 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMergeSlide: Continual Model Merging and Task-to-Class Prompt-Aligned Inference for Lifelong Learning on Whole Slide Images
Nov 17, 2025Lifelong learning on Whole Slide Images (WSIs) aims to train or fine-tune a unified model sequentially on cancer-related tasks, reducing the resources and effort required for data transfer and processing, especially given the gigabyte-scale size of WSIs. In this paper, we introduce MergeSlide, a simple yet effective framework that treats lifelong learning as a model merging problem by leveraging a vision-language pathology foundation model. When a new task arrives, it is: 1) defined with class-aware prompts, 2) fine-tuned for a few epochs using an MLP-free backbone, and 3) merged into a unified model using an orthogonal continual merging strategy that preserves performance and mitigates catastrophic forgetting. For inference under the class-incremental learning (CLASS-IL) setting, where task identity is unknown, we introduce Task-to-Class Prompt-aligned (TCP) inference. Specifically, TCP first identifies the most relevant task using task-level prompts and then applies the corresponding class-aware prompts to generate predictions. To evaluate MergeSlide, we conduct experiments on a stream of six TCGA datasets. The results show that MergeSlide outperforms both rehearsal-based continual learning and vision-language zero-shot baselines. Code and data are available at https://github.com/caodoanh2001/MergeSlide.
HiGDA: Hierarchical Graph of Nodes to Learn Local-to-Global Topology for Semi-Supervised Domain Adaptation
Dec 16, 2024The enhanced representational power and broad applicability of deep learning models have attracted significant interest from the research community in recent years. However, these models often struggle to perform effectively under domain shift conditions, where the training data (the source domain) is related to but exhibits different distributions from the testing data (the target domain). To address this challenge, previous studies have attempted to reduce the domain gap between source and target data by incorporating a few labeled target samples during training - a technique known as semi-supervised domain adaptation (SSDA). While this strategy has demonstrated notable improvements in classification performance, the network architectures used in these approaches primarily focus on exploiting the features of individual images, leaving room for improvement in capturing rich representations. In this study, we introduce a Hierarchical Graph of Nodes designed to simultaneously present representations at both feature and category levels. At the feature level, we introduce a local graph to identify the most relevant patches within an image, facilitating adaptability to defined main object representations. At the category level, we employ a global graph to aggregate the features from samples within the same category, thereby enriching overall representations. Extensive experiments on widely used SSDA benchmark datasets, including Office-Home, DomainNet, and VisDA2017, demonstrate that both quantitative and qualitative results substantiate the effectiveness of HiGDA, establishing it as a new state-of-the-art method.
LiteGPT: Large Vision-Language Model for Joint Chest X-ray Localization and Classification Task
Jul 16, 2024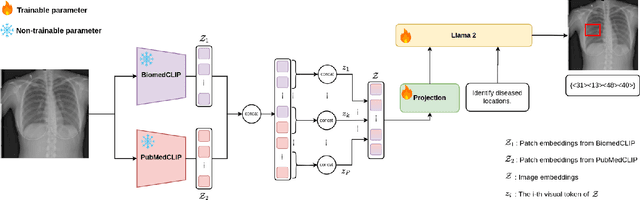

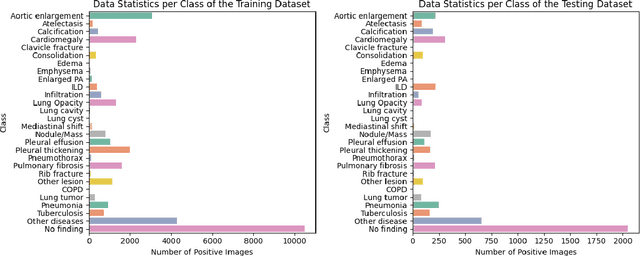

