 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeULTRAS -- Unified Learning of Transformer Representations for Audio and Speech Signals
Apr 08, 2026Self-supervised learning (SSL) has driven impressive advances in speech processing by adopting time-domain prediction objectives, while audio representation learning frameworks operate on time-frequency spectrograms. Models optimized for one paradigm struggle to transfer to the other, highlighting the need for a joint framework. We propose Unified Learning of Transformer Representations for Audio and Speech (ULTRAS), where the masking and predictive modeling is performed over long patches of the data. The model, based on the transformer architecture, encodes spectral-patches of log-mel spectrogram features. The predictive modeling of masked segments is performed on spectral and temporal targets using a combined loss-function, forcing the representations to encode time and frequency traits. Experiments are performed on a variety of speech and audio tasks, where we illustrate that the ULTRAS framework achieves improved performance over other established baselines.
Benchmarking Speech Systems for Frontline Health Conversations: The DISPLACE-M Challenge
Mar 05, 2026The DIarization and Speech Processing for LAnguage understanding in Conversational Environments - Medical (DISPLACE-M) challenge introduces a conversational AI benchmark for understanding goal-oriented, real-world medical dialogues. The challenge addresses multi-speaker interactions between frontline health workers and care seekers, characterized by spontaneous, noisy and overlapping speech. As part of the challenge, medical conversational dataset comprising 40 hours of development and 15 hours of blind evaluation recordings was released. We provided baseline systems across 4 tasks - speaker diarization, automatic speech recognition, topic identification and dialogue summarization - to enable consistent benchmarking. System performance is evaluated using diarization error rate (DER), time-constrained minimum-permutation word error rate (tcpWER) and ROUGE-L. This paper describes the Phase-I evaluation - data, tasks and baseline systems - along with the summary of the evaluation results.
A Mixture-of-Experts Model for Multimodal Emotion Recognition in Conversations
Feb 26, 2026Emotion Recognition in Conversations (ERC) presents unique challenges, requiring models to capture the temporal flow of multi-turn dialogues and to effectively integrate cues from multiple modalities. We propose Mixture of Speech-Text Experts for Recognition of Emotions (MiSTER-E), a modular Mixture-of-Experts (MoE) framework designed to decouple two core challenges in ERC: modality-specific context modeling and multimodal information fusion. MiSTER-E leverages large language models (LLMs) fine-tuned for both speech and text to provide rich utterance-level embeddings, which are then enhanced through a convolutional-recurrent context modeling layer. The system integrates predictions from three experts-speech-only, text-only, and cross-modal-using a learned gating mechanism that dynamically weighs their outputs. To further encourage consistency and alignment across modalities, we introduce a supervised contrastive loss between paired speech-text representations and a KL-divergence-based regulariza-tion across expert predictions. Importantly, MiSTER-E does not rely on speaker identity at any stage. Experiments on three benchmark datasets-IEMOCAP, MELD, and MOSI-show that our proposal achieves 70.9%, 69.5%, and 87.9% weighted F1-scores respectively, outperforming several baseline speech-text ERC systems. We also provide various ablations to highlight the contributions made in the proposed approach.
Audio-to-Audio Emotion Conversion With Pitch And Duration Style Transfer
May 23, 2025Given a pair of source and reference speech recordings, audio-to-audio (A2A) style transfer involves the generation of an output speech that mimics the style characteristics of the reference while preserving the content and speaker attributes of the source. In this paper, we propose a novel framework, termed as A2A Zero-shot Emotion Style Transfer (A2A-ZEST), that enables the transfer of reference emotional attributes to the source while retaining its speaker and speech contents. The A2A-ZEST framework consists of an analysis-synthesis pipeline, where the analysis module decomposes speech into semantic tokens, speaker representations, and emotion embeddings. Using these representations, a pitch contour estimator and a duration predictor are learned. Further, a synthesis module is designed to generate speech based on the input representations and the derived factors. This entire paradigm of analysis-synthesis is trained purely in a self-supervised manner with an auto-encoding loss. For A2A emotion style transfer, the emotion embedding extracted from the reference speech along with the rest of the representations from the source speech are used in the synthesis module to generate the style translated speech. In our experiments, we evaluate the converted speech on content/speaker preservation (w.r.t. source) as well as on the effectiveness of the emotion style transfer (w.r.t. reference). The proposal, A2A-ZEST, is shown to improve over other prior works on these evaluations, thereby enabling style transfer without any parallel training data. We also illustrate the application of the proposed work for data augmentation in emotion recognition tasks.
