 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Explaining Large Language Models in Software Engineering Tasks
Dec 23, 2025Recent progress in Large Language Models (LLMs) has substantially advanced the automation of software engineering (SE) tasks, enabling complex activities such as code generation and code summarization. However, the black-box nature of LLMs remains a major barrier to their adoption in high-stakes and safety-critical domains, where explainability and transparency are vital for trust, accountability, and effective human supervision. Despite increasing interest in explainable AI for software engineering, existing methods lack domain-specific explanations aligned with how practitioners reason about SE artifacts. To address this gap, we introduce FeatureSHAP, the first fully automated, model-agnostic explainability framework tailored to software engineering tasks. Based on Shapley values, FeatureSHAP attributes model outputs to high-level input features through systematic input perturbation and task-specific similarity comparisons, while remaining compatible with both open-source and proprietary LLMs. We evaluate FeatureSHAP on two bi-modal SE tasks: code generation and code summarization. The results show that FeatureSHAP assigns less importance to irrelevant input features and produces explanations with higher fidelity than baseline methods. A practitioner survey involving 37 participants shows that FeatureSHAP helps practitioners better interpret model outputs and make more informed decisions. Collectively, FeatureSHAP represents a meaningful step toward practical explainable AI in software engineering. FeatureSHAP is available at https://github.com/deviserlab/FeatureSHAP.
S-Chain: Structured Visual Chain-of-Thought For Medicine
Oct 26, 2025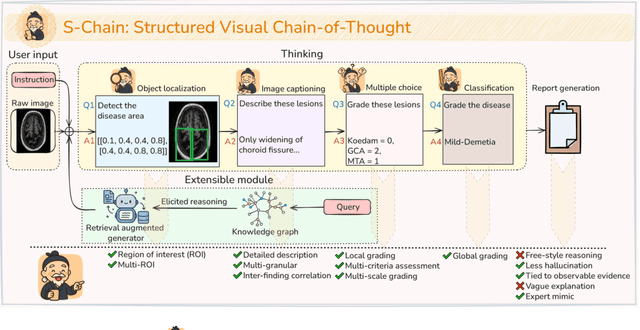
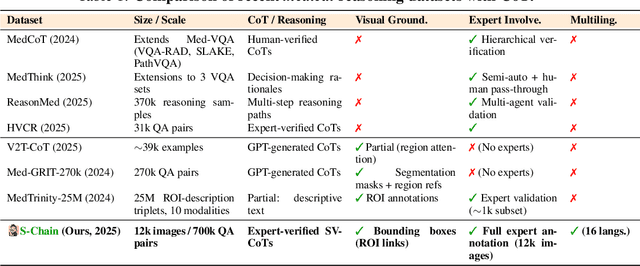
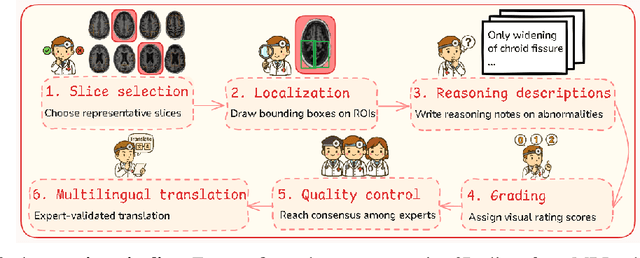
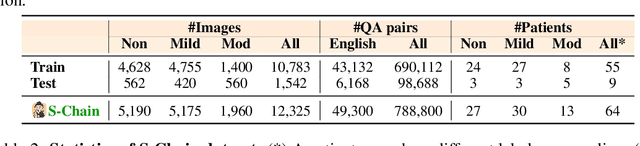
Faithful reasoning in medical vision-language models (VLMs) requires not only accurate predictions but also transparent alignment between textual rationales and visual evidence. While Chain-of-Thought (CoT) prompting has shown promise in medical visual question answering (VQA), no large-scale expert-level dataset has captured stepwise reasoning with precise visual grounding. We introduce S-Chain, the first large-scale dataset of 12,000 expert-annotated medical images with bounding boxes and structured visual CoT (SV-CoT), explicitly linking visual regions to reasoning steps. The dataset further supports 16 languages, totaling over 700k VQA pairs for broad multilingual applicability. Using S-Chain, we benchmark state-of-the-art medical VLMs (ExGra-Med, LLaVA-Med) and general-purpose VLMs (Qwen2.5-VL, InternVL2.5), showing that SV-CoT supervision significantly improves interpretability, grounding fidelity, and robustness. Beyond benchmarking, we study its synergy with retrieval-augmented generation, revealing how domain knowledge and visual grounding interact during autoregressive reasoning. Finally, we propose a new mechanism that strengthens the alignment between visual evidence and reasoning, improving both reliability and efficiency. S-Chain establishes a new benchmark for grounded medical reasoning and paves the way toward more trustworthy and explainable medical VLMs.
Vision Language Models are Biased
May 29, 2025Large language models (LLMs) memorize a vast amount of prior knowledge from the Internet that help them on downstream tasks but also may notoriously sway their outputs towards wrong or biased answers. In this work, we test how the knowledge about popular subjects hurt the accuracy of vision language models (VLMs) on standard, objective visual tasks of counting and identification. We find that state-of-the-art VLMs are strongly biased (e.g, unable to recognize a fourth stripe has been added to a 3-stripe Adidas logo) scoring an average of 17.05% accuracy in counting (e.g., counting stripes in an Adidas-like logo) across 7 diverse domains from animals, logos, chess, board games, optical illusions, to patterned grids. Insert text (e.g., "Adidas") describing the subject name into the counterfactual image further decreases VLM accuracy. The biases in VLMs are so strong that instructing them to double-check their results or rely exclusively on image details to answer improves counting accuracy by only +2 points, on average. Our work presents an interesting failure mode in VLMs and an automated framework for testing VLM biases. Code and data are available at: vlmsarebiased.github.io.
Sentiment Reasoning for Healthcare
Jul 24, 2024


