 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKronecker-Structured Nonparametric Spatiotemporal Point Processes
Mar 24, 2026Events in spatiotemporal domains arise in numerous real-world applications, where uncovering event relationships and enabling accurate prediction are central challenges. Classical Poisson and Hawkes processes rely on restrictive parametric assumptions that limit their ability to capture complex interaction patterns, while recent neural point process models increase representational capacity but integrate event information in a black-box manner, hindering interpretable relationship discovery. To address these limitations, we propose a Kronecker-Structured Nonparametric Spatiotemporal Point Process (KSTPP) that enables transparent event-wise relationship discovery while retaining high modeling flexibility. We model the background intensity with a spatial Gaussian process (GP) and the influence kernel as a spatiotemporal GP, allowing rich interaction patterns including excitation, inhibition, neutrality, and time-varying effects. To enable scalable training and prediction, we adopt separable product kernels and represent the GPs on structured grids, inducing Kronecker-structured covariance matrices. Exploiting Kronecker algebra substantially reduces computational cost and allows the model to scale to large event collections. In addition, we develop a tensor-product Gauss-Legendre quadrature scheme to efficiently evaluate intractable likelihood integrals. Extensive experiments demonstrate the effectiveness of our framework.
Diffusion-Based Symbolic Regression
May 30, 2025



Diffusion has emerged as a powerful framework for generative modeling, achieving remarkable success in applications such as image and audio synthesis. Enlightened by this progress, we propose a novel diffusion-based approach for symbolic regression. We construct a random mask-based diffusion and denoising process to generate diverse and high-quality equations. We integrate this generative processes with a token-wise Group Relative Policy Optimization (GRPO) method to conduct efficient reinforcement learning on the given measurement dataset. In addition, we introduce a long short-term risk-seeking policy to expand the pool of top-performing candidates, further enhancing performance. Extensive experiments and ablation studies have demonstrated the effectiveness of our approach.
Graph-Based Operator Learning from Limited Data on Irregular Domains
May 25, 2025Operator learning seeks to approximate mappings from input functions to output solutions, particularly in the context of partial differential equations (PDEs). While recent advances such as DeepONet and Fourier Neural Operator (FNO) have demonstrated strong performance, they often rely on regular grid discretizations, limiting their applicability to complex or irregular domains. In this work, we propose a Graph-based Operator Learning with Attention (GOLA) framework that addresses this limitation by constructing graphs from irregularly sampled spatial points and leveraging attention-enhanced Graph Neural Netwoks (GNNs) to model spatial dependencies with global information. To improve the expressive capacity, we introduce a Fourier-based encoder that projects input functions into a frequency space using learnable complex coefficients, allowing for flexible embeddings even with sparse or nonuniform samples. We evaluated our approach across a range of 2D PDEs, including Darcy Flow, Advection, Eikonal, and Nonlinear Diffusion, under varying sampling densities. Our method consistently outperforms baselines, particularly in data-scarce regimes, demonstrating strong generalization and efficiency on irregular domains.
Spatio-temporal Fourier Transformer (StFT) for Long-term Dynamics Prediction
Mar 14, 2025Simulating the long-term dynamics of multi-scale and multi-physics systems poses a significant challenge in understanding complex phenomena across science and engineering. The complexity arises from the intricate interactions between scales and the interplay of diverse physical processes. Neural operators have emerged as promising models for predicting such dynamics due to their flexibility and computational efficiency. However, they often fail to effectively capture multi-scale interactions or quantify the uncertainties inherent in the predictions. These limitations lead to rapid error accumulation, particularly in long-term forecasting of systems characterized by complex and coupled dynamics. To address these challenges, we propose a spatio-temporal Fourier transformer (StFT), in which each transformer block is designed to learn dynamics at a specific scale. By leveraging a structured hierarchy of StFT blocks, the model explicitly captures dynamics across both macro- and micro- spatial scales. Furthermore, a generative residual correction mechanism is integrated to estimate and mitigate predictive uncertainties, enhancing both the accuracy and reliability of long-term forecasts. Evaluations conducted on three benchmark datasets (plasma, fluid, and atmospheric dynamics) demonstrate the advantages of our approach over state-of-the-art ML methods.
