 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Chain of Continuous Thought for Latent-Space Reasoning in Vision-Language Models
Aug 18, 2025Many reasoning techniques for large multimodal models adapt language model approaches, such as Chain-of-Thought (CoT) prompting, which express reasoning as word sequences. While effective for text, these methods are suboptimal for multimodal contexts, struggling to align audio, visual, and textual information dynamically. To explore an alternative paradigm, we propose the Multimodal Chain of Continuous Thought (MCOUT), which enables reasoning directly in a joint latent space rather than in natural language. In MCOUT, the reasoning state is represented as a continuous hidden vector, iteratively refined and aligned with visual and textual embeddings, inspired by human reflective cognition. We develop two variants: MCOUT-Base, which reuses the language model`s last hidden state as the continuous thought for iterative reasoning, and MCOUT-Multi, which integrates multimodal latent attention to strengthen cross-modal alignment between visual and textual features. Experiments on benchmarks including MMMU, ScienceQA, and MMStar show that MCOUT consistently improves multimodal reasoning, yielding up to 8.23% accuracy gains over strong baselines and improving BLEU scores up to 8.27% across multiple-choice and open-ended tasks. These findings highlight latent continuous reasoning as a promising direction for advancing LMMs beyond language-bound CoT, offering a scalable framework for human-like reflective multimodal inference. Code is available at https://github.com/Hanhpt23/OmniMod.
RARL: Improving Medical VLM Reasoning and Generalization with Reinforcement Learning and LoRA under Data and Hardware Constraints
Jun 07, 2025



The growing integration of vision-language models (VLMs) in medical applications offers promising support for diagnostic reasoning. However, current medical VLMs often face limitations in generalization, transparency, and computational efficiency-barriers that hinder deployment in real-world, resource-constrained settings. To address these challenges, we propose a Reasoning-Aware Reinforcement Learning framework, \textbf{RARL}, that enhances the reasoning capabilities of medical VLMs while remaining efficient and adaptable to low-resource environments. Our approach fine-tunes a lightweight base model, Qwen2-VL-2B-Instruct, using Low-Rank Adaptation and custom reward functions that jointly consider diagnostic accuracy and reasoning quality. Training is performed on a single NVIDIA A100-PCIE-40GB GPU, demonstrating the feasibility of deploying such models in constrained environments. We evaluate the model using an LLM-as-judge framework that scores both correctness and explanation quality. Experimental results show that RARL significantly improves VLM performance in medical image analysis and clinical reasoning, outperforming supervised fine-tuning on reasoning-focused tasks by approximately 7.78%, while requiring fewer computational resources. Additionally, we demonstrate the generalization capabilities of our approach on unseen datasets, achieving around 27% improved performance compared to supervised fine-tuning and about 4% over traditional RL fine-tuning. Our experiments also illustrate that diversity prompting during training and reasoning prompting during inference are crucial for enhancing VLM performance. Our findings highlight the potential of reasoning-guided learning and reasoning prompting to steer medical VLMs toward more transparent, accurate, and resource-efficient clinical decision-making. Code and data are publicly available.
IQBench: How "Smart'' Are Vision-Language Models? A Study with Human IQ Tests
May 17, 2025Although large Vision-Language Models (VLMs) have demonstrated remarkable performance in a wide range of multimodal tasks, their true reasoning capabilities on human IQ tests remain underexplored. To advance research on the fluid intelligence of VLMs, we introduce **IQBench**, a new benchmark designed to evaluate VLMs on standardized visual IQ tests. We focus on evaluating the reasoning capabilities of VLMs, which we argue are more important than the accuracy of the final prediction. **Our benchmark is visually centric, minimizing the dependence on unnecessary textual content**, thus encouraging models to derive answers primarily from image-based information rather than learned textual knowledge. To this end, we manually collected and annotated 500 visual IQ questions to **prevent unintentional data leakage during training**. Unlike prior work that focuses primarily on the accuracy of the final answer, we evaluate the reasoning ability of the models by assessing their explanations and the patterns used to solve each problem, along with the accuracy of the final prediction and human evaluation. Our experiments show that there are substantial performance disparities between tasks, with models such as `o4-mini`, `gemini-2.5-flash`, and `claude-3.7-sonnet` achieving the highest average accuracies of 0.615, 0.578, and 0.548, respectively. However, all models struggle with 3D spatial and anagram reasoning tasks, highlighting significant limitations in current VLMs' general reasoning abilities. In terms of reasoning scores, `o4-mini`, `gemini-2.5-flash`, and `claude-3.7-sonnet` achieved top averages of 0.696, 0.586, and 0.516, respectively. These results highlight inconsistencies between the reasoning processes of the models and their final answers, emphasizing the importance of evaluating the accuracy of the reasoning in addition to the final predictions.
