 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo AI Models Perform Human-like Abstract Reasoning Across Modalities?
Oct 02, 2025



OpenAI's o3-preview reasoning model exceeded human accuracy on the ARC-AGI benchmark, but does that mean state-of-the-art models recognize and reason with the abstractions that the task creators intended? We investigate models' abstraction abilities on ConceptARC. We evaluate models under settings that vary the input modality (textual vs. visual), whether the model is permitted to use external Python tools, and, for reasoning models, the amount of reasoning effort. In addition to measuring output accuracy, we perform fine-grained evaluation of the natural-language rules that models generate to explain their solutions. This dual evaluation lets us assess whether models solve tasks using the abstractions ConceptARC was designed to elicit, rather than relying on surface-level patterns. Our results show that, while some models using text-based representations match human output accuracy, the best models' rules are often based on surface-level ``shortcuts'' and capture intended abstractions far less often than humans. Thus their capabilities for general abstract reasoning may be overestimated by evaluations based on accuracy alone. In the visual modality, AI models' output accuracy drops sharply, yet our rule-level analysis reveals that models might be underestimated, as they still exhibit a substantial share of rules that capture intended abstractions, but are often unable to correctly apply these rules. In short, our results show that models still lag humans in abstract reasoning, and that using accuracy alone to evaluate abstract reasoning on ARC-like tasks may overestimate abstract-reasoning capabilities in textual modalities and underestimate it in visual modalities. We believe that our evaluation framework offers a more faithful picture of multimodal models' abstract reasoning abilities and a more principled way to track progress toward human-like, abstraction-centered intelligence.
Evaluating the Robustness of Analogical Reasoning in Large Language Models
Nov 21, 2024


LLMs have performed well on several reasoning benchmarks, including ones that test analogical reasoning abilities. However, there is debate on the extent to which they are performing general abstract reasoning versus employing non-robust processes, e.g., that overly rely on similarity to pre-training data. Here we investigate the robustness of analogy-making abilities previously claimed for LLMs on three of four domains studied by Webb, Holyoak, and Lu (2023): letter-string analogies, digit matrices, and story analogies. For each domain we test humans and GPT models on robustness to variants of the original analogy problems that test the same abstract reasoning abilities but are likely dissimilar from tasks in the pre-training data. The performance of a system that uses robust abstract reasoning should not decline substantially on these variants. On simple letter-string analogies, we find that while the performance of humans remains high for two types of variants we tested, the GPT models' performance declines sharply. This pattern is less pronounced as the complexity of these problems is increased, as both humans and GPT models perform poorly on both the original and variant problems requiring more complex analogies. On digit-matrix problems, we find a similar pattern but only on one out of the two types of variants we tested. On story-based analogy problems, we find that, unlike humans, the performance of GPT models are susceptible to answer-order effects, and that GPT models also may be more sensitive than humans to paraphrasing. This work provides evidence that LLMs often lack the robustness of zero-shot human analogy-making, exhibiting brittleness on most of the variations we tested. More generally, this work points to the importance of carefully evaluating AI systems not only for accuracy but also robustness when testing their cognitive capabilities.
Can Large Language Models generalize analogy solving like people can?
Nov 04, 2024



When we solve an analogy we transfer information from a known context to a new one through abstract rules and relational similarity. In people, the ability to solve analogies such as "body : feet :: table : ?" emerges in childhood, and appears to transfer easily to other domains, such as the visual domain "( : ) :: < : ?". Recent research shows that large language models (LLMs) can solve various forms of analogies. However, can LLMs generalize analogy solving to new domains like people can? To investigate this, we had children, adults, and LLMs solve a series of letter-string analogies (e.g., a b : a c :: j k : ?) in the Latin alphabet, in a near transfer domain (Greek alphabet), and a far transfer domain (list of symbols). As expected, children and adults easily generalized their knowledge to unfamiliar domains, whereas LLMs did not. This key difference between human and AI performance is evidence that these LLMs still struggle with robust human-like analogical transfer.
Imagining and building wise machines: The centrality of AI metacognition
Nov 04, 2024