Vision-language models have been extensively explored across a wide range of tasks, achieving satisfactory performance; however, their application in medical imaging remains underexplored. In this work, we propose a unified framework - LiteGPT - for the medical imaging. We leverage multiple pre-trained visual encoders to enrich information and enhance the performance of vision-language models. To the best of our knowledge, this is the first study to utilize vision-language models for the novel task of joint localization and classification in medical images. Besides, we are pioneers in providing baselines for disease localization in chest X-rays. Finally, we set new state-of-the-art performance in the image classification task on the well-benchmarked VinDr-CXR dataset. All code and models are publicly available online: https://github.com/leduckhai/LiteGPT
Learning CNN on ViT: A Hybrid Model to Explicitly Class-specific Boundaries for Domain Adaptation
Apr 02, 2024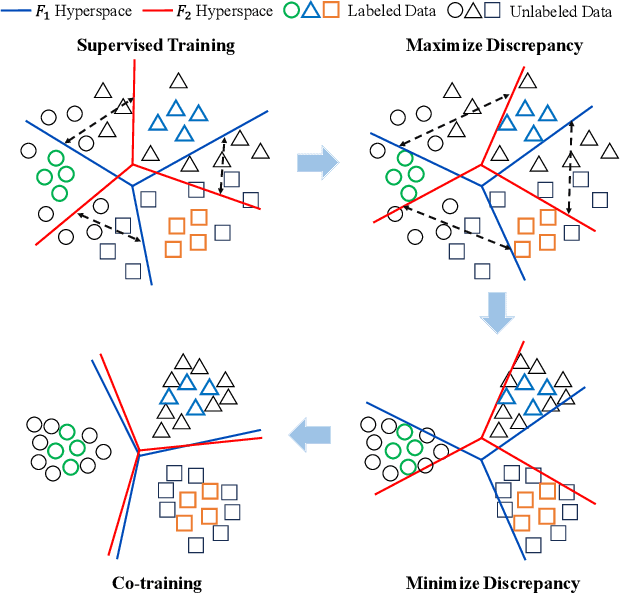
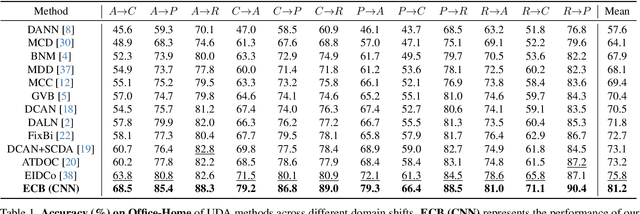
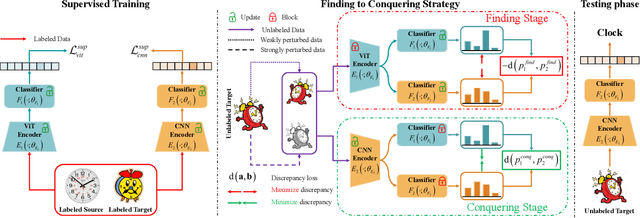
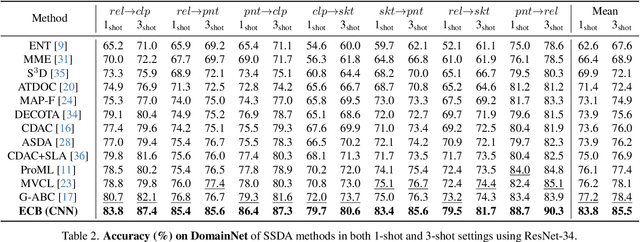
Most domain adaptation (DA) methods are based on either a convolutional neural networks (CNNs) or a vision transformers (ViTs). They align the distribution differences between domains as encoders without considering their unique characteristics. For instance, ViT excels in accuracy due to its superior ability to capture global representations, while CNN has an advantage in capturing local representations. This fact has led us to design a hybrid method to fully take advantage of both ViT and CNN, called Explicitly Class-specific Boundaries (ECB). ECB learns CNN on ViT to combine their distinct strengths. In particular, we leverage ViT's properties to explicitly find class-specific decision boundaries by maximizing the discrepancy between the outputs of the two classifiers to detect target samples far from the source support. In contrast, the CNN encoder clusters target features based on the previously defined class-specific boundaries by minimizing the discrepancy between the probabilities of the two classifiers. Finally, ViT and CNN mutually exchange knowledge to improve the quality of pseudo labels and reduce the knowledge discrepancies of these models. Compared to conventional DA methods, our ECB achieves superior performance, which verifies its effectiveness in this hybrid model. The project website can be found https://dotrannhattuong.github.io/ECB/website/.
Towards Robust Natural-Looking Mammography Lesion Synthesis on Ipsilateral Dual-Views Breast Cancer Analysis
Sep 07, 2023In recent years, many mammographic image analysis methods have been introduced for improving cancer classification tasks. Two major issues of mammogram classification tasks are leveraging multi-view mammographic information and class-imbalance handling. In the first problem, many multi-view methods have been released for concatenating features of two or more views for the training and inference stage. Having said that, most multi-view existing methods are not explainable in the meaning of feature fusion, and treat many views equally for diagnosing. Our work aims to propose a simple but novel method for enhancing examined view (main view) by leveraging low-level feature information from the auxiliary view (ipsilateral view) before learning the high-level feature that contains the cancerous features. For the second issue, we also propose a simple but novel malignant mammogram synthesis framework for upsampling minor class samples. Our easy-to-implement and no-training framework has eliminated the current limitation of the CutMix algorithm which is unreliable synthesized images with random pasted patches, hard-contour problems, and domain shift problems. Our results on VinDr-Mammo and CMMD datasets show the effectiveness of our two new frameworks for both multi-view training and synthesizing mammographic images, outperforming the previous conventional methods in our experimental settings.