 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Conformer Encoder May Reverse the Time Dimension
Oct 01, 2024We sometimes observe monotonically decreasing cross-attention weights in our Conformer-based global attention-based encoder-decoder (AED) models. Further investigation shows that the Conformer encoder internally reverses the sequence in the time dimension. We analyze the initial behavior of the decoder cross-attention mechanism and find that it encourages the Conformer encoder self-attention to build a connection between the initial frames and all other informative frames. Furthermore, we show that, at some point in training, the self-attention module of the Conformer starts dominating the output over the preceding feed-forward module, which then only allows the reversed information to pass through. We propose several methods and ideas of how this flipping can be avoided. Additionally, we investigate a novel method to obtain label-frame-position alignments by using the gradients of the label log probabilities w.r.t. the encoder input frames.
Alternating Weak Triphone/BPE Alignment Supervision from Hybrid Model Improves End-to-End ASR
Feb 23, 2024



In this paper, alternating weak triphone/BPE alignment supervision is proposed to improve end-to-end model training. Towards this end, triphone and BPE alignments are extracted using a pre-existing hybrid ASR system. Then, regularization effect is obtained by cross-entropy based intermediate auxiliary losses computed on such alignments at a mid-layer representation of the encoder for triphone alignments and at the encoder for BPE alignments. Weak supervision is achieved through strong label smoothing with parameter of 0.5. Experimental results on TED-LIUM 2 indicate that either triphone or BPE alignment based weak supervision improves ASR performance over standard CTC auxiliary loss. Moreover, their combination lowers the word error rate further. We also investigate the alternation of the two auxiliary tasks during model training, and additional performance gain is observed. Overall, the proposed techniques result in over 10% relative error rate reduction over a CTC-regularized baseline system.
Chunked Attention-based Encoder-Decoder Model for Streaming Speech Recognition
Sep 15, 2023



We study a streamable attention-based encoder-decoder model in which either the decoder, or both the encoder and decoder, operate on pre-defined, fixed-size windows called chunks. A special end-of-chunk (EOC) symbol advances from one chunk to the next chunk, effectively replacing the conventional end-of-sequence symbol. This modification, while minor, situates our model as equivalent to a transducer model that operates on chunks instead of frames, where EOC corresponds to the blank symbol. We further explore the remaining differences between a standard transducer and our model. Additionally, we examine relevant aspects such as long-form speech generalization, beam size, and length normalization. Through experiments on Librispeech and TED-LIUM-v2, and by concatenating consecutive sequences for long-form trials, we find that our streamable model maintains competitive performance compared to the non-streamable variant and generalizes very well to long-form speech.
Improving Language Model Integration for Neural Machine Translation
Jun 08, 2023The integration of language models for neural machine translation has been extensively studied in the past. It has been shown that an external language model, trained on additional target-side monolingual data, can help improve translation quality. However, there has always been the assumption that the translation model also learns an implicit target-side language model during training, which interferes with the external language model at decoding time. Recently, some works on automatic speech recognition have demonstrated that, if the implicit language model is neutralized in decoding, further improvements can be gained when integrating an external language model. In this work, we transfer this concept to the task of machine translation and compare with the most prominent way of including additional monolingual data - namely back-translation. We find that accounting for the implicit language model significantly boosts the performance of language model fusion, although this approach is still outperformed by back-translation.
Take the Hint: Improving Arabic Diacritization with Partially-Diacritized Text
Jun 06, 2023


