 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFluids You Can Trust: Property-Preserving Operator Learning for Incompressible Flows
Feb 17, 2026We present a novel property-preserving kernel-based operator learning method for incompressible flows governed by the incompressible Navier-Stokes equations. Traditional numerical solvers incur significant computational costs to respect incompressibility. Operator learning offers efficient surrogate models, but current neural operators fail to exactly enforce physical properties such as incompressibility, periodicity, and turbulence. Our method maps input functions to expansion coefficients of output functions in a property-preserving kernel basis, ensuring that predicted velocity fields analytically and simultaneously preserve the aforementioned physical properties. We evaluate the method on challenging 2D and 3D, laminar and turbulent, incompressible flow problems. Our method achieves up to six orders of magnitude lower relative $\ell_2$ errors upon generalization and trains up to five orders of magnitude faster compared to neural operators. Moreover, while our method enforces incompressibility analytically, neural operators exhibit very large deviations. Our results show that our method provides an accurate and efficient surrogate for incompressible flows.
Fourier PINNs: From Strong Boundary Conditions to Adaptive Fourier Bases
Oct 04, 2024



Interest is rising in Physics-Informed Neural Networks (PINNs) as a mesh-free alternative to traditional numerical solvers for partial differential equations (PDEs). However, PINNs often struggle to learn high-frequency and multi-scale target solutions. To tackle this problem, we first study a strong Boundary Condition (BC) version of PINNs for Dirichlet BCs and observe a consistent decline in relative error compared to the standard PINNs. We then perform a theoretical analysis based on the Fourier transform and convolution theorem. We find that strong BC PINNs can better learn the amplitudes of high-frequency components of the target solutions. However, constructing the architecture for strong BC PINNs is difficult for many BCs and domain geometries. Enlightened by our theoretical analysis, we propose Fourier PINNs -- a simple, general, yet powerful method that augments PINNs with pre-specified, dense Fourier bases. Our proposed architecture likewise learns high-frequency components better but places no restrictions on the particular BCs or problem domains. We develop an adaptive learning and basis selection algorithm via alternating neural net basis optimization, Fourier and neural net basis coefficient estimation, and coefficient truncation. This scheme can flexibly identify the significant frequencies while weakening the nominal frequencies to better capture the target solution's power spectrum. We show the advantage of our approach through a set of systematic experiments.
HyResPINNs: Adaptive Hybrid Residual Networks for Learning Optimal Combinations of Neural and RBF Components for Physics-Informed Modeling
Oct 04, 2024



Physics-informed neural networks (PINNs) are an increasingly popular class of techniques for the numerical solution of partial differential equations (PDEs), where neural networks are trained using loss functions regularized by relevant PDE terms to enforce physical constraints. We present a new class of PINNs called HyResPINNs, which augment traditional PINNs with adaptive hybrid residual blocks that combine the outputs of a standard neural network and a radial basis function (RBF) network. A key feature of our method is the inclusion of adaptive combination parameters within each residual block, which dynamically learn to weigh the contributions of the neural network and RBF network outputs. Additionally, adaptive connections between residual blocks allow for flexible information flow throughout the network. We show that HyResPINNs are more robust to training point locations and neural network architectures than traditional PINNs. Moreover, HyResPINNs offer orders of magnitude greater accuracy than competing methods on certain problems, with only modest increases in training costs. We demonstrate the strengths of our approach on challenging PDEs, including the Allen-Cahn equation and the Darcy-Flow equation. Our results suggest that HyResPINNs effectively bridge the gap between traditional numerical methods and modern machine learning-based solvers.
