 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegoSLM: Connecting LLM with Speech Encoder using CTC Posteriors
May 16, 2025Recently, large-scale pre-trained speech encoders and Large Language Models (LLMs) have been released, which show state-of-the-art performance on a range of spoken language processing tasks including Automatic Speech Recognition (ASR). To effectively combine both models for better performance, continuous speech prompts, and ASR error correction have been adopted. However, these methods are prone to suboptimal performance or are inflexible. In this paper, we propose a new paradigm, LegoSLM, that bridges speech encoders and LLMs using the ASR posterior matrices. The speech encoder is trained to generate Connectionist Temporal Classification (CTC) posteriors over the LLM vocabulary, which are used to reconstruct pseudo-audio embeddings by computing a weighted sum of the LLM input embeddings. These embeddings are concatenated with text embeddings in the LLM input space. Using the well-performing USM and Gemma models as an example, we demonstrate that our proposed LegoSLM method yields good performance on both ASR and speech translation tasks. By connecting USM with Gemma models, we can get an average of 49% WERR over the USM-CTC baseline on 8 MLS testsets. The trained model also exhibits modularity in a range of settings -- after fine-tuning the Gemma model weights, the speech encoder can be switched and combined with the LLM in a zero-shot fashion. Additionally, we propose to control the decode-time influence of the USM and LLM using a softmax temperature, which shows effectiveness in domain adaptation.
STAB: Speech Tokenizer Assessment Benchmark
Sep 04, 2024
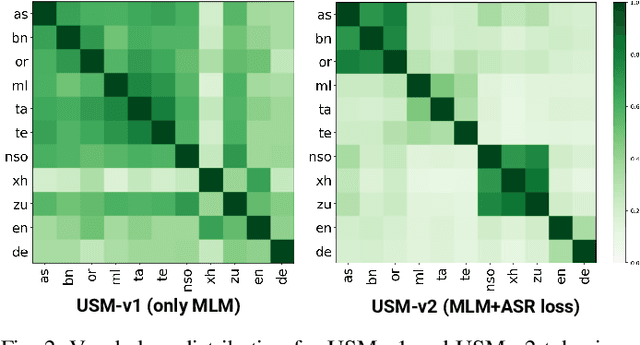
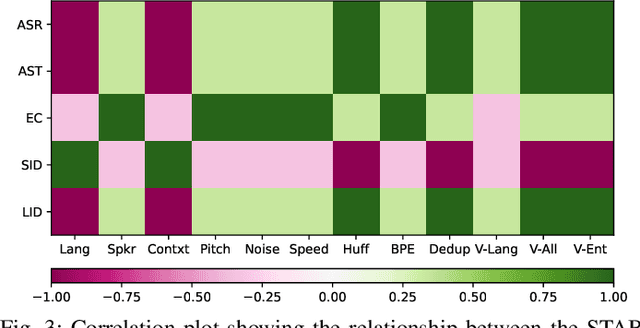
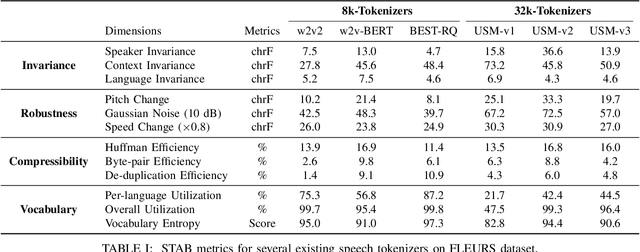
Representing speech as discrete tokens provides a framework for transforming speech into a format that closely resembles text, thus enabling the use of speech as an input to the widely successful large language models (LLMs). Currently, while several speech tokenizers have been proposed, there is ambiguity regarding the properties that are desired from a tokenizer for specific downstream tasks and its overall generalizability. Evaluating the performance of tokenizers across different downstream tasks is a computationally intensive effort that poses challenges for scalability. To circumvent this requirement, we present STAB (Speech Tokenizer Assessment Benchmark), a systematic evaluation framework designed to assess speech tokenizers comprehensively and shed light on their inherent characteristics. This framework provides a deeper understanding of the underlying mechanisms of speech tokenization, thereby offering a valuable resource for expediting the advancement of future tokenizer models and enabling comparative analysis using a standardized benchmark. We evaluate the STAB metrics and correlate this with downstream task performance across a range of speech tasks and tokenizer choices.
