 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-Chain: Structured Visual Chain-of-Thought For Medicine
Oct 26, 2025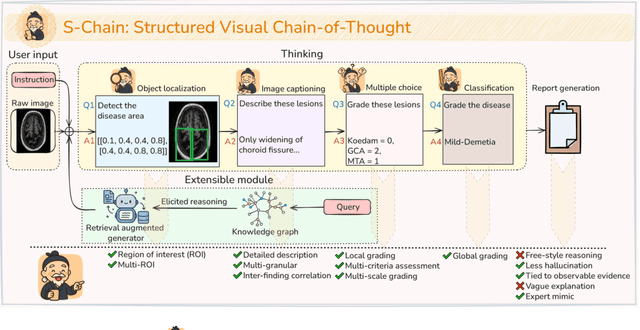
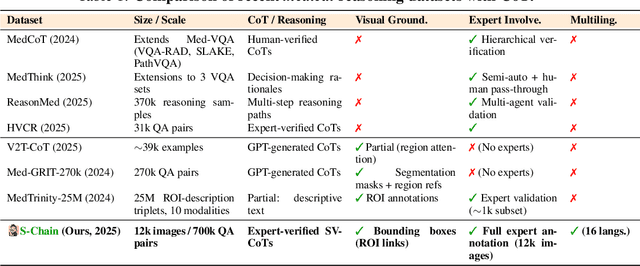
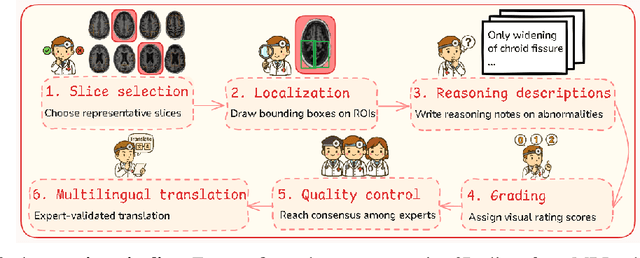
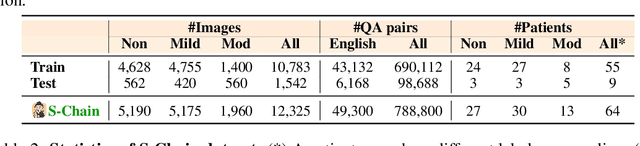
Faithful reasoning in medical vision-language models (VLMs) requires not only accurate predictions but also transparent alignment between textual rationales and visual evidence. While Chain-of-Thought (CoT) prompting has shown promise in medical visual question answering (VQA), no large-scale expert-level dataset has captured stepwise reasoning with precise visual grounding. We introduce S-Chain, the first large-scale dataset of 12,000 expert-annotated medical images with bounding boxes and structured visual CoT (SV-CoT), explicitly linking visual regions to reasoning steps. The dataset further supports 16 languages, totaling over 700k VQA pairs for broad multilingual applicability. Using S-Chain, we benchmark state-of-the-art medical VLMs (ExGra-Med, LLaVA-Med) and general-purpose VLMs (Qwen2.5-VL, InternVL2.5), showing that SV-CoT supervision significantly improves interpretability, grounding fidelity, and robustness. Beyond benchmarking, we study its synergy with retrieval-augmented generation, revealing how domain knowledge and visual grounding interact during autoregressive reasoning. Finally, we propose a new mechanism that strengthens the alignment between visual evidence and reasoning, improving both reliability and efficiency. S-Chain establishes a new benchmark for grounded medical reasoning and paves the way toward more trustworthy and explainable medical VLMs.
MultiMed-ST: Large-scale Many-to-many Multilingual Medical Speech Translation
Apr 04, 2025Multilingual speech translation (ST) in the medical domain enhances patient care by enabling efficient communication across language barriers, alleviating specialized workforce shortages, and facilitating improved diagnosis and treatment, particularly during pandemics. In this work, we present the first systematic study on medical ST, to our best knowledge, by releasing MultiMed-ST, a large-scale ST dataset for the medical domain, spanning all translation directions in five languages: Vietnamese, English, German, French, Traditional Chinese and Simplified Chinese, together with the models. With 290,000 samples, our dataset is the largest medical machine translation (MT) dataset and the largest many-to-many multilingual ST among all domains. Secondly, we present the most extensive analysis study in ST research to date, including: empirical baselines, bilingual-multilingual comparative study, end-to-end vs. cascaded comparative study, task-specific vs. multi-task sequence-to-sequence (seq2seq) comparative study, code-switch analysis, and quantitative-qualitative error analysis. All code, data, and models are available online: https://github.com/leduckhai/MultiMed-ST.
