 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOZSpeech: One-step Zero-shot Speech Synthesis with Learned-Prior-Conditioned Flow Matching
May 19, 2025Text-to-speech (TTS) systems have seen significant advancements in recent years, driven by improvements in deep learning and neural network architectures. Viewing the output speech as a data distribution, previous approaches often employ traditional speech representations, such as waveforms or spectrograms, within the Flow Matching framework. However, these methods have limitations, including overlooking various speech attributes and incurring high computational costs due to additional constraints introduced during training. To address these challenges, we introduce OZSpeech, the first TTS method to explore optimal transport conditional flow matching with one-step sampling and a learned prior as the condition, effectively disregarding preceding states and reducing the number of sampling steps. Our approach operates on disentangled, factorized components of speech in token format, enabling accurate modeling of each speech attribute, which enhances the TTS system's ability to precisely clone the prompt speech. Experimental results show that our method achieves promising performance over existing methods in content accuracy, naturalness, prosody generation, and speaker style preservation. Audio samples are available at our demo page https://ozspeech.github.io/OZSpeech_Web/.
Advancing Vietnamese Visual Question Answering with Transformer and Convolutional Integration
Jul 30, 2024



Visual Question Answering (VQA) has recently emerged as a potential research domain, captivating the interest of many in the field of artificial intelligence and computer vision. Despite the prevalence of approaches in English, there is a notable lack of systems specifically developed for certain languages, particularly Vietnamese. This study aims to bridge this gap by conducting comprehensive experiments on the Vietnamese Visual Question Answering (ViVQA) dataset, demonstrating the effectiveness of our proposed model. In response to community interest, we have developed a model that enhances image representation capabilities, thereby improving overall performance in the ViVQA system. Specifically, our model integrates the Bootstrapping Language-Image Pre-training with frozen unimodal models (BLIP-2) and the convolutional neural network EfficientNet to extract and process both local and global features from images. This integration leverages the strengths of transformer-based architectures for capturing comprehensive contextual information and convolutional networks for detailed local features. By freezing the parameters of these pre-trained models, we significantly reduce the computational cost and training time, while maintaining high performance. This approach significantly improves image representation and enhances the performance of existing VQA systems. We then leverage a multi-modal fusion module based on a general-purpose multi-modal foundation model (BEiT-3) to fuse the information between visual and textual features. Our experimental findings demonstrate that our model surpasses competing baselines, achieving promising performance. This is particularly evident in its accuracy of $71.04\%$ on the test set of the ViVQA dataset, marking a significant advancement in our research area. The code is available at https://github.com/nngocson2002/ViVQA.
* Accepted at the journal of Computers & Electrical Engineering (Received 8 March 2024, Revised 8 June 2024, Accepted 10 July 2024)
LiteGPT: Large Vision-Language Model for Joint Chest X-ray Localization and Classification Task
Jul 16, 2024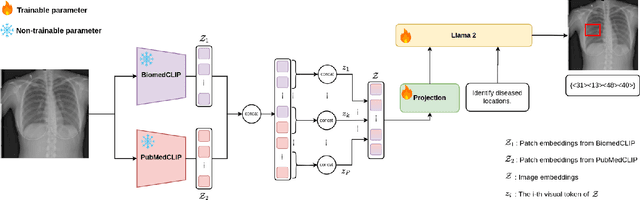

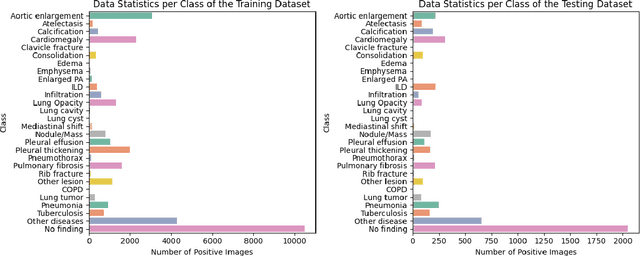

Vision-language models have been extensively explored across a wide range of tasks, achieving satisfactory performance; however, their application in medical imaging remains underexplored. In this work, we propose a unified framework - LiteGPT - for the medical imaging. We leverage multiple pre-trained visual encoders to enrich information and enhance the performance of vision-language models. To the best of our knowledge, this is the first study to utilize vision-language models for the novel task of joint localization and classification in medical images. Besides, we are pioneers in providing baselines for disease localization in chest X-rays. Finally, we set new state-of-the-art performance in the image classification task on the well-benchmarked VinDr-CXR dataset. All code and models are publicly available online: https://github.com/leduckhai/LiteGPT