 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeID-PaS : Identity-Aware Predict-and-Search for General Mixed-Integer Linear Programs
Dec 11, 2025Mixed-Integer Linear Programs (MIPs) are powerful and flexible tools for modeling a wide range of real-world combinatorial optimization problems. Predict-and-Search methods operate by using a predictive model to estimate promising variable assignments and then guiding a search procedure toward high-quality solutions. Recent research has demonstrated that incorporating machine learning (ML) into the Predict-and-Search framework significantly enhances its performance. Still, it is restricted to binary problems and overlooks the presence of fixed variables that commonly arise in practical settings. This work extends the Predict-and-Search (PaS) framework to parametric MIPs and introduces ID-PaS, an identity-aware learning framework that enables the ML model to handle heterogeneous variables more effectively. Experiments on several real-world large-scale problems demonstrate that ID-PaS consistently achieves superior performance compared to the state-of-the-art solver Gurobi and PaS.
Global Constraint LLM Agents for Text-to-Model Translation
Sep 10, 2025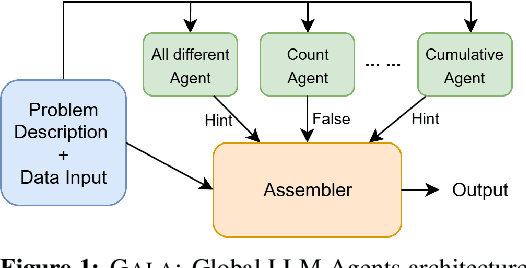

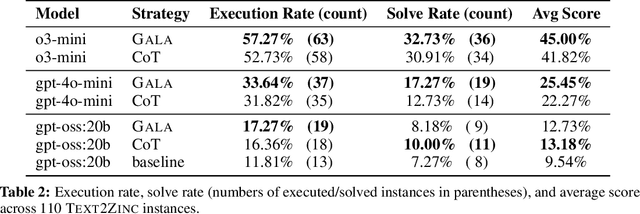
Natural language descriptions of optimization or satisfaction problems are challenging to translate into correct MiniZinc models, as this process demands both logical reasoning and constraint programming expertise. We introduce a framework that addresses this challenge with an agentic approach: multiple specialized large language model (LLM) agents decompose the modeling task by global constraint type. Each agent is dedicated to detecting and generating code for a specific class of global constraint, while a final assembler agent integrates these constraint snippets into a complete MiniZinc model. By dividing the problem into smaller, well-defined sub-tasks, each LLM handles a simpler reasoning challenge, potentially reducing overall complexity. We conduct initial experiments with several LLMs and show better performance against baselines such as one-shot prompting and chain-of-thought prompting. Finally, we outline a comprehensive roadmap for future work, highlighting potential enhancements and directions for improvement.
Balans: Multi-Armed Bandits-based Adaptive Large Neighborhood Search for Mixed-Integer Programming Problem
Dec 18, 2024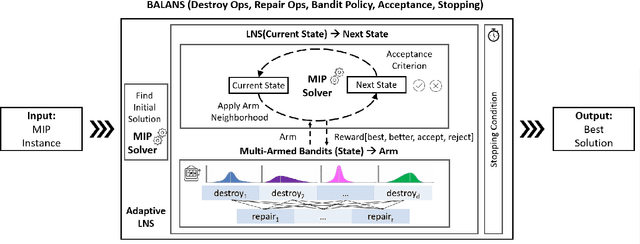
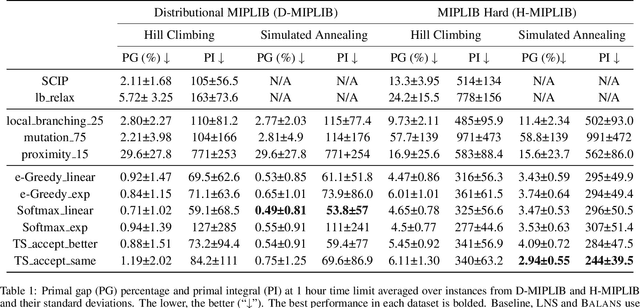
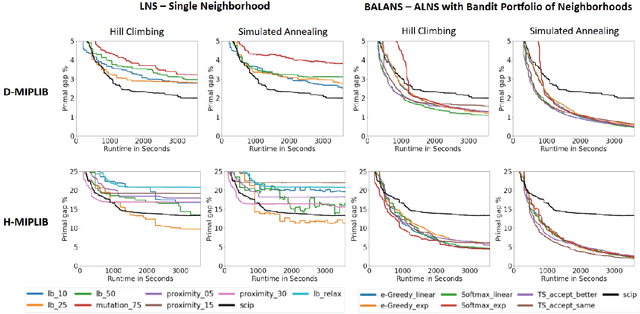