O-1: Self-training with Oracle and 1-best Hypothesis
Aug 14, 2023
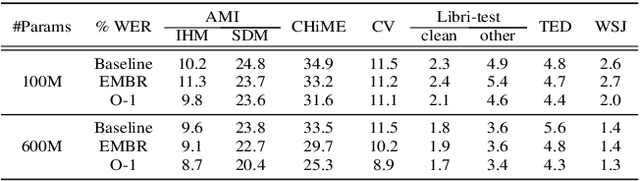

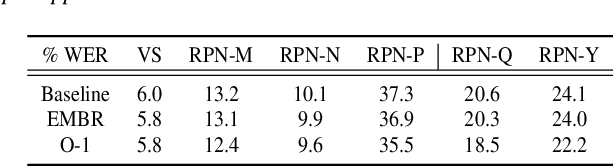
We introduce O-1, a new self-training objective to reduce training bias and unify training and evaluation metrics for speech recognition. O-1 is a faster variant of Expected Minimum Bayes Risk (EMBR), that boosts the oracle hypothesis and can accommodate both supervised and unsupervised data. We demonstrate the effectiveness of our approach in terms of recognition on publicly available SpeechStew datasets and a large-scale, in-house data set. On Speechstew, the O-1 objective closes the gap between the actual and oracle performance by 80\% relative compared to EMBR which bridges the gap by 43\% relative. O-1 achieves 13\% to 25\% relative improvement over EMBR on the various datasets that SpeechStew comprises of, and a 12\% relative gap reduction with respect to the oracle WER over EMBR training on the in-house dataset. Overall, O-1 results in a 9\% relative improvement in WER over EMBR, thereby speaking to the scalability of the proposed objective for large-scale datasets.
Large-scale Language Model Rescoring on Long-form Data
Jun 13, 2023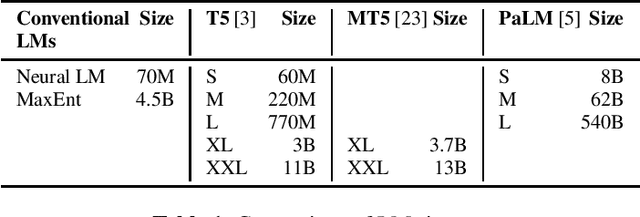
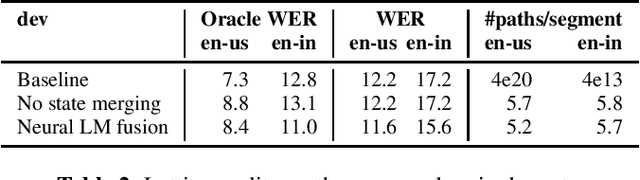


In this work, we study the impact of Large-scale Language Models (LLM) on Automated Speech Recognition (ASR) of YouTube videos, which we use as a source for long-form ASR. We demonstrate up to 8\% relative reduction in Word Error Eate (WER) on US English (en-us) and code-switched Indian English (en-in) long-form ASR test sets and a reduction of up to 30\% relative on Salient Term Error Rate (STER) over a strong first-pass baseline that uses a maximum-entropy based language model. Improved lattice processing that results in a lattice with a proper (non-tree) digraph topology and carrying context from the 1-best hypothesis of the previous segment(s) results in significant wins in rescoring with LLMs. We also find that the gains in performance from the combination of LLMs trained on vast quantities of available data (such as C4) and conventional neural LMs is additive and significantly outperforms a strong first-pass baseline with a maximum entropy LM.