A Wearable Device Dataset for Mental Health Assessment Using Laser Doppler Flowmetry and Fluorescence Spectroscopy Sensors
Feb 03, 2025



In this study, we introduce a novel method to predict mental health by building machine learning models for a non-invasive wearable device equipped with Laser Doppler Flowmetry (LDF) and Fluorescence Spectroscopy (FS) sensors. Besides, we present the corresponding dataset to predict mental health, e.g. depression, anxiety, and stress levels via the DAS-21 questionnaire. To our best knowledge, this is the world's largest and the most generalized dataset ever collected for both LDF and FS studies. The device captures cutaneous blood microcirculation parameters, and wavelet analysis of the LDF signal extracts key rhythmic oscillations. The dataset, collected from 132 volunteers aged 18-94 from 19 countries, explores relationships between physiological features, demographics, lifestyle habits, and health conditions. We employed a variety of machine learning methods to classify stress detection, in which LightGBM is identified as the most effective model for stress detection, achieving a ROC AUC of 0.7168 and a PR AUC of 0.8852. In addition, we also incorporated Explainable Artificial Intelligence (XAI) techniques into our analysis to investigate deeper insights into the model's predictions. Our results suggest that females, younger individuals and those with a higher Body Mass Index (BMI) or heart rate have a greater likelihood of experiencing mental health conditions like stress and anxiety. All related code and data are published online: https://github.com/leduckhai/Wearable_LDF-FS.
MultiMed: Multilingual Medical Speech Recognition via Attention Encoder Decoder
Sep 21, 2024
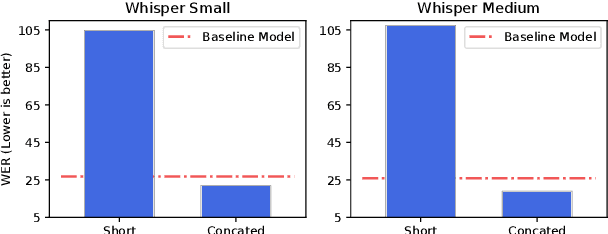


Multilingual automatic speech recognition (ASR) in the medical domain serves as a foundational task for various downstream applications such as speech translation, spoken language understanding, and voice-activated assistants. This technology enhances patient care by enabling efficient communication across language barriers, alleviating specialized workforce shortages, and facilitating improved diagnosis and treatment, particularly during pandemics. In this work, we introduce MultiMed, a collection of small-to-large end-to-end ASR models for the medical domain, spanning five languages: Vietnamese, English, German, French, and Mandarin Chinese, together with the corresponding real-world ASR dataset. To our best knowledge, MultiMed stands as the largest and the first multilingual medical ASR dataset, in terms of total duration, number of speakers, diversity of diseases, recording conditions, speaker roles, unique medical terms, accents, and ICD-10 codes. Secondly, we establish the empirical baselines, present the first reproducible study of multilinguality in medical ASR, conduct a layer-wise ablation study for end-to-end ASR training, and provide the first linguistic analysis for multilingual medical ASR. All code, data, and models are available online https://github.com/leduckhai/MultiMed/tree/master/MultiMed
wav2graph: A Framework for Supervised Learning Knowledge Graph from Speech
Aug 08, 2024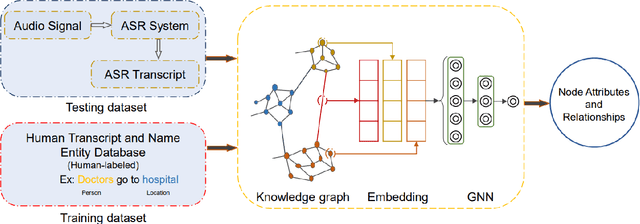
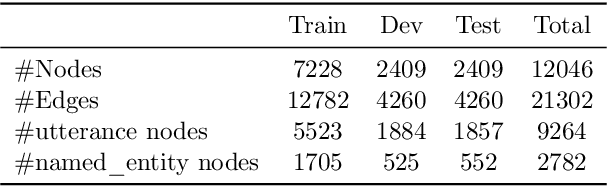
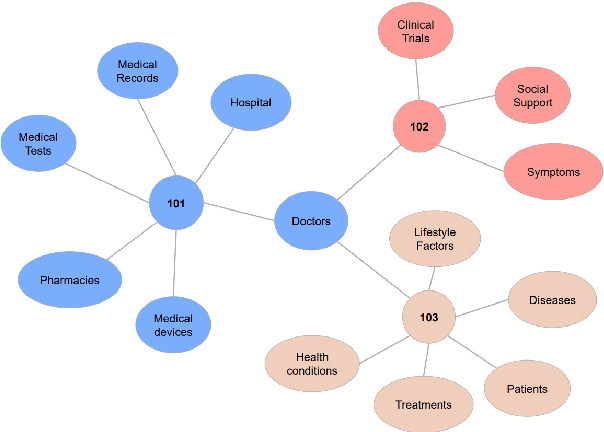
Knowledge graphs (KGs) enhance the performance of large language models (LLMs) and search engines by providing structured, interconnected data that improves reasoning and context-awareness. However, KGs only focus on text data, thereby neglecting other modalities such as speech. In this work, we introduce wav2graph, the first framework for supervised learning knowledge graph from speech data. Our pipeline are straightforward: (1) constructing a KG based on transcribed spoken utterances and a named entity database, (2) converting KG into embedding vectors, and (3) training graph neural networks (GNNs) for node classification and link prediction tasks. Through extensive experiments conducted in inductive and transductive learning contexts using state-of-the-art GNN models, we provide baseline results and error analysis for node classification and link prediction tasks on human transcripts and automatic speech recognition (ASR) transcripts, including evaluations using both encoder-based and decoder-based node embeddings, as well as monolingual and multilingual acoustic pre-trained models. All related code, data, and models are published online.
