 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Spatio-Temporal Summarization using Information Based Fusion
Oct 02, 2023



In the era of burgeoning data generation, managing and storing large-scale time-varying datasets poses significant challenges. With the rise of supercomputing capabilities, the volume of data produced has soared, intensifying storage and I/O overheads. To address this issue, we propose a dynamic spatio-temporal data summarization technique that identifies informative features in key timesteps and fuses less informative ones. This approach minimizes storage requirements while preserving data dynamics. Unlike existing methods, our method retains both raw and summarized timesteps, ensuring a comprehensive view of information changes over time. We utilize information-theoretic measures to guide the fusion process, resulting in a visual representation that captures essential data patterns. We demonstrate the versatility of our technique across diverse datasets, encompassing particle-based flow simulations, security and surveillance applications, and biological cell interactions within the immune system. Our research significantly contributes to the realm of data management, introducing enhanced efficiency and deeper insights across diverse multidisciplinary domains. We provide a streamlined approach for handling massive datasets that can be applied to in situ analysis as well as post hoc analysis. This not only addresses the escalating challenges of data storage and I/O overheads but also unlocks the potential for informed decision-making. Our method empowers researchers and experts to explore essential temporal dynamics while minimizing storage requirements, thereby fostering a more effective and intuitive understanding of complex data behaviors.
Embodied, Situated, and Grounded Intelligence: Implications for AI
Oct 24, 2022In April of 2022, the Santa Fe Institute hosted a workshop on embodied, situated, and grounded intelligence as part of the Institute's Foundations of Intelligence project. The workshop brought together computer scientists, psychologists, philosophers, social scientists, and others to discuss the science of embodiment and related issues in human intelligence, and its implications for building robust, human-level AI. In this report, we summarize each of the talks and the subsequent discussions. We also draw out a number of key themes and identify important frontiers for future research.
Frontiers in Collective Intelligence: A Workshop Report
Dec 13, 2021In August of 2021, the Santa Fe Institute hosted a workshop on collective intelligence as part of its Foundations of Intelligence project. This project seeks to advance the field of artificial intelligence by promoting interdisciplinary research on the nature of intelligence. The workshop brought together computer scientists, biologists, philosophers, social scientists, and others to share their insights about how intelligence can emerge from interactions among multiple agents--whether those agents be machines, animals, or human beings. In this report, we summarize each of the talks and the subsequent discussions. We also draw out a number of key themes and identify important frontiers for future research.
Frontiers in Evolutionary Computation: A Workshop Report
Oct 20, 2021In July of 2021, the Santa Fe Institute hosted a workshop on evolutionary computation as part of its Foundations of Intelligence in Natural and Artificial Systems project. This project seeks to advance the field of artificial intelligence by promoting interdisciplinary research on the nature of intelligence. The workshop brought together computer scientists and biologists to share their insights about the nature of evolution and the future of evolutionary computation. In this report, we summarize each of the talks and the subsequent discussions. We also draw out a number of key themes and identify important frontiers for future research.
Foundations of Intelligence in Natural and Artificial Systems: A Workshop Report
May 05, 2021In March of 2021, the Santa Fe Institute hosted a workshop as part of its Foundations of Intelligence in Natural and Artificial Systems project. This project seeks to advance the field of artificial intelligence by promoting interdisciplinary research on the nature of intelligence. During the workshop, speakers from diverse disciplines gathered to develop a taxonomy of intelligence, articulating their own understanding of intelligence and how their research has furthered that understanding. In this report, we summarize the insights offered by each speaker and identify the themes that emerged during the talks and subsequent discussions.
Interdisciplinary Approaches to Understanding Artificial Intelligence's Impact on Society
Dec 11, 2020Innovations in AI have focused primarily on the questions of "what" and "how"-algorithms for finding patterns in web searches, for instance-without adequate attention to the possible harms (such as privacy, bias, or manipulation) and without adequate consideration of the societal context in which these systems operate. In part, this is driven by incentives and forces in the tech industry, where a more product-driven focus tends to drown out broader reflective concerns about potential harms and misframings. But this focus on what and how is largely a reflection of the engineering and mathematics-focused training in computer science, which emphasizes the building of tools and development of computational concepts. As a result of this tight technical focus, and the rapid, worldwide explosion in its use, AI has come with a storm of unanticipated socio-technical problems, ranging from algorithms that act in racially or gender-biased ways, get caught in feedback loops that perpetuate inequalities, or enable unprecedented behavioral monitoring surveillance that challenges the fundamental values of free, democratic societies. Given that AI is no longer solely the domain of technologists but rather of society as a whole, we need tighter coupling of computer science and those disciplines that study society and societal values.
Biologically Inspired Design Principles for Scalable, Robust, Adaptive, Decentralized Search and Automated Response (RADAR)
Feb 24, 2011

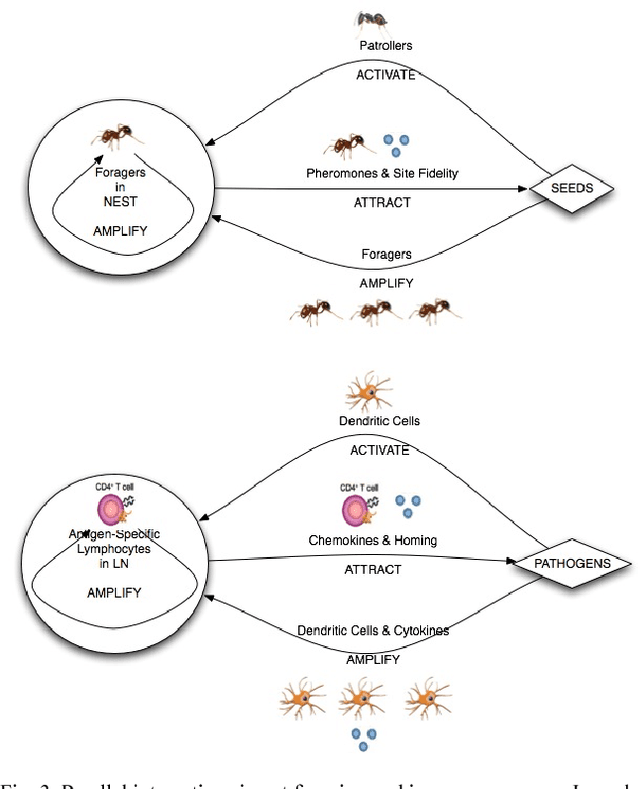
Distributed search problems are ubiquitous in Artificial Life (ALife). Many distributed search problems require identifying a rare and previously unseen event and producing a rapid response. This challenge amounts to finding and removing an unknown needle in a very large haystack. Traditional computational search models are unlikely to find, nonetheless, appropriately respond to, novel events, particularly given data distributed across multiple platforms in a variety of formats and sources with variable and unknown reliability. Biological systems have evolved solutions to distributed search and response under uncertainty. Immune systems and ant colonies efficiently scale up massively parallel search with automated response in highly dynamic environments, and both do so using distributed coordination without centralized control. These properties are relevant to ALife, where distributed, autonomous, robust and adaptive control is needed to design robot swarms, mobile computing networks, computer security systems and other distributed intelligent systems. They are also relevant for searching, tracking the spread of ideas, and understanding the impact of innovations in online social networks. We review design principles for Scalable Robust, Adaptive, Decentralized search with Automated Response (Scalable RADAR) in biology. We discuss how biological RADAR scales up efficiently, and then discuss in detail how modular search in the immune system can be mimicked or built upon in ALife. Such search mechanisms are particularly useful when components have limited capacity to communicate and social or physical distance makes long distance communication more costly.