 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREV-INR: Regularized Evidential Implicit Neural Representation for Uncertainty-Aware Volume Visualization
Jan 25, 2026Applications of Implicit Neural Representations (INRs) have emerged as a promising deep learning approach for compactly representing large volumetric datasets. These models can act as surrogates for volume data, enabling efficient storage and on-demand reconstruction via model predictions. However, conventional deterministic INRs only provide value predictions without insights into the model's prediction uncertainty or the impact of inherent noisiness in the data. This limitation can lead to unreliable data interpretation and visualization due to prediction inaccuracies in the reconstructed volume. Identifying erroneous results extracted from model-predicted data may be infeasible, as raw data may be unavailable due to its large size. To address this challenge, we introduce REV-INR, Regularized Evidential Implicit Neural Representation, which learns to predict data values accurately along with the associated coordinate-level data uncertainty and model uncertainty using only a single forward pass of the trained REV-INR during inference. By comprehensively comparing and contrasting REV-INR with existing well-established deep uncertainty estimation methods, we show that REV-INR achieves the best volume reconstruction quality with robust data (aleatoric) and model (epistemic) uncertainty estimates using the fastest inference time. Consequently, we demonstrate that REV-INR facilitates assessment of the reliability and trustworthiness of the extracted isosurfaces and volume visualization results, enabling analyses to be solely driven by model-predicted data.
Audio-to-Audio Emotion Conversion With Pitch And Duration Style Transfer
May 23, 2025Given a pair of source and reference speech recordings, audio-to-audio (A2A) style transfer involves the generation of an output speech that mimics the style characteristics of the reference while preserving the content and speaker attributes of the source. In this paper, we propose a novel framework, termed as A2A Zero-shot Emotion Style Transfer (A2A-ZEST), that enables the transfer of reference emotional attributes to the source while retaining its speaker and speech contents. The A2A-ZEST framework consists of an analysis-synthesis pipeline, where the analysis module decomposes speech into semantic tokens, speaker representations, and emotion embeddings. Using these representations, a pitch contour estimator and a duration predictor are learned. Further, a synthesis module is designed to generate speech based on the input representations and the derived factors. This entire paradigm of analysis-synthesis is trained purely in a self-supervised manner with an auto-encoding loss. For A2A emotion style transfer, the emotion embedding extracted from the reference speech along with the rest of the representations from the source speech are used in the synthesis module to generate the style translated speech. In our experiments, we evaluate the converted speech on content/speaker preservation (w.r.t. source) as well as on the effectiveness of the emotion style transfer (w.r.t. reference). The proposal, A2A-ZEST, is shown to improve over other prior works on these evaluations, thereby enabling style transfer without any parallel training data. We also illustrate the application of the proposed work for data augmentation in emotion recognition tasks.
ABHINAYA -- A System for Speech Emotion Recognition In Naturalistic Conditions Challenge
May 23, 2025Speech emotion recognition (SER) in naturalistic settings remains a challenge due to the intrinsic variability, diverse recording conditions, and class imbalance. As participants in the Interspeech Naturalistic SER Challenge which focused on these complexities, we present Abhinaya, a system integrating speech-based, text-based, and speech-text models. Our approach fine-tunes self-supervised and speech large language models (SLLM) for speech representations, leverages large language models (LLM) for textual context, and employs speech-text modeling with an SLLM to capture nuanced emotional cues. To combat class imbalance, we apply tailored loss functions and generate categorical decisions through majority voting. Despite one model not being fully trained, the Abhinaya system ranked 4th among 166 submissions. Upon completion of training, it achieved state-of-the-art performance among published results, demonstrating the effectiveness of our approach for SER in real-world conditions.
LLM supervised Pre-training for Multimodal Emotion Recognition in Conversations
Jan 20, 2025