Kernel Neural Operators (KNOs) for Scalable, Memory-efficient, Geometrically-flexible Operator Learning
Jun 30, 2024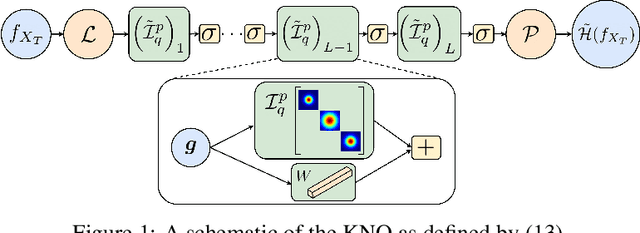
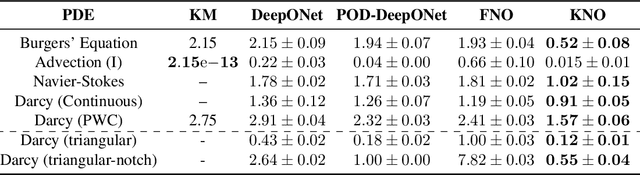
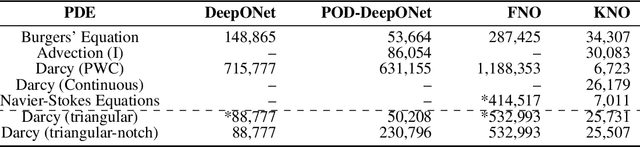
This paper introduces the Kernel Neural Operator (KNO), a novel operator learning technique that uses deep kernel-based integral operators in conjunction with quadrature for function-space approximation of operators (maps from functions to functions). KNOs use parameterized, closed-form, finitely-smooth, and compactly-supported kernels with trainable sparsity parameters within the integral operators to significantly reduce the number of parameters that must be learned relative to existing neural operators. Moreover, the use of quadrature for numerical integration endows the KNO with geometric flexibility that enables operator learning on irregular geometries. Numerical results demonstrate that on existing benchmarks the training and test accuracy of KNOs is higher than popular operator learning techniques while using at least an order of magnitude fewer trainable parameters. KNOs thus represent a new paradigm of low-memory, geometrically-flexible, deep operator learning, while retaining the implementation simplicity and transparency of traditional kernel methods from both scientific computing and machine learning.
Polynomial-Augmented Neural Networks (PANNs) with Weak Orthogonality Constraints for Enhanced Function and PDE Approximation
Jun 04, 2024



We present polynomial-augmented neural networks (PANNs), a novel machine learning architecture that combines deep neural networks (DNNs) with a polynomial approximant. PANNs combine the strengths of DNNs (flexibility and efficiency in higher-dimensional approximation) with those of polynomial approximation (rapid convergence rates for smooth functions). To aid in both stable training and enhanced accuracy over a variety of problems, we present (1) a family of orthogonality constraints that impose mutual orthogonality between the polynomial and the DNN within a PANN; (2) a simple basis pruning approach to combat the curse of dimensionality introduced by the polynomial component; and (3) an adaptation of a polynomial preconditioning strategy to both DNNs and polynomials. We test the resulting architecture for its polynomial reproduction properties, ability to approximate both smooth functions and functions of limited smoothness, and as a method for the solution of partial differential equations (PDEs). Through these experiments, we demonstrate that PANNs offer superior approximation properties to DNNs for both regression and the numerical solution of PDEs, while also offering enhanced accuracy over both polynomial and DNN-based regression (each) when regressing functions with limited smoothness.
Ensemble and Mixture-of-Experts DeepONets For Operator Learning
May 21, 2024We present a novel deep operator network (DeepONet) architecture for operator learning, the ensemble DeepONet, that allows for enriching the trunk network of a single DeepONet with multiple distinct trunk networks. This trunk enrichment allows for greater expressivity and generalization capabilities over a range of operator learning problems. We also present a spatial mixture-of-experts (MoE) DeepONet trunk network architecture that utilizes a partition-of-unity (PoU) approximation to promote spatial locality and model sparsity in the operator learning problem. We first prove that both the ensemble and PoU-MoE DeepONets are universal approximators. We then demonstrate that ensemble DeepONets containing a trunk ensemble of a standard trunk, the PoU-MoE trunk, and/or a proper orthogonal decomposition (POD) trunk can achieve 2-4x lower relative $\ell_2$ errors than standard DeepONets and POD-DeepONets on both standard and challenging new operator learning problems involving partial differential equations (PDEs) in two and three dimensions. Our new PoU-MoE formulation provides a natural way to incorporate spatial locality and model sparsity into any neural network architecture, while our new ensemble DeepONet provides a powerful and general framework for incorporating basis enrichment in scientific machine learning architectures for operator learning.