ABHINAYA -- A System for Speech Emotion Recognition In Naturalistic Conditions Challenge
May 23, 2025Speech emotion recognition (SER) in naturalistic settings remains a challenge due to the intrinsic variability, diverse recording conditions, and class imbalance. As participants in the Interspeech Naturalistic SER Challenge which focused on these complexities, we present Abhinaya, a system integrating speech-based, text-based, and speech-text models. Our approach fine-tunes self-supervised and speech large language models (SLLM) for speech representations, leverages large language models (LLM) for textual context, and employs speech-text modeling with an SLLM to capture nuanced emotional cues. To combat class imbalance, we apply tailored loss functions and generate categorical decisions through majority voting. Despite one model not being fully trained, the Abhinaya system ranked 4th among 166 submissions. Upon completion of training, it achieved state-of-the-art performance among published results, demonstrating the effectiveness of our approach for SER in real-world conditions.
Benchmarking and Confidence Evaluation of LALMs For Temporal Reasoning
May 19, 2025The popular success of text-based large language models (LLM) has streamlined the attention of the multimodal community to combine other modalities like vision and audio along with text to achieve similar multimodal capabilities. In this quest, large audio language models (LALMs) have to be evaluated on reasoning related tasks which are different from traditional classification or generation tasks. Towards this goal, we propose a novel dataset called temporal reasoning evaluation of audio (TREA). We benchmark open-source LALMs and observe that they are consistently behind human capabilities on the tasks in the TREA dataset. While evaluating LALMs, we also propose an uncertainty metric, which computes the invariance of the model to semantically identical perturbations of the input. Our analysis shows that the accuracy and uncertainty metrics are not necessarily correlated and thus, points to a need for wholesome evaluation of LALMs for high-stakes applications.
Spoken Language Understanding on Unseen Tasks With In-Context Learning
May 12, 2025Spoken language understanding (SLU) tasks involve diverse skills that probe the information extraction, classification and/or generation capabilities of models. In this setting, task-specific training data may not always be available. While traditional task-specific SLU models are unable to cater to such requirements, the speech-text large language models (LLMs) offer a promising alternative with emergent abilities. However, out of-the-box, our evaluations indicate that the zero/few-shot performance of prominent open-source speech-text LLMs on SLU tasks are not up to the mark. In this paper, we introduce a novel approach to robust task-agnostic fine-tuning using randomized class labels. With this proposed fine-tuning, we illustrate that the performance of the speech-text LLMs on an unseen task is significantly improved over standard approaches. Critically, the proposed approach avoids the requirement of task-specific data annotations for enabling new tasks in speech-text LLMs.
LLM supervised Pre-training for Multimodal Emotion Recognition in Conversations
Jan 20, 2025



Emotion recognition in conversations (ERC) is challenging due to the multimodal nature of the emotion expression. In this paper, we propose to pretrain a text-based recognition model from unsupervised speech transcripts with LLM guidance. These transcriptions are obtained from a raw speech dataset with a pre-trained ASR system. A text LLM model is queried to provide pseudo-labels for these transcripts, and these pseudo-labeled transcripts are subsequently used for learning an utterance level text-based emotion recognition model. We use the utterance level text embeddings for emotion recognition in conversations along with speech embeddings obtained from a recently proposed pre-trained model. A hierarchical way of training the speech-text model is proposed, keeping in mind the conversational nature of the dataset. We perform experiments on three established datasets, namely, IEMOCAP, MELD, and CMU- MOSI, where we illustrate that the proposed model improves over other benchmarks and achieves state-of-the-art results on two out of these three datasets.
