performing density matrix method outperforms simple baselines as well as some neural language models.
* In Proceedings QPL 2024, arXiv:2408.05113
Metaphor Understanding Challenge Dataset for LLMs
Mar 18, 2024



Metaphors in natural language are a reflection of fundamental cognitive processes such as analogical reasoning and categorisation, and are deeply rooted in everyday communication. Metaphor understanding is therefore an essential task for large language models (LLMs). We release the Metaphor Understanding Challenge Dataset (MUNCH), designed to evaluate the metaphor understanding capabilities of LLMs. The dataset provides over 10k paraphrases for sentences containing metaphor use, as well as 1.5k instances containing inapt paraphrases. The inapt paraphrases were carefully selected to serve as control to determine whether the model indeed performs full metaphor interpretation or rather resorts to lexical similarity. All apt and inapt paraphrases were manually annotated. The metaphorical sentences cover natural metaphor uses across 4 genres (academic, news, fiction, and conversation), and they exhibit different levels of novelty. Experiments with LLaMA and GPT-3.5 demonstrate that MUNCH presents a challenging task for LLMs. The dataset is freely accessible at https://github.com/xiaoyuisrain/metaphor-understanding-challenge.
Using Counterfactual Tasks to Evaluate the Generality of Analogical Reasoning in Large Language Models
Feb 14, 2024



Large language models (LLMs) have performed well on several reasoning benchmarks, including ones that test analogical reasoning abilities. However, it has been debated whether they are actually performing humanlike abstract reasoning or instead employing less general processes that rely on similarity to what has been seen in their training data. Here we investigate the generality of analogy-making abilities previously claimed for LLMs (Webb, Holyoak, & Lu, 2023). We take one set of analogy problems used to evaluate LLMs and create a set of "counterfactual" variants-versions that test the same abstract reasoning abilities but that are likely dissimilar from any pre-training data. We test humans and three GPT models on both the original and counterfactual problems, and show that, while the performance of humans remains high for all the problems, the GPT models' performance declines sharply on the counterfactual set. This work provides evidence that, despite previously reported successes of LLMs on analogical reasoning, these models lack the robustness and generality of human analogy-making.
Grounded learning for compositional vector semantics
Jan 10, 2024Categorical compositional distributional semantics is an approach to modelling language that combines the success of vector-based models of meaning with the compositional power of formal semantics. However, this approach was developed without an eye to cognitive plausibility. Vector representations of concepts and concept binding are also of interest in cognitive science, and have been proposed as a way of representing concepts within a biologically plausible spiking neural network. This work proposes a way for compositional distributional semantics to be implemented within a spiking neural network architecture, with the potential to address problems in concept binding, and give a small implementation. We also describe a means of training word representations using labelled images.
Compositional Fusion of Signals in Data Embedding
Nov 18, 2023



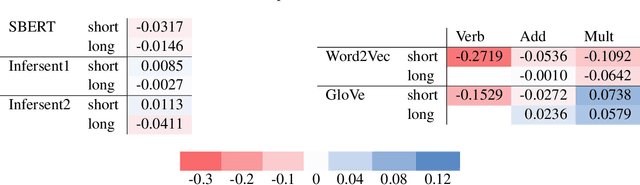
Embeddings in AI convert symbolic structures into fixed-dimensional vectors, effectively fusing multiple signals. However, the nature of this fusion in real-world data is often unclear. To address this, we introduce two methods: (1) Correlation-based Fusion Detection, measuring correlation between known attributes and embeddings, and (2) Additive Fusion Detection, viewing embeddings as sums of individual vectors representing attributes. Applying these methods, word embeddings were found to combine semantic and morphological signals. BERT sentence embeddings were decomposed into individual word vectors of subject, verb and object. In the knowledge graph-based recommender system, user embeddings, even without training on demographic data, exhibited signals of demographics like age and gender. This study highlights that embeddings are fusions of multiple signals, from Word2Vec components to demographic hints in graph embeddings.