Recent advances in artificial intelligence (AI) have produced systems capable of increasingly sophisticated performance on cognitive tasks. However, AI systems still struggle in critical ways: unpredictable and novel environments (robustness), lack of transparency in their reasoning (explainability), challenges in communication and commitment (cooperation), and risks due to potential harmful actions (safety). We argue that these shortcomings stem from one overarching failure: AI systems lack wisdom. Drawing from cognitive and social sciences, we define wisdom as the ability to navigate intractable problems - those that are ambiguous, radically uncertain, novel, chaotic, or computationally explosive - through effective task-level and metacognitive strategies. While AI research has focused on task-level strategies, metacognition - the ability to reflect on and regulate one's thought processes - is underdeveloped in AI systems. In humans, metacognitive strategies such as recognizing the limits of one's knowledge, considering diverse perspectives, and adapting to context are essential for wise decision-making. We propose that integrating metacognitive capabilities into AI systems is crucial for enhancing their robustness, explainability, cooperation, and safety. By focusing on developing wise AI, we suggest an alternative to aligning AI with specific human values - a task fraught with conceptual and practical difficulties. Instead, wise AI systems can thoughtfully navigate complex situations, account for diverse human values, and avoid harmful actions. We discuss potential approaches to building wise AI, including benchmarking metacognitive abilities and training AI systems to employ wise reasoning. Prioritizing metacognition in AI research will lead to systems that act not only intelligently but also wisely in complex, real-world situations.
Using Counterfactual Tasks to Evaluate the Generality of Analogical Reasoning in Large Language Models
Feb 14, 2024



Large language models (LLMs) have performed well on several reasoning benchmarks, including ones that test analogical reasoning abilities. However, it has been debated whether they are actually performing humanlike abstract reasoning or instead employing less general processes that rely on similarity to what has been seen in their training data. Here we investigate the generality of analogy-making abilities previously claimed for LLMs (Webb, Holyoak, & Lu, 2023). We take one set of analogy problems used to evaluate LLMs and create a set of "counterfactual" variants-versions that test the same abstract reasoning abilities but that are likely dissimilar from any pre-training data. We test humans and three GPT models on both the original and counterfactual problems, and show that, while the performance of humans remains high for all the problems, the GPT models' performance declines sharply on the counterfactual set. This work provides evidence that, despite previously reported successes of LLMs on analogical reasoning, these models lack the robustness and generality of human analogy-making.
Perspectives on the State and Future of Deep Learning - 2023
Dec 19, 2023The goal of this series is to chronicle opinions and issues in the field of machine learning as they stand today and as they change over time. The plan is to host this survey periodically until the AI singularity paperclip-frenzy-driven doomsday, keeping an updated list of topical questions and interviewing new community members for each edition. In this issue, we probed people's opinions on interpretable AI, the value of benchmarking in modern NLP, the state of progress towards understanding deep learning, and the future of academia.
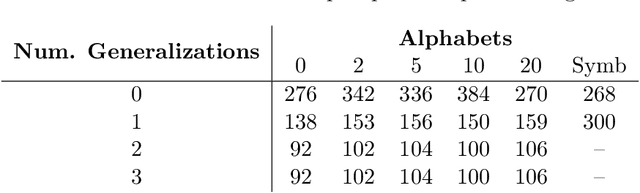
Comparing Humans, GPT-4, and GPT-4V On Abstraction and Reasoning Tasks
Nov 26, 2023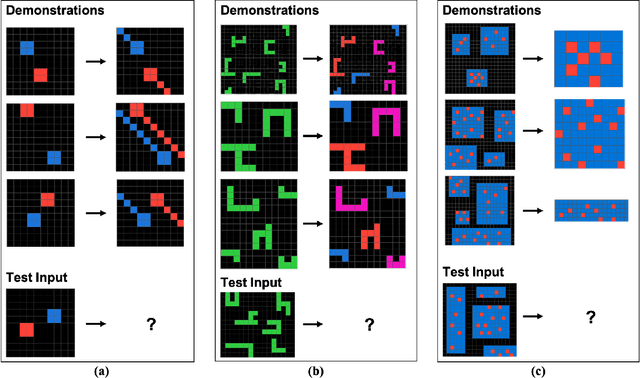
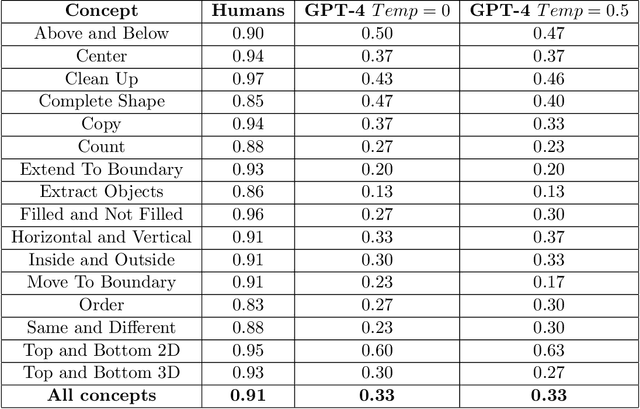