Transparency in AI decision-making is crucial in healthcare due to the severe consequences of errors, and this is important for building trust among AI and users in sentiment analysis task. Incorporating reasoning capabilities helps Large Language Models (LLMs) understand human emotions within broader contexts, handle nuanced and ambiguous language, and infer underlying sentiments that may not be explicitly stated. In this work, we introduce a new task - Sentiment Reasoning - for both speech and text modalities, along with our proposed multimodal multitask framework and dataset. Our study showed that rationale-augmented training enhances model performance in sentiment classification across both human transcript and ASR settings. Also, we found that the generated rationales typically exhibit different vocabularies compared to human-generated rationales, but maintain similar semantics. All code, data (English-translated and Vietnamese) and models are published online: https://github.com/leduckhai/MultiMed
Real-time Speech Summarization for Medical Conversations
Jun 22, 2024In doctor-patient conversations, identifying medically relevant information is crucial, posing the need for conversation summarization. In this work, we propose the first deployable real-time speech summarization system for real-world applications in industry, which generates a local summary after every N speech utterances within a conversation and a global summary after the end of a conversation. Our system could enhance user experience from a business standpoint, while also reducing computational costs from a technical perspective. Secondly, we present VietMed-Sum which, to our knowledge, is the first speech summarization dataset for medical conversations. Thirdly, we are the first to utilize LLM and human annotators collaboratively to create gold standard and synthetic summaries for medical conversation summarization. Finally, we present baseline results of state-of-the-art models on VietMed-Sum. All code, data (English-translated and Vietnamese) and models are available online: https://github.com/leduckhai/MultiMed
Getting Away with More Network Pruning: From Sparsity to Geometry and Linear Regions
Jan 19, 2023



One surprising trait of neural networks is the extent to which their connections can be pruned with little to no effect on accuracy. But when we cross a critical level of parameter sparsity, pruning any further leads to a sudden drop in accuracy. This drop plausibly reflects a loss in model complexity, which we aim to avoid. In this work, we explore how sparsity also affects the geometry of the linear regions defined by a neural network, and consequently reduces the expected maximum number of linear regions based on the architecture. We observe that pruning affects accuracy similarly to how sparsity affects the number of linear regions and our proposed bound for the maximum number. Conversely, we find out that selecting the sparsity across layers to maximize our bound very often improves accuracy in comparison to pruning as much with the same sparsity in all layers, thereby providing us guidance on where to prune.
Like a bilingual baby: The advantage of visually grounding a bilingual language model
Oct 11, 2022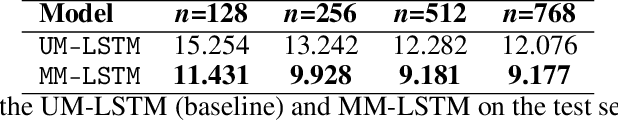
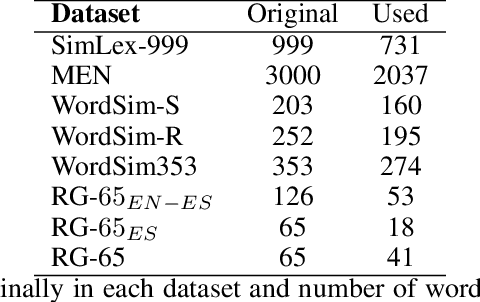
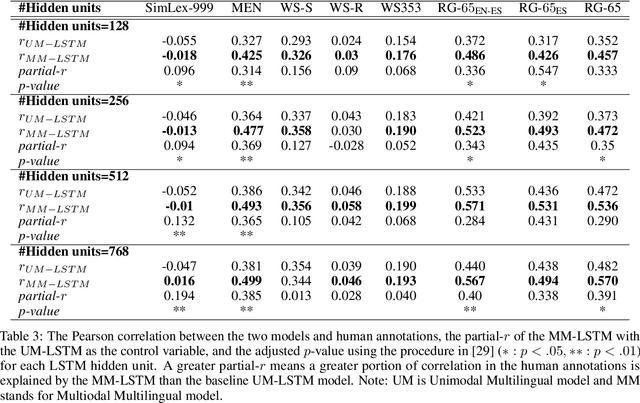

Unlike most neural language models, humans learn language in a rich, multi-sensory and, often, multi-lingual environment. Current language models typically fail to fully capture the complexities of multilingual language use. We train an LSTM language model on images and captions in English and Spanish from MS-COCO-ES. We find that the visual grounding improves the model's understanding of semantic similarity both within and across languages and improves perplexity. However, we find no significant advantage of visual grounding for abstract words. Our results provide additional evidence of the advantages of visually grounded language models and point to the need for more naturalistic language data from multilingual speakers and multilingual datasets with perceptual grounding.