Automatic Arabic diacritization is useful in many applications, ranging from reading support for language learners to accurate pronunciation predictor for downstream tasks like speech synthesis. While most of the previous works focused on models that operate on raw non-diacritized text, production systems can gain accuracy by first letting humans partly annotate ambiguous words. In this paper, we propose 2SDiac, a multi-source model that can effectively support optional diacritics in input to inform all predictions. We also introduce Guided Learning, a training scheme to leverage given diacritics in input with different levels of random masking. We show that the provided hints during test affect more output positions than those annotated. Moreover, experiments on two common benchmarks show that our approach i) greatly outperforms the baseline also when evaluated on non-diacritized text; and ii) achieves state-of-the-art results while reducing the parameter count by over 60%.
Robust Knowledge Distillation from RNN-T Models With Noisy Training Labels Using Full-Sum Loss
Mar 10, 2023This work studies knowledge distillation (KD) and addresses its constraints for recurrent neural network transducer (RNN-T) models. In hard distillation, a teacher model transcribes large amounts of unlabelled speech to train a student model. Soft distillation is another popular KD method that distills the output logits of the teacher model. Due to the nature of RNN-T alignments, applying soft distillation between RNN-T architectures having different posterior distributions is challenging. In addition, bad teachers having high word-error-rate (WER) reduce the efficacy of KD. We investigate how to effectively distill knowledge from variable quality ASR teachers, which has not been studied before to the best of our knowledge. We show that a sequence-level KD, full-sum distillation, outperforms other distillation methods for RNN-T models, especially for bad teachers. We also propose a variant of full-sum distillation that distills the sequence discriminative knowledge of the teacher leading to further improvement in WER. We conduct experiments on public datasets namely SpeechStew and LibriSpeech, and on in-house production data.
Improving And Analyzing Neural Speaker Embeddings for ASR
Jan 11, 2023



Neural speaker embeddings encode the speaker's speech characteristics through a DNN model and are prevalent for speaker verification tasks. However, few studies have investigated the usage of neural speaker embeddings for an ASR system. In this work, we present our efforts w.r.t integrating neural speaker embeddings into a conformer based hybrid HMM ASR system. For ASR, our improved embedding extraction pipeline in combination with the Weighted-Simple-Add integration method results in x-vector and c-vector reaching on par performance with i-vectors. We further compare and analyze different speaker embeddings. We present our acoustic model improvements obtained by switching from newbob learning rate schedule to one cycle learning schedule resulting in a ~3% relative WER reduction on Switchboard, additionally reducing the overall training time by 17%. By further adding neural speaker embeddings, we gain additional ~3% relative WER improvement on Hub5'00. Our best Conformer-based hybrid ASR system with speaker embeddings achieves 9.0% WER on Hub5'00 and Hub5'01 with training on SWB 300h.
Enhancing and Adversarial: Improve ASR with Speaker Labels
Nov 11, 2022



ASR can be improved by multi-task learning (MTL) with domain enhancing or domain adversarial training, which are two opposite objectives with the aim to increase/decrease domain variance towards domain-aware/agnostic ASR, respectively. In this work, we study how to best apply these two opposite objectives with speaker labels to improve conformer-based ASR. We also propose a novel adaptive gradient reversal layer for stable and effective adversarial training without tuning effort. Detailed analysis and experimental verification are conducted to show the optimal positions in the ASR neural network (NN) to apply speaker enhancing and adversarial training. We also explore their combination for further improvement, achieving the same performance as i-vectors plus adversarial training. Our best speaker-based MTL achieves 7\% relative improvement on the Switchboard Hub5'00 set. We also investigate the effect of such speaker-based MTL w.r.t. cleaner dataset and weaker ASR NN.
Development of Hybrid ASR Systems for Low Resource Medical Domain Conversational Telephone Speech
Oct 26, 2022