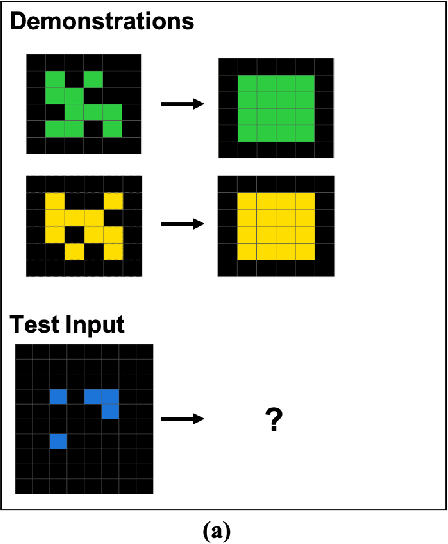
We explore the abstract reasoning abilities of text-only and multimodal versions of GPT-4, using the ConceptARC benchmark [10], which is designed to evaluate robust understanding and reasoning with core-knowledge concepts. We extend the work of Moskvichev et al. [10] by evaluating GPT-4 on more detailed, one-shot prompting (rather than simple, zero-shot prompts) with text versions of ConceptARC tasks, and by evaluating GPT-4V, the multimodal version of GPT-4, on zero- and one-shot prompts using image versions of the simplest tasks. Our experimental results support the conclusion that neither version of GPT-4 has developed robust abstraction abilities at humanlike levels.
The ConceptARC Benchmark: Evaluating Understanding and Generalization in the ARC Domain
May 11, 2023



The abilities to form and abstract concepts is key to human intelligence, but such abilities remain lacking in state-of-the-art AI systems. There has been substantial research on conceptual abstraction in AI, particularly using idealized domains such as Raven's Progressive Matrices and Bongard problems, but even when AI systems succeed on such problems, the systems are rarely evaluated in depth to see if they have actually grasped the concepts they are meant to capture. In this paper we describe an in-depth evaluation benchmark for the Abstraction and Reasoning Corpus (ARC), a collection of few-shot abstraction and analogy problems developed by Chollet [2019]. In particular, we describe ConceptARC, a new, publicly available benchmark in the ARC domain that systematically assesses abstraction and generalization abilities on a number of basic spatial and semantic concepts. ConceptARC differs from the original ARC dataset in that it is specifically organized around "concept groups" -- sets of problems that focus on specific concepts and that are vary in complexity and level of abstraction. We report results on testing humans on this benchmark as well as three machine solvers: the top two programs from a 2021 ARC competition and OpenAI's GPT-4. Our results show that humans substantially outperform the machine solvers on this benchmark, showing abilities to abstract and generalize concepts that are not yet captured by AI systems. We believe that this benchmark will spur improvements in the development of AI systems for conceptual abstraction and in the effective evaluation of such systems.
Gathering Strength, Gathering Storms: The One Hundred Year Study on Artificial Intelligence (AI100) 2021 Study Panel Report
Oct 27, 2022In September 2021, the "One Hundred Year Study on Artificial Intelligence" project (AI100) issued the second report of its planned long-term periodic assessment of artificial intelligence (AI) and its impact on society. It was written by a panel of 17 study authors, each of whom is deeply rooted in AI research, chaired by Michael Littman of Brown University. The report, entitled "Gathering Strength, Gathering Storms," answers a set of 14 questions probing critical areas of AI development addressing the major risks and dangers of AI, its effects on society, its public perception and the future of the field. The report concludes that AI has made a major leap from the lab to people's lives in recent years, which increases the urgency to understand its potential negative effects. The questions were developed by the AI100 Standing Committee, chaired by Peter Stone of the University of Texas at Austin, consisting of a group of AI leaders with expertise in computer science, sociology, ethics, economics, and other disciplines.
Embodied, Situated, and Grounded Intelligence: Implications for AI
Oct 24, 2022In April of 2022, the Santa Fe Institute hosted a workshop on embodied, situated, and grounded intelligence as part of the Institute's Foundations of Intelligence project. The workshop brought together computer scientists, psychologists, philosophers, social scientists, and others to discuss the science of embodiment and related issues in human intelligence, and its implications for building robust, human-level AI. In this report, we summarize each of the talks and the subsequent discussions. We also draw out a number of key themes and identify important frontiers for future research.