Pseudo-Physics-Informed Neural Operators: Enhancing Operator Learning from Limited Data
Feb 04, 2025



Neural operators have shown great potential in surrogate modeling. However, training a well-performing neural operator typically requires a substantial amount of data, which can pose a major challenge in complex applications. In such scenarios, detailed physical knowledge can be unavailable or difficult to obtain, and collecting extensive data is often prohibitively expensive. To mitigate this challenge, we propose the Pseudo Physics-Informed Neural Operator (PPI-NO) framework. PPI-NO constructs a surrogate physics system for the target system using partial differential equations (PDEs) derived from simple, rudimentary physics principles, such as basic differential operators. This surrogate system is coupled with a neural operator model, using an alternating update and learning process to iteratively enhance the model's predictive power. While the physics derived via PPI-NO may not mirror the ground-truth underlying physical laws -- hence the term ``pseudo physics'' -- this approach significantly improves the accuracy of standard operator learning models in data-scarce scenarios, which is evidenced by extensive evaluations across five benchmark tasks and a fatigue modeling application.
Arbitrarily-Conditioned Multi-Functional Diffusion for Multi-Physics Emulation
Oct 17, 2024Modern physics simulation often involves multiple functions of interests, and traditional numerical approaches are known to be complex and computationally costly. While machine learning-based surrogate models can offer significant cost reductions, most focus on a single task, such as forward prediction, and typically lack uncertainty quantification -- an essential component in many applications. To overcome these limitations, we propose Arbitrarily-Conditioned Multi-Functional Diffusion (ACMFD), a versatile probabilistic surrogate model for multi-physics emulation. ACMFD can perform a wide range of tasks within a single framework, including forward prediction, various inverse problems, and simulating data for entire systems or subsets of quantities conditioned on others. Specifically, we extend the standard Denoising Diffusion Probabilistic Model (DDPM) for multi-functional generation by modeling noise as Gaussian processes (GP). We then introduce an innovative denoising loss. The training involves randomly sampling the conditioned part and fitting the corresponding predicted noise to zero, enabling ACMFD to flexibly generate function values conditioned on any other functions or quantities. To enable efficient training and sampling, and to flexibly handle irregularly sampled data, we use GPs to interpolate function samples onto a grid, inducing a Kronecker product structure for efficient computation. We demonstrate the advantages of ACMFD across several fundamental multi-physics systems.
Toward Efficient Kernel-Based Solvers for Nonlinear PDEs
Oct 15, 2024This paper introduces a novel kernel learning framework toward efficiently solving nonlinear partial differential equations (PDEs). In contrast to the state-of-the-art kernel solver that embeds differential operators within kernels, posing challenges with a large number of collocation points, our approach eliminates these operators from the kernel. We model the solution using a standard kernel interpolation form and differentiate the interpolant to compute the derivatives. Our framework obviates the need for complex Gram matrix construction between solutions and their derivatives, allowing for a straightforward implementation and scalable computation. As an instance, we allocate the collocation points on a grid and adopt a product kernel, which yields a Kronecker product structure in the interpolation. This structure enables us to avoid computing the full Gram matrix, reducing costs and scaling efficiently to a large number of collocation points. We provide a proof of the convergence and rate analysis of our method under appropriate regularity assumptions. In numerical experiments, we demonstrate the advantages of our method in solving several benchmark PDEs.
HyResPINNs: Adaptive Hybrid Residual Networks for Learning Optimal Combinations of Neural and RBF Components for Physics-Informed Modeling
Oct 04, 2024



Physics-informed neural networks (PINNs) are an increasingly popular class of techniques for the numerical solution of partial differential equations (PDEs), where neural networks are trained using loss functions regularized by relevant PDE terms to enforce physical constraints. We present a new class of PINNs called HyResPINNs, which augment traditional PINNs with adaptive hybrid residual blocks that combine the outputs of a standard neural network and a radial basis function (RBF) network. A key feature of our method is the inclusion of adaptive combination parameters within each residual block, which dynamically learn to weigh the contributions of the neural network and RBF network outputs. Additionally, adaptive connections between residual blocks allow for flexible information flow throughout the network. We show that HyResPINNs are more robust to training point locations and neural network architectures than traditional PINNs. Moreover, HyResPINNs offer orders of magnitude greater accuracy than competing methods on certain problems, with only modest increases in training costs. We demonstrate the strengths of our approach on challenging PDEs, including the Allen-Cahn equation and the Darcy-Flow equation. Our results suggest that HyResPINNs effectively bridge the gap between traditional numerical methods and modern machine learning-based solvers.
