 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-Chain: Structured Visual Chain-of-Thought For Medicine
Oct 26, 2025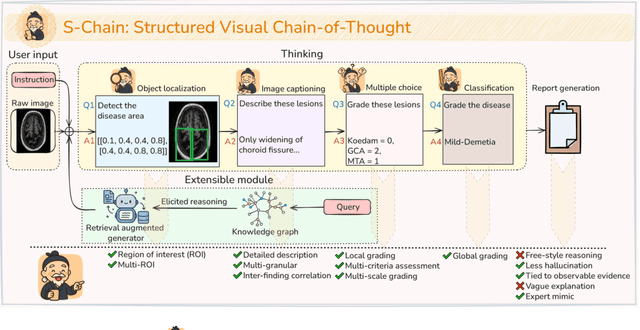
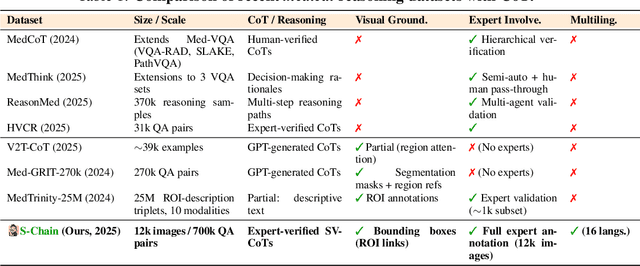
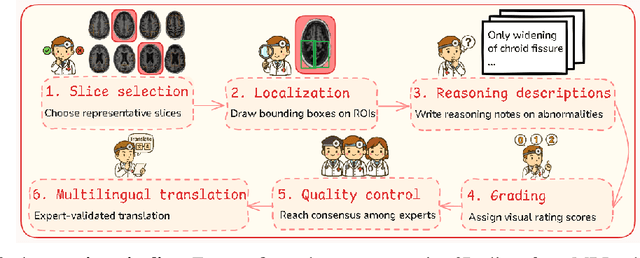
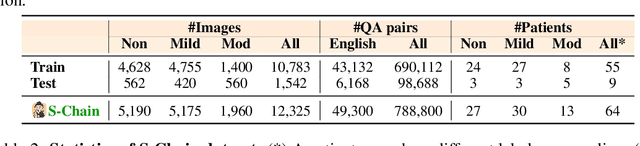
Faithful reasoning in medical vision-language models (VLMs) requires not only accurate predictions but also transparent alignment between textual rationales and visual evidence. While Chain-of-Thought (CoT) prompting has shown promise in medical visual question answering (VQA), no large-scale expert-level dataset has captured stepwise reasoning with precise visual grounding. We introduce S-Chain, the first large-scale dataset of 12,000 expert-annotated medical images with bounding boxes and structured visual CoT (SV-CoT), explicitly linking visual regions to reasoning steps. The dataset further supports 16 languages, totaling over 700k VQA pairs for broad multilingual applicability. Using S-Chain, we benchmark state-of-the-art medical VLMs (ExGra-Med, LLaVA-Med) and general-purpose VLMs (Qwen2.5-VL, InternVL2.5), showing that SV-CoT supervision significantly improves interpretability, grounding fidelity, and robustness. Beyond benchmarking, we study its synergy with retrieval-augmented generation, revealing how domain knowledge and visual grounding interact during autoregressive reasoning. Finally, we propose a new mechanism that strengthens the alignment between visual evidence and reasoning, improving both reliability and efficiency. S-Chain establishes a new benchmark for grounded medical reasoning and paves the way toward more trustworthy and explainable medical VLMs.
A Survey on Long-Video Storytelling Generation: Architectures, Consistency, and Cinematic Quality
Jul 09, 2025

Despite the significant progress that has been made in video generative models, existing state-of-the-art methods can only produce videos lasting 5-16 seconds, often labeled "long-form videos". Furthermore, videos exceeding 16 seconds struggle to maintain consistent character appearances and scene layouts throughout the narrative. In particular, multi-subject long videos still fail to preserve character consistency and motion coherence. While some methods can generate videos up to 150 seconds long, they often suffer from frame redundancy and low temporal diversity. Recent work has attempted to produce long-form videos featuring multiple characters, narrative coherence, and high-fidelity detail. We comprehensively studied 32 papers on video generation to identify key architectural components and training strategies that consistently yield these qualities. We also construct a comprehensive novel taxonomy of existing methods and present comparative tables that categorize papers by their architectural designs and performance characteristics.