* 5 pages, accepted in ICASSP 2023
Robust Knowledge Distillation from RNN-T Models With Noisy Training Labels Using Full-Sum Loss
Mar 10, 2023This work studies knowledge distillation (KD) and addresses its constraints for recurrent neural network transducer (RNN-T) models. In hard distillation, a teacher model transcribes large amounts of unlabelled speech to train a student model. Soft distillation is another popular KD method that distills the output logits of the teacher model. Due to the nature of RNN-T alignments, applying soft distillation between RNN-T architectures having different posterior distributions is challenging. In addition, bad teachers having high word-error-rate (WER) reduce the efficacy of KD. We investigate how to effectively distill knowledge from variable quality ASR teachers, which has not been studied before to the best of our knowledge. We show that a sequence-level KD, full-sum distillation, outperforms other distillation methods for RNN-T models, especially for bad teachers. We also propose a variant of full-sum distillation that distills the sequence discriminative knowledge of the teacher leading to further improvement in WER. We conduct experiments on public datasets namely SpeechStew and LibriSpeech, and on in-house production data.
Modular Hybrid Autoregressive Transducer
Oct 31, 2022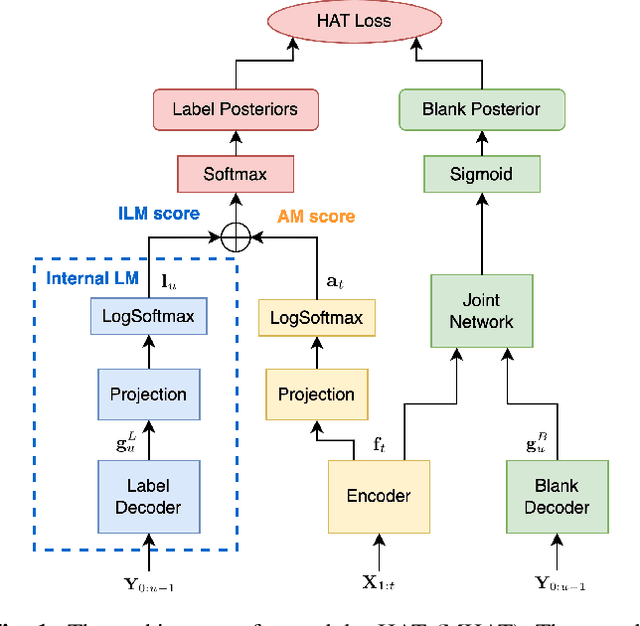
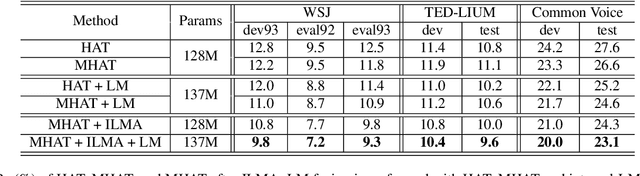
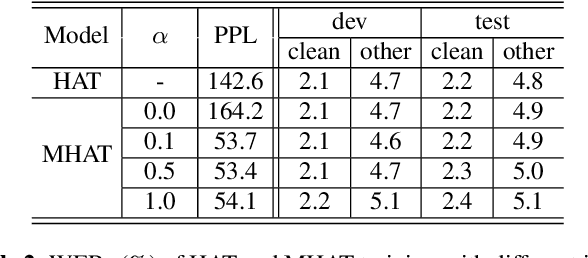
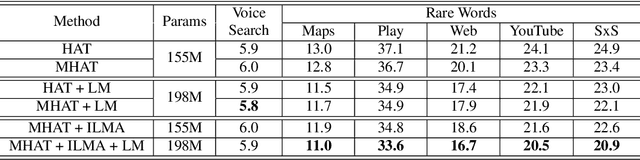
Text-only adaptation of a transducer model remains challenging for end-to-end speech recognition since the transducer has no clearly separated acoustic model (AM), language model (LM) or blank model. In this work, we propose a modular hybrid autoregressive transducer (MHAT) that has structurally separated label and blank decoders to predict label and blank distributions, respectively, along with a shared acoustic encoder. The encoder and label decoder outputs are directly projected to AM and internal LM scores and then added to compute label posteriors. We train MHAT with an internal LM loss and a HAT loss to ensure that its internal LM becomes a standalone neural LM that can be effectively adapted to text. Moreover, text adaptation of MHAT fosters a much better LM fusion than internal LM subtraction-based methods. On Google's large-scale production data, a multi-domain MHAT adapted with 100B sentences achieves relative WER reductions of up to 12.4% without LM fusion and 21.5% with LM fusion from 400K-hour trained HAT.