Missing Data Estimation for MR Spectroscopic Imaging via Mask-Free Deep Learning Methods
May 11, 2025Magnetic Resonance Spectroscopic Imaging (MRSI) is a powerful tool for non-invasive mapping of brain metabolites, providing critical insights into neurological conditions. However, its utility is often limited by missing or corrupted data due to motion artifacts, magnetic field inhomogeneities, or failed spectral fitting-especially in high resolution 3D acquisitions. To address this, we propose the first deep learning-based, mask-free framework for estimating missing data in MRSI metabolic maps. Unlike conventional restoration methods that rely on explicit masks to identify missing regions, our approach implicitly detects and estimates these areas using contextual spatial features through 2D and 3D U-Net architectures. We also introduce a progressive training strategy to enhance robustness under varying levels of data degradation. Our method is evaluated on both simulated and real patient datasets and consistently outperforms traditional interpolation techniques such as cubic and linear interpolation. The 2D model achieves an MSE of 0.002 and an SSIM of 0.97 with 20% missing voxels, while the 3D model reaches an MSE of 0.001 and an SSIM of 0.98 with 15% missing voxels. Qualitative results show improved fidelity in estimating missing data, particularly in metabolically heterogeneous regions and ventricular regions. Importantly, our model generalizes well to real-world datasets without requiring retraining or mask input. These findings demonstrate the effectiveness and broad applicability of mask-free deep learning for MRSI restoration, with strong potential for clinical and research integration.
SilVar-Med: A Speech-Driven Visual Language Model for Explainable Abnormality Detection in Medical Imaging
Apr 14, 2025Medical Visual Language Models have shown great potential in various healthcare applications, including medical image captioning and diagnostic assistance. However, most existing models rely on text-based instructions, limiting their usability in real-world clinical environments especially in scenarios such as surgery, text-based interaction is often impractical for physicians. In addition, current medical image analysis models typically lack comprehensive reasoning behind their predictions, which reduces their reliability for clinical decision-making. Given that medical diagnosis errors can have life-changing consequences, there is a critical need for interpretable and rational medical assistance. To address these challenges, we introduce an end-to-end speech-driven medical VLM, SilVar-Med, a multimodal medical image assistant that integrates speech interaction with VLMs, pioneering the task of voice-based communication for medical image analysis. In addition, we focus on the interpretation of the reasoning behind each prediction of medical abnormalities with a proposed reasoning dataset. Through extensive experiments, we demonstrate a proof-of-concept study for reasoning-driven medical image interpretation with end-to-end speech interaction. We believe this work will advance the field of medical AI by fostering more transparent, interactive, and clinically viable diagnostic support systems. Our code and dataset are publicly available at SiVar-Med.
