 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Robustness of Analogical Reasoning in Large Language Models
Paper and Code


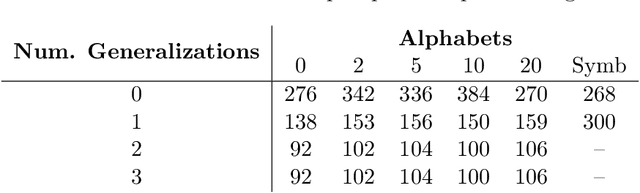

LLMs have performed well on several reasoning benchmarks, including ones that test analogical reasoning abilities. However, there is debate on the extent to which they are performing general abstract reasoning versus employing non-robust processes, e.g., that overly rely on similarity to pre-training data. Here we investigate the robustness of analogy-making abilities previously claimed for LLMs on three of four domains studied by Webb, Holyoak, and Lu (2023): letter-string analogies, digit matrices, and story analogies. For each domain we test humans and GPT models on robustness to variants of the original analogy problems that test the same abstract reasoning abilities but are likely dissimilar from tasks in the pre-training data. The performance of a system that uses robust abstract reasoning should not decline substantially on these variants. On simple letter-string analogies, we find that while the performance of humans remains high for two types of variants we tested, the GPT models' performance declines sharply. This pattern is less pronounced as the complexity of these problems is increased, as both humans and GPT models perform poorly on both the original and variant problems requiring more complex analogies. On digit-matrix problems, we find a similar pattern but only on one out of the two types of variants we tested. On story-based analogy problems, we find that, unlike humans, the performance of GPT models are susceptible to answer-order effects, and that GPT models also may be more sensitive than humans to paraphrasing. This work provides evidence that LLMs often lack the robustness of zero-shot human analogy-making, exhibiting brittleness on most of the variations we tested. More generally, this work points to the importance of carefully evaluating AI systems not only for accuracy but also robustness when testing their cognitive capabilities.