Vision Language Models are Biased
May 29, 2025Large language models (LLMs) memorize a vast amount of prior knowledge from the Internet that help them on downstream tasks but also may notoriously sway their outputs towards wrong or biased answers. In this work, we test how the knowledge about popular subjects hurt the accuracy of vision language models (VLMs) on standard, objective visual tasks of counting and identification. We find that state-of-the-art VLMs are strongly biased (e.g, unable to recognize a fourth stripe has been added to a 3-stripe Adidas logo) scoring an average of 17.05% accuracy in counting (e.g., counting stripes in an Adidas-like logo) across 7 diverse domains from animals, logos, chess, board games, optical illusions, to patterned grids. Insert text (e.g., "Adidas") describing the subject name into the counterfactual image further decreases VLM accuracy. The biases in VLMs are so strong that instructing them to double-check their results or rely exclusively on image details to answer improves counting accuracy by only +2 points, on average. Our work presents an interesting failure mode in VLMs and an automated framework for testing VLM biases. Code and data are available at: vlmsarebiased.github.io.
B-score: Detecting biases in large language models using response history
May 24, 2025Large language models (LLMs) often exhibit strong biases, e.g, against women or in favor of the number 7. We investigate whether LLMs would be able to output less biased answers when allowed to observe their prior answers to the same question in a multi-turn conversation. To understand which types of questions invite more biased answers, we test LLMs on our proposed set of questions that span 9 topics and belong to three types: (1) Subjective; (2) Random; and (3) Objective. Interestingly, LLMs are able to "de-bias" themselves in a multi-turn conversation in response to questions that seek an Random, unbiased answer. Furthermore, we propose B-score, a novel metric that is effective in detecting biases to Subjective, Random, Easy, and Hard questions. On MMLU, HLE, and CSQA, leveraging B-score substantially improves the verification accuracy of LLM answers (i.e, accepting LLM correct answers and rejecting incorrect ones) compared to using verbalized confidence scores or the frequency of single-turn answers alone. Code and data are available at: https://b-score.github.io.
Understanding Generative AI Capabilities in Everyday Image Editing Tasks
May 22, 2025



Generative AI (GenAI) holds significant promise for automating everyday image editing tasks, especially following the recent release of GPT-4o on March 25, 2025. However, what subjects do people most often want edited? What kinds of editing actions do they want to perform (e.g., removing or stylizing the subject)? Do people prefer precise edits with predictable outcomes or highly creative ones? By understanding the characteristics of real-world requests and the corresponding edits made by freelance photo-editing wizards, can we draw lessons for improving AI-based editors and determine which types of requests can currently be handled successfully by AI editors? In this paper, we present a unique study addressing these questions by analyzing 83k requests from the past 12 years (2013-2025) on the Reddit community, which collected 305k PSR-wizard edits. According to human ratings, approximately only 33% of requests can be fulfilled by the best AI editors (including GPT-4o, Gemini-2.0-Flash, SeedEdit). Interestingly, AI editors perform worse on low-creativity requests that require precise editing than on more open-ended tasks. They often struggle to preserve the identity of people and animals, and frequently make non-requested touch-ups. On the other side of the table, VLM judges (e.g., o1) perform differently from human judges and may prefer AI edits more than human edits. Code and qualitative examples are available at: https://psrdataset.github.io
HoT: Highlighted Chain of Thought for Referencing Supporting Facts from Inputs
Mar 05, 2025An Achilles heel of Large Language Models (LLMs) is their tendency to hallucinate non-factual statements. A response mixed of factual and non-factual statements poses a challenge for humans to verify and accurately base their decisions on. To combat this problem, we propose Highlighted Chain-of-Thought Prompting (HoT), a technique for prompting LLMs to generate responses with XML tags that ground facts to those provided in the query. That is, given an input question, LLMs would first re-format the question to add XML tags highlighting key facts, and then, generate a response with highlights over the facts referenced from the input. Interestingly, in few-shot settings, HoT outperforms vanilla chain of thought prompting (CoT) on a wide range of 17 tasks from arithmetic, reading comprehension to logical reasoning. When asking humans to verify LLM responses, highlights help time-limited participants to more accurately and efficiently recognize when LLMs are correct. Yet, surprisingly, when LLMs are wrong, HoTs tend to make users believe that an answer is correct.