Sentiment Reasoning for Healthcare
Jul 24, 2024


Transparency in AI decision-making is crucial in healthcare due to the severe consequences of errors, and this is important for building trust among AI and users in sentiment analysis task. Incorporating reasoning capabilities helps Large Language Models (LLMs) understand human emotions within broader contexts, handle nuanced and ambiguous language, and infer underlying sentiments that may not be explicitly stated. In this work, we introduce a new task - Sentiment Reasoning - for both speech and text modalities, along with our proposed multimodal multitask framework and dataset. Our study showed that rationale-augmented training enhances model performance in sentiment classification across both human transcript and ASR settings. Also, we found that the generated rationales typically exhibit different vocabularies compared to human-generated rationales, but maintain similar semantics. All code, data (English-translated and Vietnamese) and models are published online: https://github.com/leduckhai/MultiMed
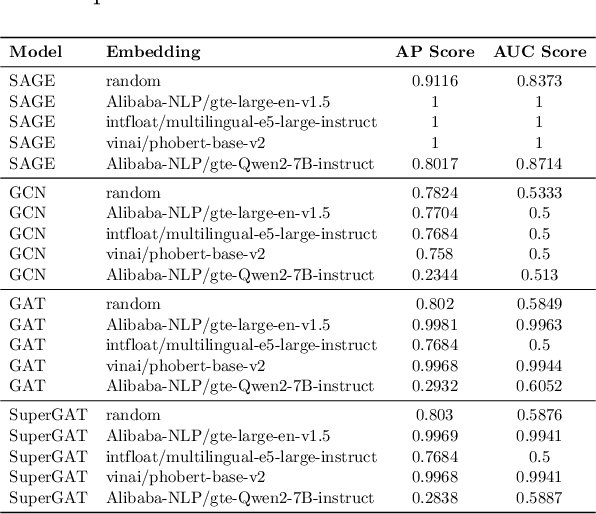
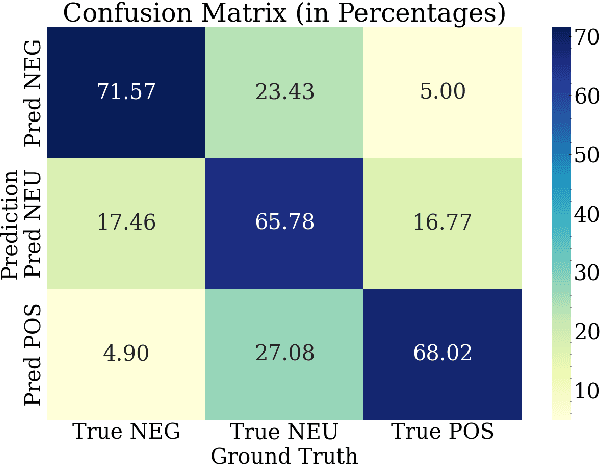
LiteGPT: Large Vision-Language Model for Joint Chest X-ray Localization and Classification Task
Jul 16, 2024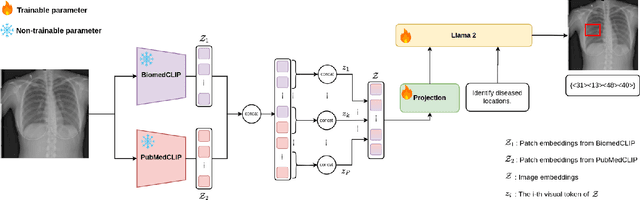

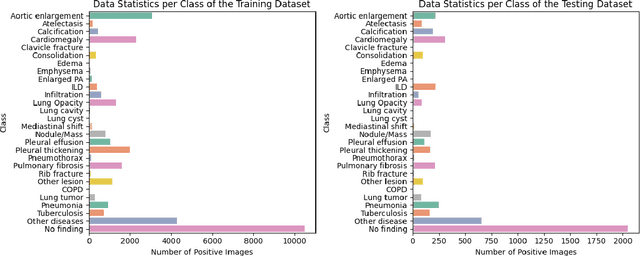

Vision-language models have been extensively explored across a wide range of tasks, achieving satisfactory performance; however, their application in medical imaging remains underexplored. In this work, we propose a unified framework - LiteGPT - for the medical imaging. We leverage multiple pre-trained visual encoders to enrich information and enhance the performance of vision-language models. To the best of our knowledge, this is the first study to utilize vision-language models for the novel task of joint localization and classification in medical images. Besides, we are pioneers in providing baselines for disease localization in chest X-rays. Finally, we set new state-of-the-art performance in the image classification task on the well-benchmarked VinDr-CXR dataset. All code and models are publicly available online: https://github.com/leduckhai/LiteGPT
Real-time Speech Summarization for Medical Conversations
Jun 22, 2024In doctor-patient conversations, identifying medically relevant information is crucial, posing the need for conversation summarization. In this work, we propose the first deployable real-time speech summarization system for real-world applications in industry, which generates a local summary after every N speech utterances within a conversation and a global summary after the end of a conversation. Our system could enhance user experience from a business standpoint, while also reducing computational costs from a technical perspective. Secondly, we present VietMed-Sum which, to our knowledge, is the first speech summarization dataset for medical conversations. Thirdly, we are the first to utilize LLM and human annotators collaboratively to create gold standard and synthetic summaries for medical conversation summarization. Finally, we present baseline results of state-of-the-art models on VietMed-Sum. All code, data (English-translated and Vietnamese) and models are available online: https://github.com/leduckhai/MultiMed