Locally Adaptive and Differentiable Regression
Aug 14, 2023
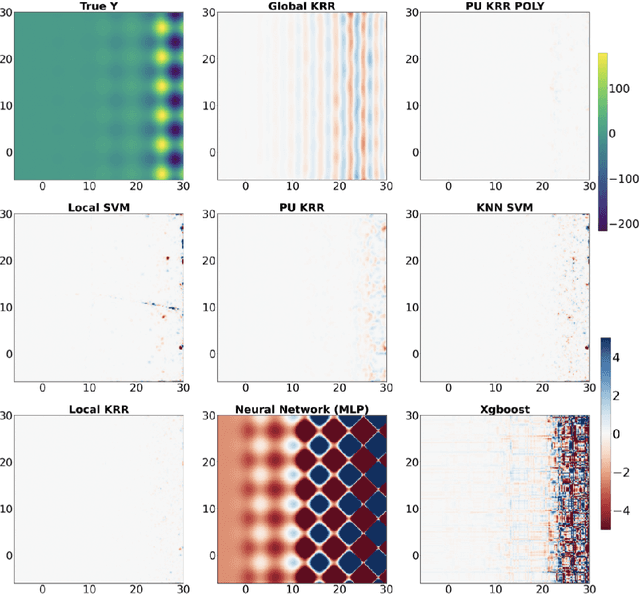

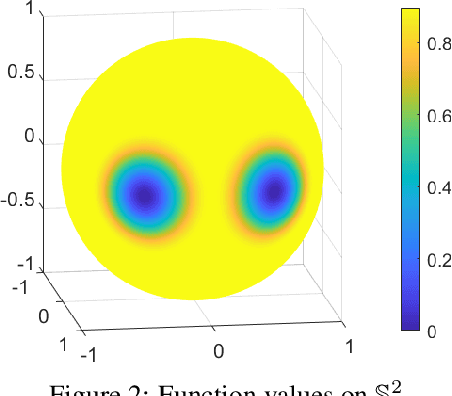
Over-parameterized models like deep nets and random forests have become very popular in machine learning. However, the natural goals of continuity and differentiability, common in regression models, are now often ignored in modern overparametrized, locally-adaptive models. We propose a general framework to construct a global continuous and differentiable model based on a weighted average of locally learned models in corresponding local regions. This model is competitive in dealing with data with different densities or scales of function values in different local regions. We demonstrate that when we mix kernel ridge and polynomial regression terms in the local models, and stitch them together continuously, we achieve faster statistical convergence in theory and improved performance in various practical settings.
Differentiable Turbulence II
Jul 25, 2023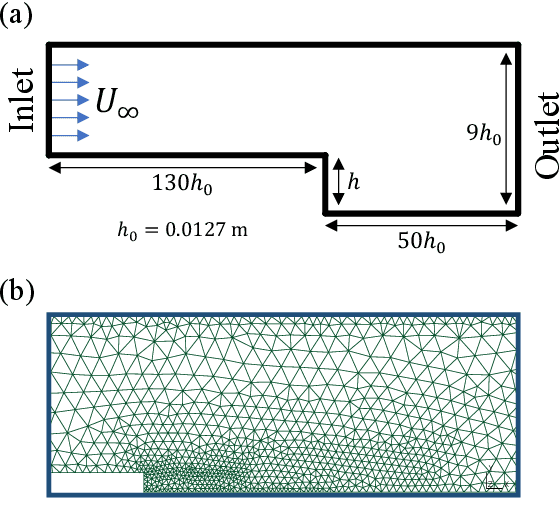

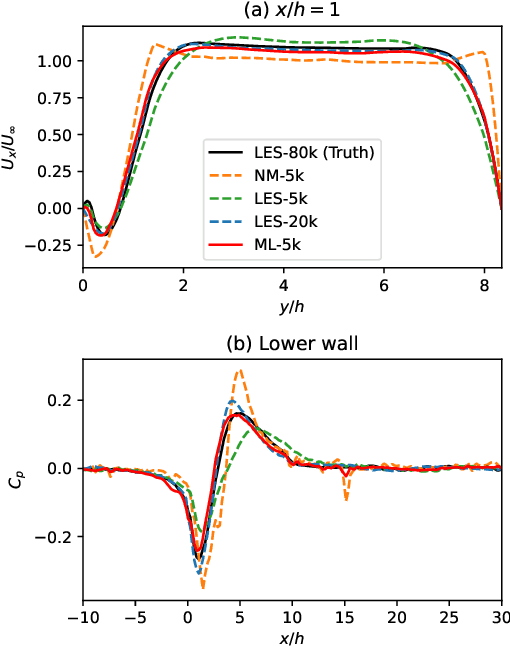
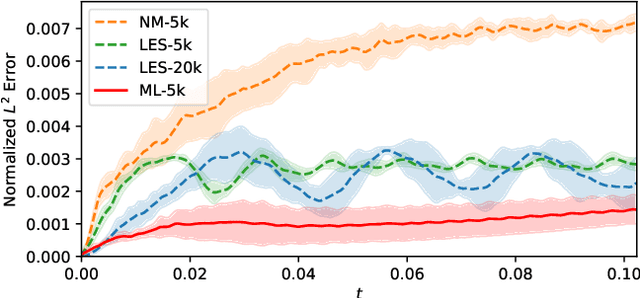
Differentiable fluid simulators are increasingly demonstrating value as useful tools for developing data-driven models in computational fluid dynamics (CFD). Differentiable turbulence, or the end-to-end training of machine learning (ML) models embedded in CFD solution algorithms, captures both the generalization power and limited upfront cost of physics-based simulations, and the flexibility and automated training of deep learning methods. We develop a framework for integrating deep learning models into a generic finite element numerical scheme for solving the Navier-Stokes equations, applying the technique to learn a sub-grid scale closure using a multi-scale graph neural network. We demonstrate the method on several realizations of flow over a backwards-facing