Predicting Space Tourism Demand Using Explainable AI
Mar 05, 2025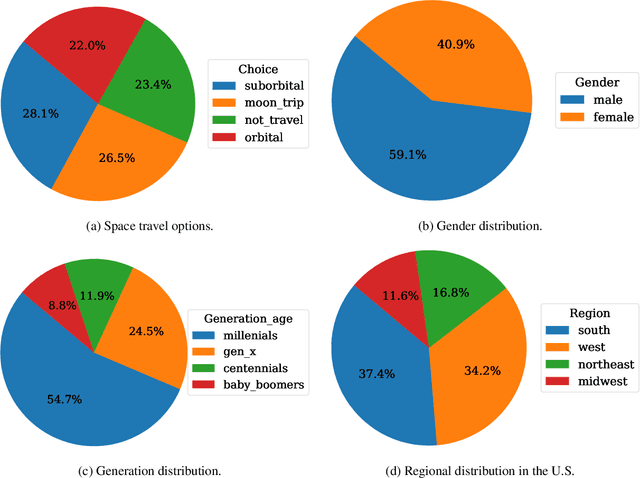
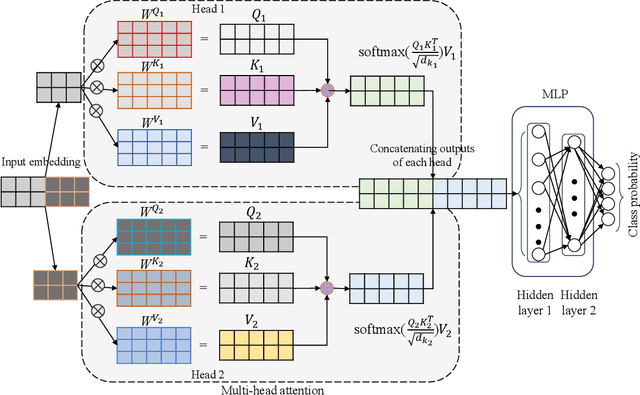
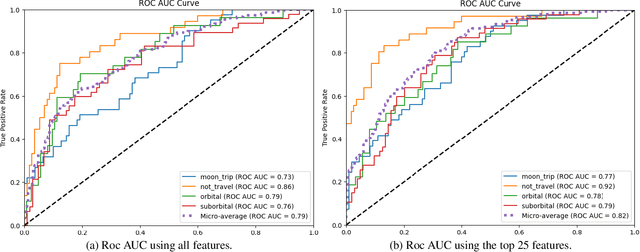
Comprehensive forecasts of space tourism demand are crucial for businesses to optimize strategies and customer experiences in this burgeoning industry. Traditional methods struggle to capture the complex factors influencing an individual's decision to travel to space. In this paper, we propose an explainable and trustworthy artificial intelligence framework to address the challenge of predicting space tourism demand by following the National Institute of Standards and Technology guidelines. We develop a novel machine learning network, called SpaceNet, capable of learning wide-range dependencies in data and allowing us to analyze the relationships between various factors such as age, income, and risk tolerance. We investigate space travel demand in the US, categorizing it into four types: no travel, moon travel, suborbital, and orbital travel. To this end, we collected 1860 data points in many states and cities with different ages and then conducted our experiment with the data. From our experiments, the SpaceNet achieves an average ROC-AUC of 0.82 $\pm$ 0.088, indicating strong classification performance. Our investigation demonstrated that travel price, age, annual income, gender, and fatality probability are important features in deciding whether a person wants to travel or not. Beyond demand forecasting, we use explainable AI to provide interpretation for the travel-type decisions of an individual, offering insights into the factors driving interest in space travel, which is not possible with traditional classification methods. This knowledge enables businesses to tailor marketing strategies and optimize service offerings in this rapidly evolving market. To the best of our knowledge, this is the first work to implement an explainable and interpretable AI framework for investigating the factors influencing space tourism.