Improving Zero-Shot Object-Level Change Detection by Incorporating Visual Correspondence
Jan 09, 2025
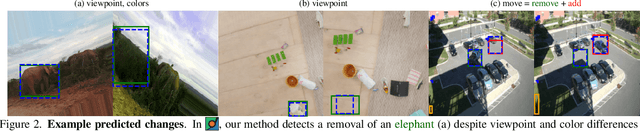

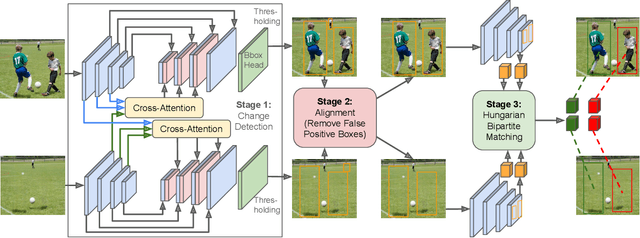
Detecting object-level changes between two images across possibly different views is a core task in many applications that involve visual inspection or camera surveillance. Existing change-detection approaches suffer from three major limitations: (1) lack of evaluation on image pairs that contain no changes, leading to unreported false positive rates; (2) lack of correspondences (\ie, localizing the regions before and after a change); and (3) poor zero-shot generalization across different domains. To address these issues, we introduce a novel method that leverages change correspondences (a) during training to improve change detection accuracy, and (b) at test time, to minimize false positives. That is, we harness the supervision labels of where an object is added or removed to supervise change detectors, improving their accuracy over previous work by a large margin. Our work is also the first to predict correspondences between pairs of detected changes using estimated homography and the Hungarian algorithm. Our model demonstrates superior performance over existing methods, achieving state-of-the-art results in change detection and change correspondence accuracy across both in-distribution and zero-shot benchmarks.
TAB: Transformer Attention Bottlenecks enable User Intervention and Debugging in Vision-Language Models
Dec 24, 2024Multi-head self-attention (MHSA) is a key component of Transformers, a widely popular architecture in both language and vision. Multiple heads intuitively enable different parallel processes over the same input. Yet, they also obscure the attribution of each input patch to the output of a model. We propose a novel 1-head Transformer Attention Bottleneck (TAB) layer, inserted after the traditional MHSA architecture, to serve as an attention bottleneck for interpretability and intervention. Unlike standard self-attention, TAB constrains the total attention over all patches to $\in [0, 1]$. That is, when the total attention is 0, no visual information is propagated further into the network and the vision-language model (VLM) would default to a generic, image-independent response. To demonstrate the advantages of TAB, we train VLMs with TAB to perform image difference captioning. Over three datasets, our models perform similarly to baseline VLMs in captioning but the bottleneck is superior in localizing changes and in identifying when no changes occur. TAB is the first architecture to enable users to intervene by editing attention, which often produces expected outputs by VLMs.