Mixed-Integer Programming (MIP) is a powerful paradigm for modeling and solving various important combinatorial optimization problems. Recently, learning-based approaches have shown potential to speed up MIP solving via offline training that then guides important design decisions during search. However, a significant drawback of these methods is their heavy reliance on offline training, which requires collecting training datasets and computationally costly training epochs yet offering only limited generalization to unseen (larger) instances. In this paper, we propose Balans, an adaptive meta-solver for MIPs with online learning capability that does not require any supervision or apriori training. At its core, Balans is based on adaptive large-neighborhood search, operating on top of a MIP solver by successive applications of destroy and repair neighborhood operators. During the search, the selection among different neighborhood definitions is guided on the fly for the instance at hand via multi-armed bandit algorithms. Our extensive experiments on hard optimization instances show that Balans offers significant performance gains over the default MIP solver, is better than committing to any single best neighborhood, and improves over the state-of-the-art large-neighborhood search for MIPs. Finally, we release Balans as a highly configurable, MIP solver agnostic, open-source software.
Multi-task Representation Learning for Mixed Integer Linear Programming
Dec 18, 2024



Mixed Integer Linear Programs (MILPs) are highly flexible and powerful tools for modeling and solving complex real-world combinatorial optimization problems. Recently, machine learning (ML)-guided approaches have demonstrated significant potential in improving MILP-solving efficiency. However, these methods typically rely on separate offline data collection and training processes, which limits their scalability and adaptability. This paper introduces the first multi-task learning framework for ML-guided MILP solving. The proposed framework provides MILP embeddings helpful in guiding MILP solving across solvers (e.g., Gurobi and SCIP) and across tasks (e.g., Branching and Solver configuration). Through extensive experiments on three widely used MILP benchmarks, we demonstrate that our multi-task learning model performs similarly to specialized models within the same distribution. Moreover, it significantly outperforms them in generalization across problem sizes and tasks.
Learning Backdoors for Mixed Integer Programs with Contrastive Learning
Jan 19, 2024Many real-world problems can be efficiently modeled as Mixed Integer Programs (MIPs) and solved with the Branch-and-Bound method. Prior work has shown the existence of MIP backdoors, small sets of variables such that prioritizing branching on them when possible leads to faster running times. However, finding high-quality backdoors that improve running times remains an open question. Previous work learns to estimate the relative solver speed of randomly sampled backdoors through ranking and then decide whether to use it. In this paper, we utilize the Monte-Carlo tree search method to collect backdoors for training, rather than relying on random sampling, and adapt a contrastive learning framework to train a Graph Attention Network model to predict backdoors. Our method, evaluated on four common MIP problem domains, demonstrates performance improvements over both Gurobi and previous models.
Optimization Over Trained Neural Networks: Taking a Relaxing Walk
Jan 07, 2024Besides training, mathematical optimization is also used in deep learning to model and solve formulations over trained neural networks for purposes such as verification, compression, and optimization with learned constraints. However, solving these formulations soon becomes difficult as the network size grows due to the weak linear relaxation and dense constraint matrix. We have seen improvements in recent years with cutting plane algorithms, reformulations, and an heuristic based on Mixed-Integer Linear Programming (MILP). In this work, we propose a more scalable heuristic based on exploring global and local linear relaxations of the neural network model. Our heuristic is competitive with a state-of-the-art MILP solver and the prior heuristic while producing better solutions with increases in input, depth, and number of neurons.
Getting Away with More Network Pruning: From Sparsity to Geometry and Linear Regions
Jan 19, 2023



One surprising trait of neural networks is the extent to which their connections can be pruned with little to no effect on accuracy. But when we cross a critical level of parameter sparsity, pruning any further leads to a sudden drop in accuracy. This drop plausibly reflects a loss in model complexity, which we aim to avoid. In this work, we explore how sparsity also affects the geometry of the linear regions defined by a neural network, and consequently reduces the expected maximum number of linear regions based on the architecture. We observe that pruning affects accuracy similarly to how sparsity affects the number of linear regions and our proposed bound for the maximum number. Conversely, we find out that selecting the sparsity across layers to maximize our bound very often improves accuracy in comparison to pruning as much with the same sparsity in all layers, thereby providing us guidance on where to prune.