 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering the role of semantic and acoustic cues in normal and dichotic listening
Nov 18, 2024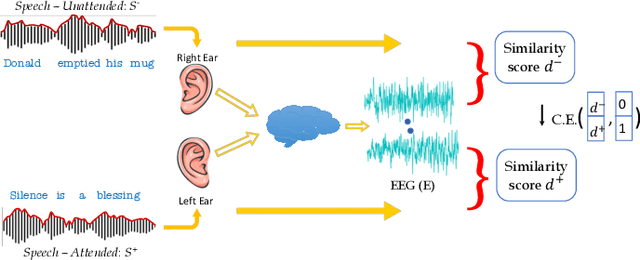
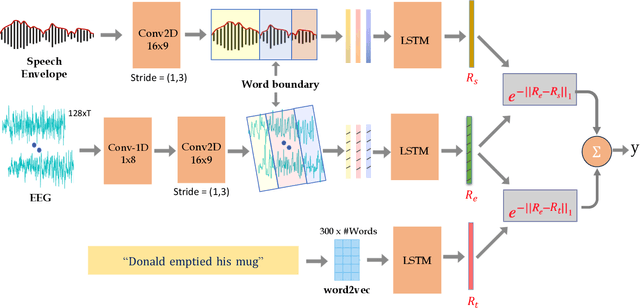
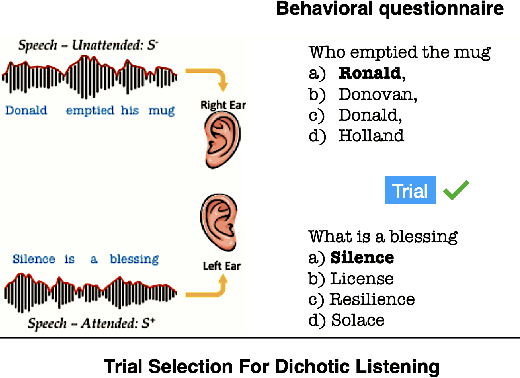
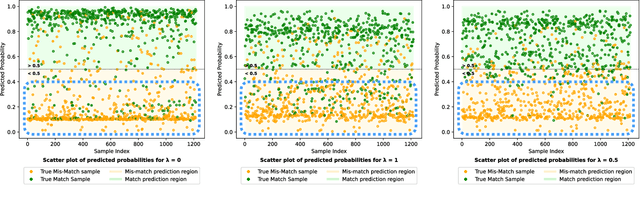
Despite extensive research, the precise role of acoustic and semantic cues in complex speech perception tasks remains unclear. In this study, we propose a paradigm to understand the encoding of these cues in electroencephalogram (EEG) data, using match-mismatch (MM) classification task. The MM task involves determining whether the stimulus and response correspond to each other or not. We design a multi-modal sequence model, based on long short term memory (LSTM) architecture, to perform the MM task. The model is input with acoustic stimulus (derived from the speech envelope), semantic stimulus (derived from textual representations of the speech content), and neural response (derived from the EEG data). Our experiments are performed on two separate conditions, i) natural passive listening condition and, ii) an auditory attention based dichotic listening condition. Using the MM task as the analysis framework, we observe that - a) speech perception is fragmented based on word boundaries, b) acoustic and semantic cues offer similar levels of MM task performance in natural listening conditions, and c) semantic cues offer significantly improved MM classification over acoustic cues in dichotic listening task. Further, the study provides evidence of right ear advantage in dichotic listening conditions.
Enhancing the EEG Speech Match Mismatch Tasks With Word Boundaries
Jul 01, 2023Recent studies have shown that the underlying neural mechanisms of human speech comprehension can be analyzed using a match-mismatch classification of the speech stimulus and the neural response. However, such studies have been conducted for fixed-duration segments without accounting for the discrete processing of speech in the brain. In this work, we establish that word boundary information plays a significant role in sentence processing by relating EEG to its speech input. We process the speech and the EEG signals using a network of convolution layers. Then, a word boundary-based average pooling is performed on the representations, and the inter-word context is incorporated using a recurrent layer. The experiments show that the modeling accuracy can be significantly improved (match-mismatch classification accuracy) to 93% on a publicly available speech-EEG data set, while previous efforts achieved an accuracy of 65-75% for this task.