Language barriers present a great challenge in our increasingly connected and global world. Especially within the medical domain, e.g. hospital or emergency room, communication difficulties and delays may lead to malpractice and non-optimal patient care. In the HYKIST project, we consider patient-physician communication, more specifically between a German-speaking physician and an Arabic- or Vietnamese-speaking patient. Currently, a doctor can call the Triaphon service to get assistance from an interpreter in order to help facilitate communication. The HYKIST goal is to support the usually non-professional bilingual interpreter with an automatic speech translation system to improve patient care and help overcome language barriers. In this work, we present our ASR system development efforts for this conversational telephone speech translation task in the medical domain for two languages pairs, data collection, various acoustic model architectures and dialect-induced difficulties.
Improving the Training Recipe for a Robust Conformer-based Hybrid Model
Jun 26, 2022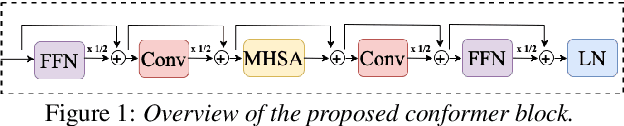
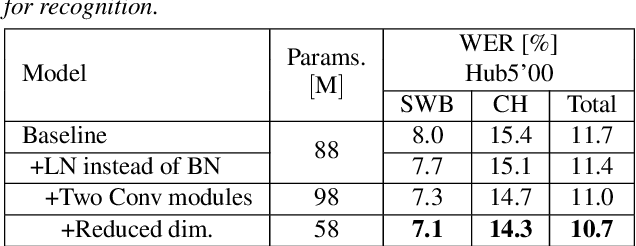

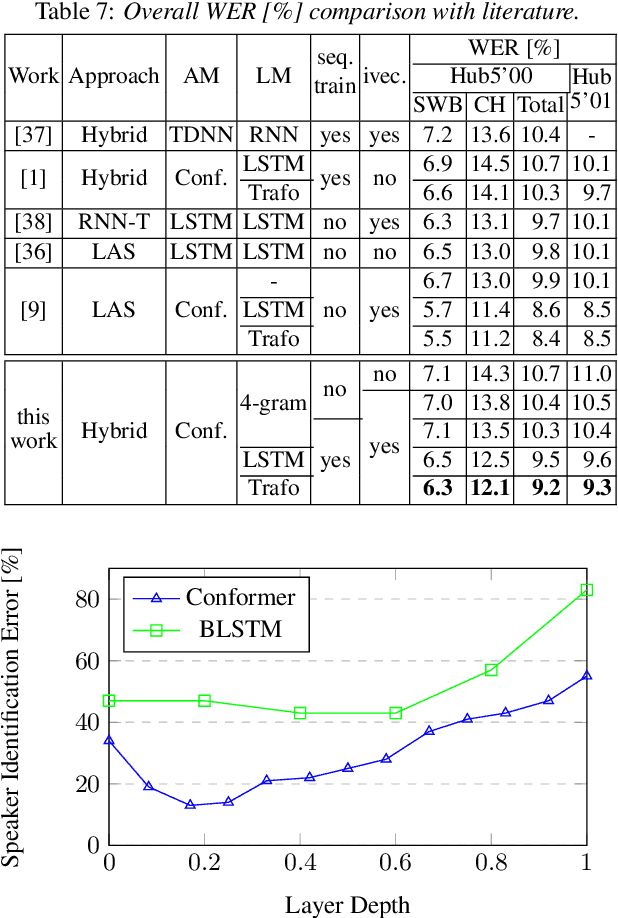
Speaker adaptation is important to build robust automatic speech recognition (ASR) systems. In this work, we investigate various methods for speaker adaptive training (SAT) based on feature-space approaches for a conformer-based acoustic model (AM) on the Switchboard 300h dataset. We propose a method, called Weighted-Simple-Add, which adds weighted speaker information vectors to the input of the multi-head self-attention module of the conformer AM. Using this method for SAT, we achieve 3.5% and 4.5% relative improvement in terms of WER on the CallHome part of Hub5'00 and Hub5'01 respectively. Moreover, we build on top of our previous work where we proposed a novel and competitive training recipe for a conformer-based hybrid AM. We extend and improve this recipe where we achieve 11% relative improvement in terms of word-error-rate (WER) on Switchboard 300h Hub5'00 dataset. We also make this recipe efficient by reducing the total number of parameters by 34% relative.