Medical Spoken Named Entity Recognition
Jun 19, 2024Spoken Named Entity Recognition (NER) aims to extracting named entities from speech and categorizing them into types like person, location, organization, etc. In this work, we present VietMed-NER - the first spoken NER dataset in the medical domain. To our best knowledge, our real-world dataset is the largest spoken NER dataset in the world in terms of the number of entity types, featuring 18 distinct types. Secondly, we present baseline results using various state-of-the-art pre-trained models: encoder-only and sequence-to-sequence. We found that pre-trained multilingual models XLM-R outperformed all monolingual models on both reference text and ASR output. Also in general, encoders perform better than sequence-to-sequence models for the NER task. By simply translating, the transcript is applicable not just to Vietnamese but to other languages as well. All code, data and models are made publicly available here: https://github.com/leduckhai/MultiMed
VietMed: A Dataset and Benchmark for Automatic Speech Recognition of Vietnamese in the Medical Domain
Apr 08, 2024


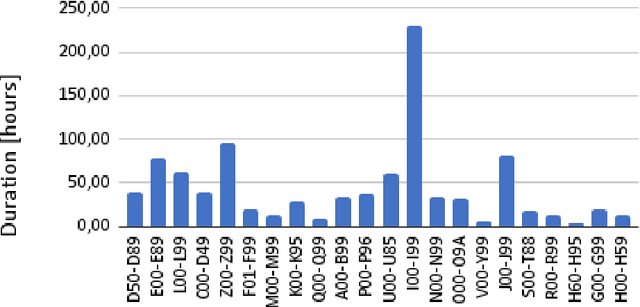
Due to privacy restrictions, there's a shortage of publicly available speech recognition datasets in the medical domain. In this work, we present VietMed - a Vietnamese speech recognition dataset in the medical domain comprising 16h of labeled medical speech, 1000h of unlabeled medical speech and 1200h of unlabeled general-domain speech. To our best knowledge, VietMed is by far the world's largest public medical speech recognition dataset in 7 aspects: total duration, number of speakers, diseases, recording conditions, speaker roles, unique medical terms and accents. VietMed is also by far the largest public Vietnamese speech dataset in terms of total duration. Additionally, we are the first to present a medical ASR dataset covering all ICD-10 disease groups and all accents within a country. Moreover, we release the first public large-scale pre-trained models for Vietnamese ASR, w2v2-Viet and XLSR-53-Viet, along with the first public large-scale fine-tuned models for medical ASR. Even without any medical data in unsupervised pre-training, our best pre-trained model XLSR-53-Viet generalizes very well to the medical domain by outperforming state-of-the-art XLSR-53, from 51.8% to 29.6% WER on test set (a relative reduction of more than 40%). All code, data and models are made publicly available here: https://github.com/leduckhai/MultiMed.