Uncovering the role of semantic and acoustic cues in normal and dichotic listening
Nov 18, 2024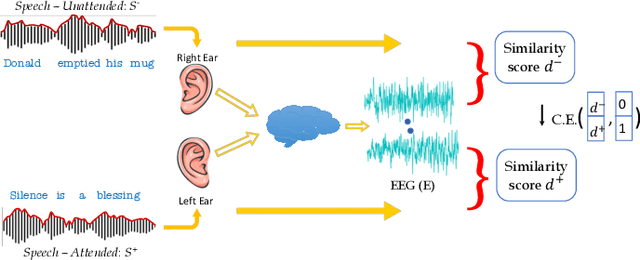
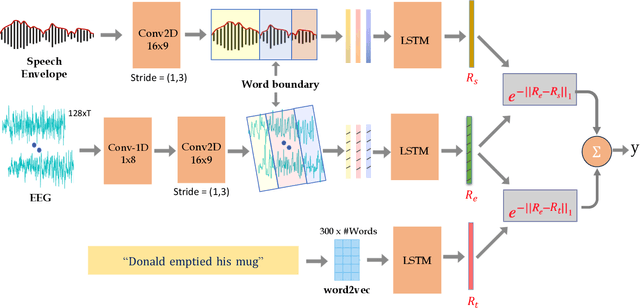
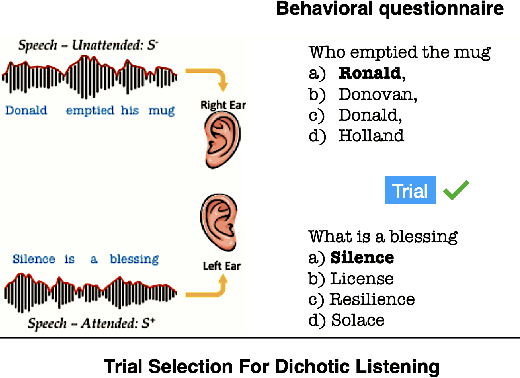
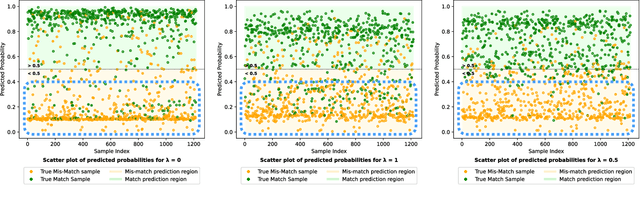
Despite extensive research, the precise role of acoustic and semantic cues in complex speech perception tasks remains unclear. In this study, we propose a paradigm to understand the encoding of these cues in electroencephalogram (EEG) data, using match-mismatch (MM) classification task. The MM task involves determining whether the stimulus and response correspond to each other or not. We design a multi-modal sequence model, based on long short term memory (LSTM) architecture, to perform the MM task. The model is input with acoustic stimulus (derived from the speech envelope), semantic stimulus (derived from textual representations of the speech content), and neural response (derived from the EEG data). Our experiments are performed on two separate conditions, i) natural passive listening condition and, ii) an auditory attention based dichotic listening condition. Using the MM task as the analysis framework, we observe that - a) speech perception is fragmented based on word boundaries, b) acoustic and semantic cues offer similar levels of MM task performance in natural listening conditions, and c) semantic cues offer significantly improved MM classification over acoustic cues in dichotic listening task. Further, the study provides evidence of right ear advantage in dichotic listening conditions.
Gradient-free Post-hoc Explainability Using Distillation Aided Learnable Approach
Sep 17, 2024



The recent advancements in artificial intelligence (AI), with the release of several large models having only query access, make a strong case for explainability of deep models in a post-hoc gradient free manner. In this paper, we propose a framework, named distillation aided explainability (DAX), that attempts to generate a saliency-based explanation in a model agnostic gradient free application. The DAX approach poses the problem of explanation in a learnable setting with a mask generation network and a distillation network. The mask generation network learns to generate the multiplier mask that finds the salient regions of the input, while the student distillation network aims to approximate the local behavior of the black-box model. We propose a joint optimization of the two networks in the DAX framework using the locally perturbed input samples, with the targets derived from input-output access to the black-box model. We extensively evaluate DAX across different modalities (image and audio), in a classification setting, using a diverse set of evaluations (intersection over union with ground truth, deletion based and subjective human evaluation based measures) and benchmark it with respect to $9$ different methods. In these evaluations, the DAX significantly outperforms the existing approaches on all modalities and evaluation metrics.