Fourier PINNs: From Strong Boundary Conditions to Adaptive Fourier Bases
Oct 04, 2024



Interest is rising in Physics-Informed Neural Networks (PINNs) as a mesh-free alternative to traditional numerical solvers for partial differential equations (PDEs). However, PINNs often struggle to learn high-frequency and multi-scale target solutions. To tackle this problem, we first study a strong Boundary Condition (BC) version of PINNs for Dirichlet BCs and observe a consistent decline in relative error compared to the standard PINNs. We then perform a theoretical analysis based on the Fourier transform and convolution theorem. We find that strong BC PINNs can better learn the amplitudes of high-frequency components of the target solutions. However, constructing the architecture for strong BC PINNs is difficult for many BCs and domain geometries. Enlightened by our theoretical analysis, we propose Fourier PINNs -- a simple, general, yet powerful method that augments PINNs with pre-specified, dense Fourier bases. Our proposed architecture likewise learns high-frequency components better but places no restrictions on the particular BCs or problem domains. We develop an adaptive learning and basis selection algorithm via alternating neural net basis optimization, Fourier and neural net basis coefficient estimation, and coefficient truncation. This scheme can flexibly identify the significant frequencies while weakening the nominal frequencies to better capture the target solution's power spectrum. We show the advantage of our approach through a set of systematic experiments.
Kernel Neural Operators (KNOs) for Scalable, Memory-efficient, Geometrically-flexible Operator Learning
Jun 30, 2024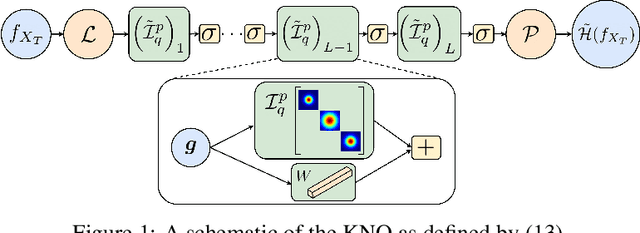
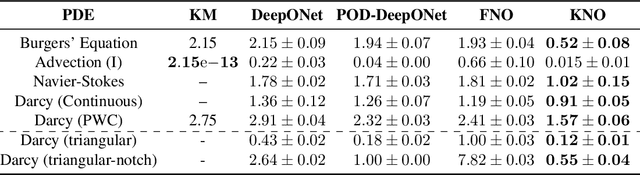
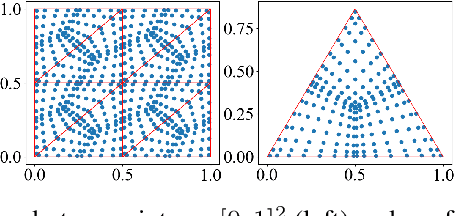
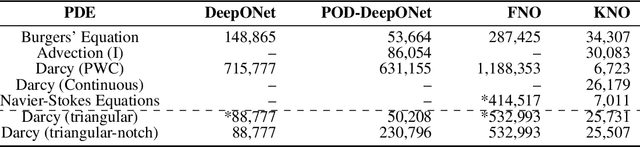
This paper introduces the Kernel Neural Operator (KNO), a novel operator learning technique that uses deep kernel-based integral operators in conjunction with quadrature for function-space approximation of operators (maps from functions to functions). KNOs use parameterized, closed-form, finitely-smooth, and compactly-supported kernels with trainable sparsity parameters within the integral operators to significantly reduce the number of parameters that must be learned relative to existing neural operators. Moreover, the use of quadrature for numerical integration endows the KNO with geometric flexibility that enables operator learning on irregular geometries. Numerical results demonstrate that on existing benchmarks the training and test accuracy of KNOs is higher than popular operator learning techniques while using at least an order of magnitude fewer trainable parameters. KNOs thus represent a new paradigm of low-memory, geometrically-flexible, deep operator learning, while retaining the implementation simplicity and transparency of traditional kernel methods from both scientific computing and machine learning.