* 8 pages, 1 figure, SLT 2022
Analysis of Self-Attention Head Diversity for Conformer-based Automatic Speech Recognition
Sep 13, 2022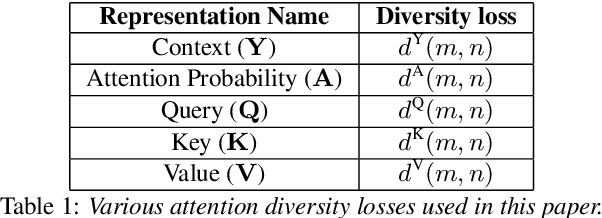
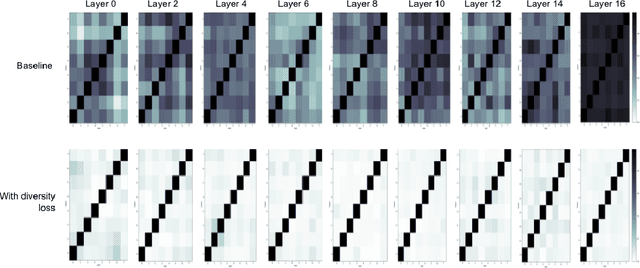
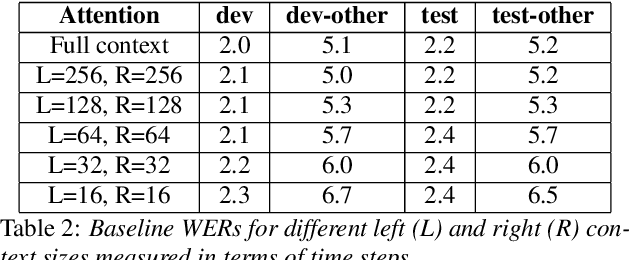
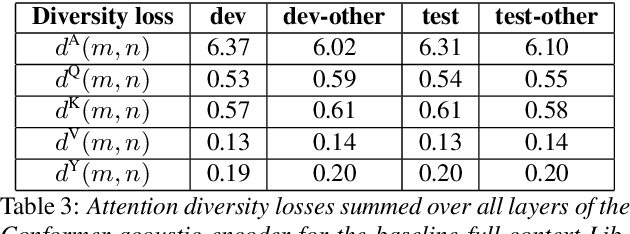
Attention layers are an integral part of modern end-to-end automatic speech recognition systems, for instance as part of the Transformer or Conformer architecture. Attention is typically multi-headed, where each head has an independent set of learned parameters and operates on the same input feature sequence. The output of multi-headed attention is a fusion of the outputs from the individual heads. We empirically analyze the diversity between representations produced by the different attention heads and demonstrate that the heads become highly correlated during the course of training. We investigate a few approaches to increasing attention head diversity, including using different attention mechanisms for each head and auxiliary training loss functions to promote head diversity. We show that introducing diversity-promoting auxiliary loss functions during training is a more effective approach, and obtain WER improvements of up to 6% relative on the Librispeech corpus. Finally, we draw a connection between the diversity of attention heads and the similarity of the gradients of head parameters.