step, testing on both unseen Reynolds numbers and new geometry. We show that the learned closure can achieve accuracy comparable to traditional large eddy simulation on a finer grid that amounts to an equivalent speedup of 10x. As the desire and need for cheaper CFD simulations grows, we see hybrid physics-ML methods as a path forward to be exploited in the near future.
Differentiable Turbulence
Jul 07, 2023


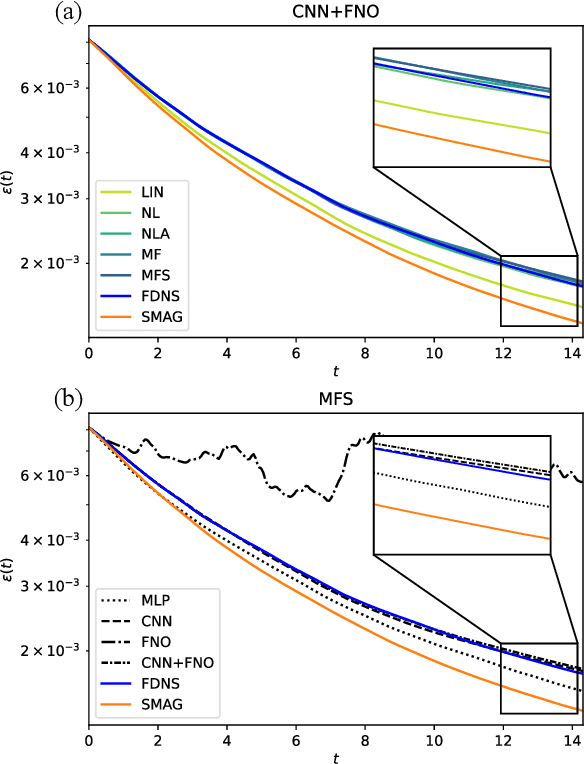
Deep learning is increasingly becoming a promising pathway to improving the accuracy of sub-grid scale (SGS) turbulence closure models for large eddy simulations (LES). We leverage the concept of differentiable turbulence, whereby an end-to-end differentiable solver is used in combination with physics-inspired choices of deep learning architectures to learn highly effective and versatile SGS models for two-dimensional turbulent flow. We perform an in-depth analysis of the inductive biases in the chosen architectures, finding that the inclusion of small-scale non-local features is most critical to effective SGS modeling, while large-scale features can improve pointwise accuracy of the a-posteriori solution field. The filtered velocity gradient tensor can be mapped directly to the SGS stress via decomposition of the inputs and outputs into isotropic, deviatoric, and anti-symmetric components. We see that the model can generalize to a variety of flow configurations, including higher and lower Reynolds numbers and different forcing conditions. We show that the differentiable physics paradigm is more successful than offline, a-priori learning, and that hybrid solver-in-the-loop approaches to deep learning offer an ideal balance between computational efficiency, accuracy, and generalization. Our experiments provide physics-based recommendations for deep-learning based SGS modeling for generalizable closure modeling of turbulence.