Interpretable LLM-based Table Question Answering
Dec 16, 2024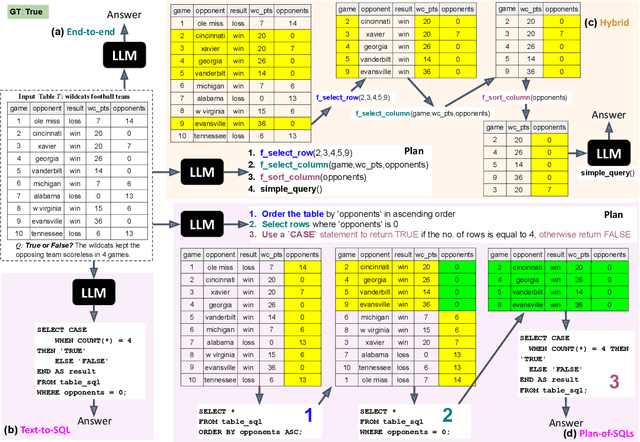

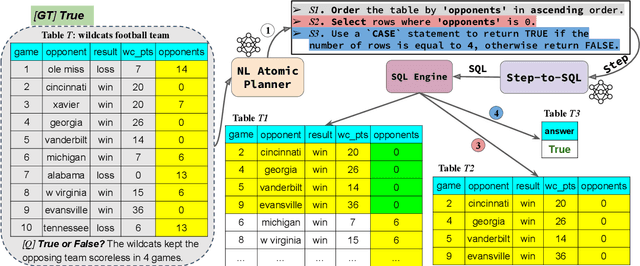
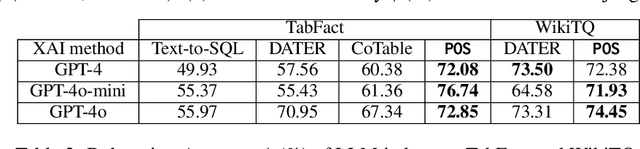
Interpretability for Table Question Answering (Table QA) is critical, particularly in high-stakes industries like finance or healthcare. Although recent approaches using Large Language Models (LLMs) have significantly improved Table QA performance, their explanations for how the answers are generated are ambiguous. To fill this gap, we introduce Plan-of-SQLs ( or POS), an interpretable, effective, and efficient approach to Table QA that answers an input query solely with SQL executions. Through qualitative and quantitative evaluations with human and LLM judges, we show that POS is most preferred among explanation methods, helps human users understand model decision boundaries, and facilitates model success and error identification. Furthermore, when evaluated in standard benchmarks (TabFact, WikiTQ, and FetaQA), POS achieves competitive or superior accuracy compared to existing methods, while maintaining greater efficiency by requiring significantly fewer LLM calls and database queries.
Sentiment Reasoning for Healthcare
Jul 24, 2024
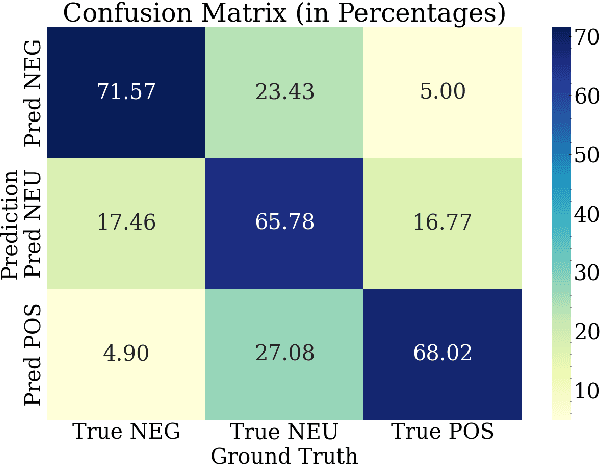


Transparency in AI decision-making is crucial in healthcare due to the severe consequences of errors, and this is important for building trust among AI and users in sentiment analysis task. Incorporating reasoning capabilities helps Large Language Models (LLMs) understand human emotions within broader contexts, handle nuanced and ambiguous language, and infer underlying sentiments that may not be explicitly stated. In this work, we introduce a new task - Sentiment Reasoning - for both speech and text modalities, along with our proposed multimodal multitask framework and dataset. Our study showed that rationale-augmented training enhances model performance in sentiment classification across both human transcript and ASR settings. Also, we found that the generated rationales typically exhibit different vocabularies compared to human-generated rationales, but maintain similar semantics. All code, data (English-translated and Vietnamese) and models are published online: https://github.com/leduckhai/MultiMed