A Wearable Device Dataset for Mental Health Assessment Using Laser Doppler Flowmetry and Fluorescence Spectroscopy Sensors
Feb 03, 2025



In this study, we introduce a novel method to predict mental health by building machine learning models for a non-invasive wearable device equipped with Laser Doppler Flowmetry (LDF) and Fluorescence Spectroscopy (FS) sensors. Besides, we present the corresponding dataset to predict mental health, e.g. depression, anxiety, and stress levels via the DAS-21 questionnaire. To our best knowledge, this is the world's largest and the most generalized dataset ever collected for both LDF and FS studies. The device captures cutaneous blood microcirculation parameters, and wavelet analysis of the LDF signal extracts key rhythmic oscillations. The dataset, collected from 132 volunteers aged 18-94 from 19 countries, explores relationships between physiological features, demographics, lifestyle habits, and health conditions. We employed a variety of machine learning methods to classify stress detection, in which LightGBM is identified as the most effective model for stress detection, achieving a ROC AUC of 0.7168 and a PR AUC of 0.8852. In addition, we also incorporated Explainable Artificial Intelligence (XAI) techniques into our analysis to investigate deeper insights into the model's predictions. Our results suggest that females, younger individuals and those with a higher Body Mass Index (BMI) or heart rate have a greater likelihood of experiencing mental health conditions like stress and anxiety. All related code and data are published online: https://github.com/leduckhai/Wearable_LDF-FS.
SilVar: Speech Driven Multimodal Model for Reasoning Visual Question Answering and Object Localization
Dec 21, 2024Visual Language Models have demonstrated remarkable capabilities across tasks, including visual question answering and image captioning. However, most models rely on text-based instructions, limiting their effectiveness in human-machine interactions. Moreover, the quality of language models depends on reasoning and prompting techniques, such as COT, which remain underexplored when using speech instructions. To address these challenges, we propose SilVar, a novel end-to-end multimodal model that uses speech instructions for reasoning in visual question answering. In addition, we investigate reasoning techniques with levels including conversational, simple, and complex speech instruction. SilVar is built upon CLIP, Whisper, and LLaMA 3.1-8B, enabling intuitive interactions by allowing users to provide verbal or text instructions. To this end, we introduce a dataset designed to challenge models with speech-based reasoning tasks for object localization. This dataset enhances the model ability to process and explain visual scenes from spoken input, moving beyond object recognition to reasoning-based interactions. The experiments show that SilVar achieves SOTA performance on the MMMU and ScienceQA benchmarks despite the challenge of speech-based instructions. We believe SilVar will inspire next-generation multimodal reasoning models, toward expert artificial general intelligence. Our code and dataset are available here.