Multiscale Graph Neural Network Autoencoders for Interpretable Scientific Machine Learning
Feb 17, 2023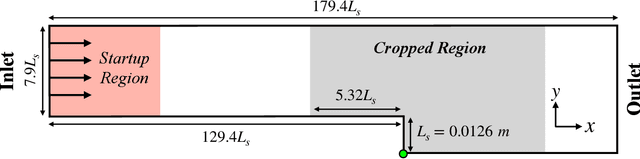
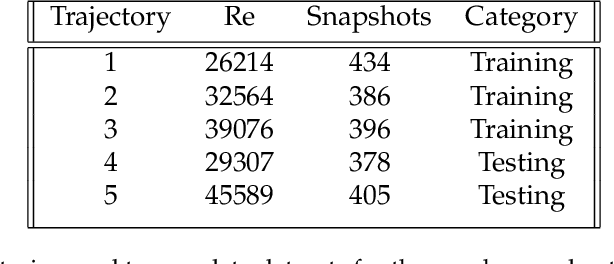
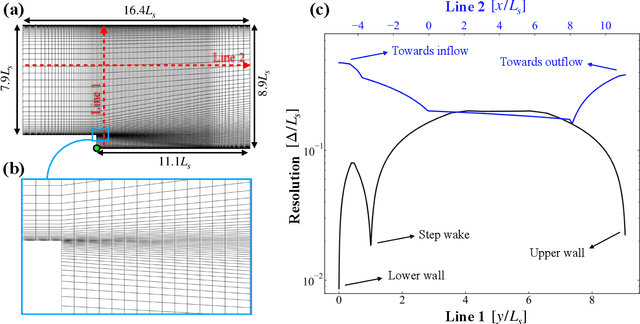
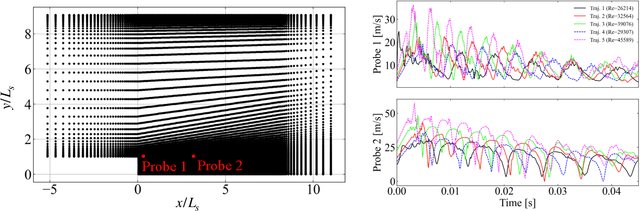
The goal of this work is to address two limitations in autoencoder-based models: latent space interpretability and compatibility with unstructured meshes. This is accomplished here with the development of a novel graph neural network (GNN) autoencoding architecture with demonstrations on complex fluid flow applications. To address the first goal of interpretability, the GNN autoencoder achieves reduction in the number nodes in the encoding stage through an adaptive graph reduction procedure. This reduction procedure essentially amounts to flowfield-conditioned node sampling and sensor identification, and produces interpretable latent graph representations tailored to the flowfield reconstruction task in the form of so-called masked fields. These masked fields allow the user to (a) visualize where in physical space a given latent graph is active, and (b) interpret the time-evolution of the latent graph connectivity in accordance with the time-evolution of unsteady flow features (e.g. recirculation zones, shear layers) in the domain. To address the goal of unstructured mesh compatibility, the autoencoding architecture utilizes a series of multi-scale message passing (MMP) layers, each of which models information exchange among node neighborhoods at various lengthscales. The MMP layer, which augments standard single-scale message passing with learnable coarsening operations, allows the decoder to more efficiently reconstruct the flowfield from the identified regions in the masked fields. Analysis of latent graphs produced by the autoencoder for various model settings are conducted using using unstructured snapshot data sourced from large-eddy simulations in a backward-facing step (BFS) flow configuration with an OpenFOAM-based flow solver at high Reynolds numbers.