Leveraging Unpaired Text Data for Training End-to-End Speech-to-Intent Systems
Oct 08, 2020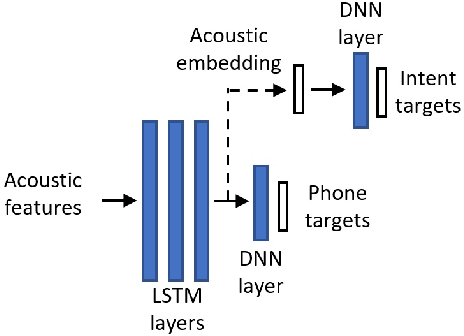

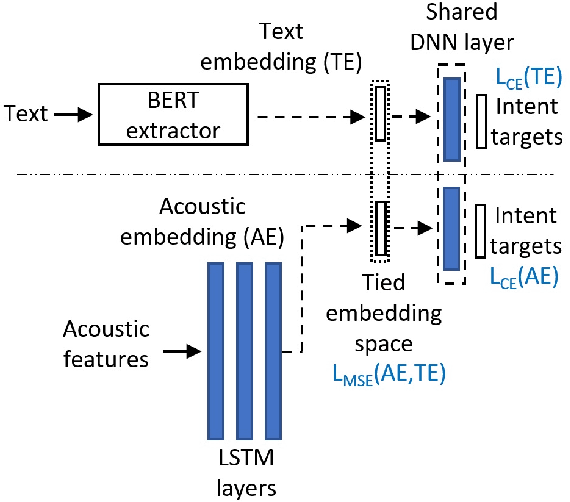
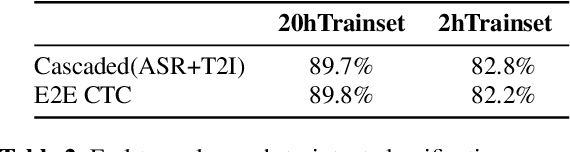
Training an end-to-end (E2E) neural network speech-to-intent (S2I) system that directly extracts intents from speech requires large amounts of intent-labeled speech data, which is time consuming and expensive to collect. Initializing the S2I model with an ASR model trained on copious speech data can alleviate data sparsity. In this paper, we attempt to leverage NLU text resources. We implemented a CTC-based S2I system that matches the performance of a state-of-the-art, traditional cascaded SLU system. We performed controlled experiments with varying amounts of speech and text training data. When only a tenth of the original data is available, intent classification accuracy degrades by 7.6% absolute. Assuming we have additional text-to-intent data (without speech) available, we investigated two techniques to improve the S2I system: (1) transfer learning, in which acoustic embeddings for intent classification are tied to fine-tuned BERT text embeddings; and (2) data augmentation, in which the text-to-intent data is converted into speech-to-intent data using a multi-speaker text-to-speech system. The proposed approaches recover 80% of performance lost due to using limited intent-labeled speech.
End-to-End Spoken Language Understanding Without Full Transcripts
Sep 30, 2020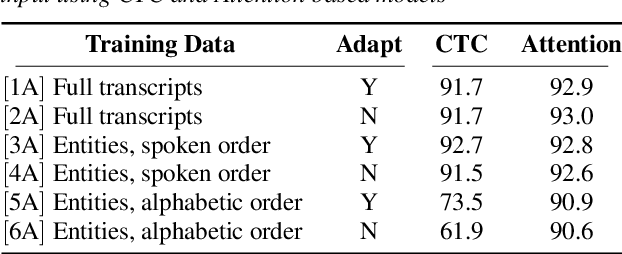
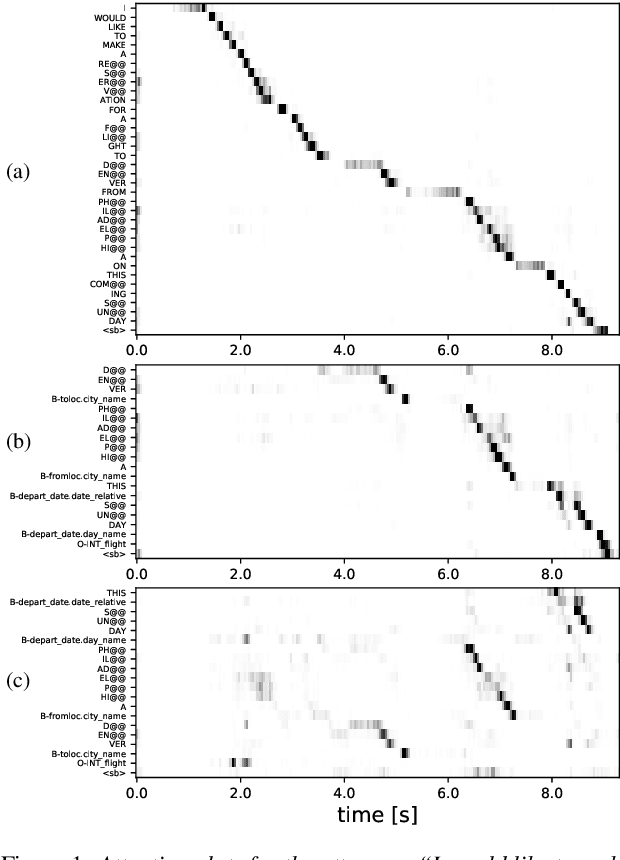

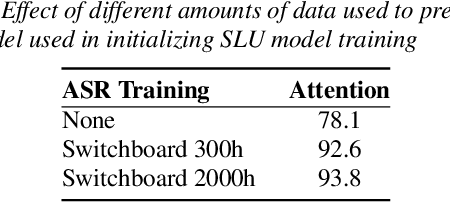
An essential component of spoken language understanding (SLU) is slot filling: representing the meaning of a spoken utterance using semantic entity labels. In this paper, we develop end-to-end (E2E) spoken language understanding systems that directly convert speech input to semantic entities and investigate if these E2E SLU models can be trained solely on semantic entity annotations without word-for-word transcripts. Training such models is very useful as they can drastically reduce the cost of data collection. We created two types of such speech-to-entities