Emotion recognition in conversations (ERC) is challenging due to the multimodal nature of the emotion expression. In this paper, we propose to pretrain a text-based recognition model from unsupervised speech transcripts with LLM guidance. These transcriptions are obtained from a raw speech dataset with a pre-trained ASR system. A text LLM model is queried to provide pseudo-labels for these transcripts, and these pseudo-labeled transcripts are subsequently used for learning an utterance level text-based emotion recognition model. We use the utterance level text embeddings for emotion recognition in conversations along with speech embeddings obtained from a recently proposed pre-trained model. A hierarchical way of training the speech-text model is proposed, keeping in mind the conversational nature of the dataset. We perform experiments on three established datasets, namely, IEMOCAP, MELD, and CMU- MOSI, where we illustrate that the proposed model improves over other benchmarks and achieves state-of-the-art results on two out of these three datasets.
Leveraging Content and Acoustic Representations for Efficient Speech Emotion Recognition
Sep 09, 2024



Speech emotion recognition (SER), the task of identifying the expression of emotion from spoken content, is challenging due to the difficulty in extracting representations that capture emotional attributes from speech. The scarcity of large labeled datasets further complicates the challenge where large models are prone to over-fitting. In this paper, we propose CARE (Content and Acoustic Representations of Emotions), where we design a dual encoding scheme which emphasizes semantic and acoustic factors of speech. While the semantic encoder is trained with the distillation of utterance-level text representation model, the acoustic encoder is trained to predict low-level frame-wise features of the speech signal. The proposed dual encoding scheme is a base-sized model trained only on unsupervised raw speech. With a simple light-weight classification model trained on the downstream task, we show that the CARE embeddings provide effective emotion recognition on a variety of tasks. We compare the proposal with several other self-supervised models as well as recent large-language model based approaches. In these evaluations, the proposed CARE model is shown to be the best performing model based on average performance across 8 diverse datasets. We also conduct several ablation studies to analyze the importance of various design choices.
Uncertainty-Informed Volume Visualization using Implicit Neural Representation
Aug 12, 2024



The increasing adoption of Deep Neural Networks (DNNs) has led to their application in many challenging scientific visualization tasks. While advanced DNNs offer impressive generalization capabilities, understanding factors such as model prediction quality, robustness, and uncertainty is crucial. These insights can enable domain scientists to make informed decisions about their data. However, DNNs inherently lack ability to estimate prediction uncertainty, necessitating new research to construct robust uncertainty-aware visualization techniques tailored for various visualization tasks. In this work, we propose uncertainty-aware implicit neural representations to model scalar field data sets effectively and comprehensively study the efficacy and benefits of estimated uncertainty information for volume visualization tasks. We evaluate the effectiveness of two principled deep uncertainty estimation techniques: (1) Deep Ensemble and (2) Monte Carlo Dropout (MCDropout). These techniques enable uncertainty-informed volume visualization in scalar field data sets. Our extensive exploration across multiple data sets demonstrates that uncertainty-aware models produce informative volume visualization results. Moreover, integrating prediction uncertainty enhances the trustworthiness of our DNN model, making it suitable for robustly analyzing and visualizing real-world scientific volumetric data sets.
Uncertainty-Aware Deep Neural Representations for Visual Analysis of Vector Field Data
Jul 23, 2024



The widespread use of Deep Neural Networks (DNNs) has recently resulted in their application to challenging scientific visualization tasks. While advanced DNNs demonstrate impressive generalization abilities, understanding factors like prediction quality, confidence, robustness, and uncertainty is crucial. These insights aid application scientists in making informed decisions. However, DNNs lack inherent mechanisms to measure prediction uncertainty, prompting the creation of distinct frameworks for constructing robust uncertainty-aware models tailored to various visualization tasks. In this work, we develop uncertainty-aware implicit neural representations to model steady-state vector fields effectively. We comprehensively evaluate the efficacy of two principled deep uncertainty estimation techniques: (1) Deep Ensemble and (2) Monte Carlo Dropout, aimed at enabling uncertainty-informed visual analysis of features within steady vector field data. Our detailed exploration using several vector data sets indicate that uncertainty-aware models generate informative visualization results of vector field features. Furthermore, incorporating prediction uncertainty improves the resilience and interpretability of our DNN model, rendering it applicable for the analysis of non-trivial vector field data sets.
Zero Shot Audio to Audio Emotion Transfer With Speaker Disentanglement
Jan 09, 2024
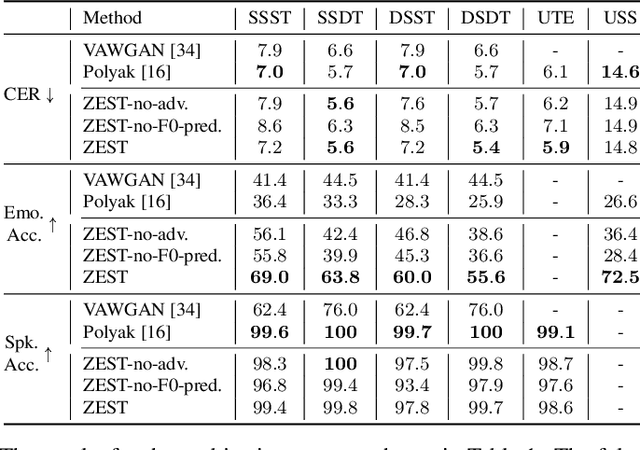