Adaptive Compensation for Robotic Joint Failures Using Partially Observable Reinforcement Learning
Sep 22, 2024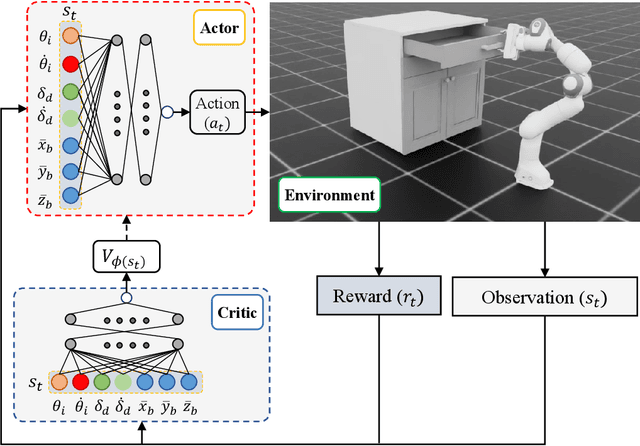
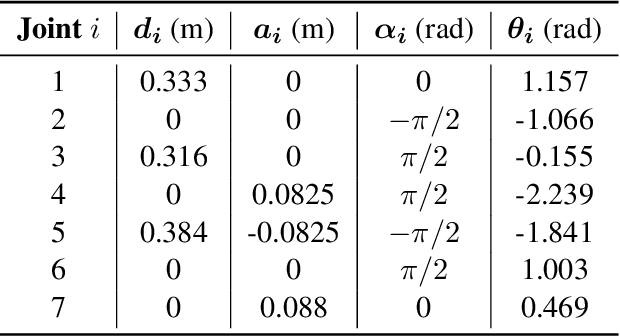
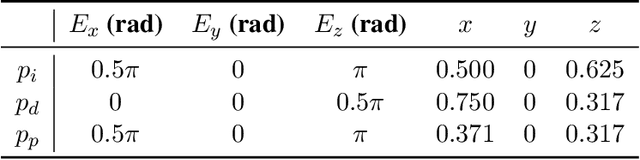
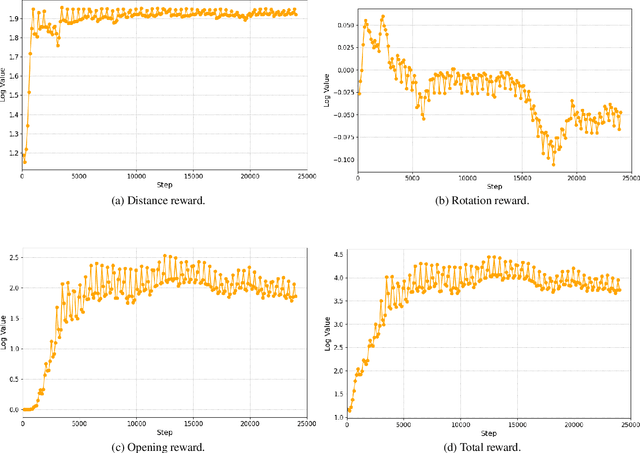
Robotic manipulators are widely used in various industries for complex and repetitive tasks. However, they remain vulnerable to unexpected hardware failures. In this study, we address the challenge of enabling a robotic manipulator to complete tasks despite joint malfunctions. Specifically, we develop a reinforcement learning (RL) framework to adaptively compensate for a non-functional joint during task execution. Our experimental platform is the Franka robot with 7 degrees of freedom (DOFs). We formulate the problem as a partially observable Markov decision process (POMDP), where the robot is trained under various joint failure conditions and tested in both seen and unseen scenarios. We consider scenarios where a joint is permanently broken and where it functions intermittently. Additionally, we demonstrate the effectiveness of our approach by comparing it with traditional inverse kinematics-based control methods. The results show that the RL algorithm enables the robot to successfully complete tasks even with joint failures, achieving a high success rate with an average rate of 93.6%. This showcases its robustness and adaptability. Our findings highlight the potential of RL to enhance the resilience and reliability of robotic systems, making them better suited for unpredictable environments. All related codes and models are published online.
MultiMed: Multilingual Medical Speech Recognition via Attention Encoder Decoder
Sep 21, 2024
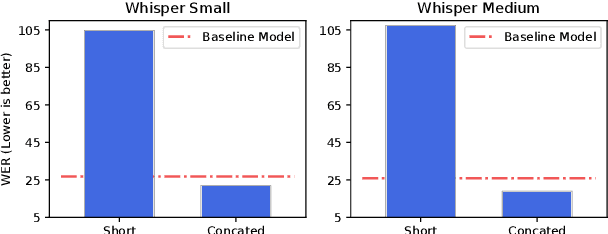


Multilingual automatic speech recognition (ASR) in the medical domain serves as a foundational task for various downstream applications such as speech translation, spoken language understanding, and voice-activated assistants. This technology enhances patient care by enabling efficient communication across language barriers, alleviating specialized workforce shortages, and facilitating improved diagnosis and treatment, particularly during pandemics. In this work, we introduce MultiMed, a collection of small-to-large end-to-end ASR models for the medical domain, spanning five languages: Vietnamese, English, German, French, and Mandarin Chinese, together with the corresponding real-world ASR dataset. To our best knowledge, MultiMed stands as the largest and the first multilingual medical ASR dataset, in terms of total duration, number of speakers, diversity of diseases, recording conditions, speaker roles, unique medical terms, accents, and ICD-10 codes. Secondly, we establish the empirical baselines, present the first reproducible study of multilinguality in medical ASR, conduct a layer-wise ablation study for end-to-end ASR training, and provide the first linguistic analysis for multilingual medical ASR. All code, data, and models are available online https://github.com/leduckhai/MultiMed/tree/master/MultiMed