models, a CTC model and an attention-based encoder-decoder model, by adapting models trained originally for speech recognition. Given that our experiments involve speech input, these systems need to recognize both the entity label and words representing the entity value correctly. For our speech-to-entities experiments on the ATIS corpus, both the CTC and attention models showed impressive ability to skip non-entity words: there was little degradation when trained on just entities versus full transcripts. We also explored the scenario where the entities are in an order not necessarily related to spoken order in the utterance. With its ability to do re-ordering, the attention model did remarkably well, achieving only about 2% degradation in speech-to-bag-of-entities F1 score.
AVLnet: Learning Audio-Visual Language Representations from Instructional Videos
Jun 16, 2020


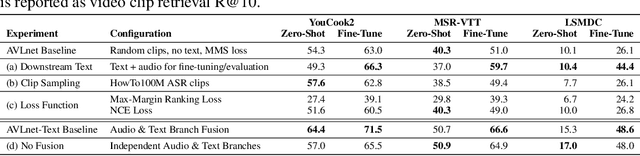
Current methods for learning visually grounded language from videos often rely on time-consuming and expensive data collection, such as human annotated textual summaries or machine generated automatic speech recognition transcripts. In this work, we introduce Audio-Video Language Network (AVLnet), a self-supervised network that learns a shared audio-visual embedding space directly from raw video inputs. We circumvent the need for annotation and instead learn audio-visual language representations directly from randomly segmented video clips and their raw audio waveforms. We train AVLnet on publicly available instructional videos and evaluate our model on video clip and language retrieval tasks on three video datasets. Our proposed model outperforms several state-of-the-art text-video baselines by up to 11.8% in a video clip retrieval task, despite operating on the raw audio instead of manually annotated text captions. Further, we show AVLnet is capable of integrating textual information, increasing its modularity and improving performance by up to 20.3% on the video clip retrieval task. Finally, we perform analysis of AVLnet's learned representations, showing our model has learned to relate visual objects with salient words and natural sounds.