The problem of audio-to-audio (A2A) style transfer involves replacing the style features of the source audio with those from the target audio while preserving the content related attributes of the source audio. In this paper, we propose an efficient approach, termed as Zero-shot Emotion Style Transfer (ZEST), that allows the transfer of emotional content present in the given source audio with the one embedded in the target audio while retaining the speaker and speech content from the source. The proposed system builds upon decomposing speech into semantic tokens, speaker representations and emotion embeddings. Using these factors, we propose a framework to reconstruct the pitch contour of the given speech signal and train a decoder that reconstructs the speech signal. The model is trained using a self-supervision based reconstruction loss. During conversion, the emotion embedding is alone derived from the target audio, while rest of the factors are derived from the source audio. In our experiments, we show that, even without using parallel training data or labels from the source or target audio, we illustrate zero shot emotion transfer capabilities of the proposed ZEST model using objective and subjective quality evaluations.
Dynamic Spatio-Temporal Summarization using Information Based Fusion
Oct 02, 2023



In the era of burgeoning data generation, managing and storing large-scale time-varying datasets poses significant challenges. With the rise of supercomputing capabilities, the volume of data produced has soared, intensifying storage and I/O overheads. To address this issue, we propose a dynamic spatio-temporal data summarization technique that identifies informative features in key timesteps and fuses less informative ones. This approach minimizes storage requirements while preserving data dynamics. Unlike existing methods, our method retains both raw and summarized timesteps, ensuring a comprehensive view of information changes over time. We utilize information-theoretic measures to guide the fusion process, resulting in a visual representation that captures essential data patterns. We demonstrate the versatility of our technique across diverse datasets, encompassing particle-based flow simulations, security and surveillance applications, and biological cell interactions within the immune system. Our research significantly contributes to the realm of data management, introducing enhanced efficiency and deeper insights across diverse multidisciplinary domains. We provide a streamlined approach for handling massive datasets that can be applied to in situ analysis as well as post hoc analysis. This not only addresses the escalating challenges of data storage and I/O overheads but also unlocks the potential for informed decision-making. Our method empowers researchers and experts to explore essential temporal dynamics while minimizing storage requirements, thereby fostering a more effective and intuitive understanding of complex data behaviors.
HCAM -- Hierarchical Cross Attention Model for Multi-modal Emotion Recognition
Apr 14, 2023



Emotion recognition in conversations is challenging due to the multi-modal nature of the emotion expression. We propose a hierarchical cross-attention model (HCAM) approach to multi-modal emotion recognition using a combination of recurrent and co-attention neural network models. The input to the model consists of two modalities, i) audio data, processed through a learnable wav2vec approach and, ii) text data represented using a bidirectional encoder representations from transformers (BERT) model. The audio and text representations are processed using a set of bi-directional recurrent neural network layers with self-attention that converts each utterance in a given conversation to a fixed dimensional embedding. In order to incorporate contextual knowledge and the information across the two modalities, the audio and text embeddings are combined using a co-attention layer that attempts to weigh the utterance level embeddings relevant to the task of emotion recognition. The neural network parameters in the audio layers, text layers as well as the multi-modal co-attention layers, are hierarchically trained for the emotion classification task. We perform experiments on three established datasets namely, IEMOCAP, MELD and CMU-MOSI, where we illustrate that the proposed model improves significantly over other benchmarks and helps achieve state-of-art results on all these datasets.