 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-ICL: Enhancing Fine-Grained Emotion Recognition through the Lens of Prototype Theory
Jun 04, 2024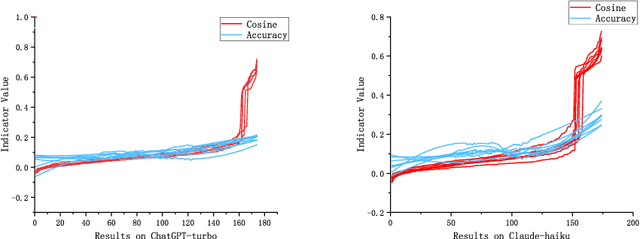
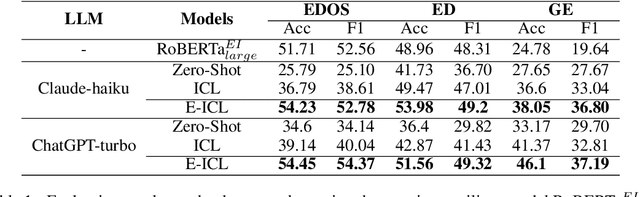
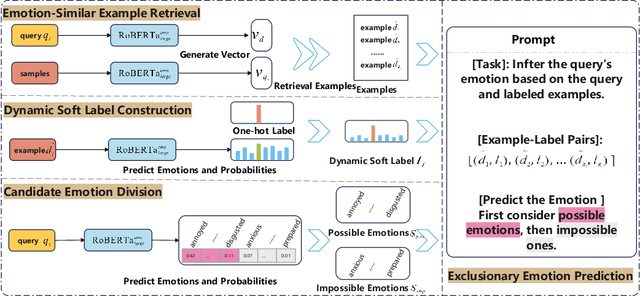
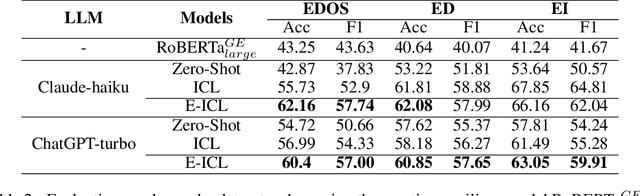
In-context learning (ICL) achieves remarkable performance in various domains such as knowledge acquisition, commonsense reasoning, and semantic understanding. However, its performance significantly deteriorates for emotion detection tasks, especially fine-grained emotion recognition. The underlying reasons for this remain unclear. In this paper, we identify the reasons behind ICL's poor performance from the perspective of prototype theory and propose a method to address this issue. Specifically, we conduct extensive pilot experiments and find that ICL conforms to the prototype theory on fine-grained emotion recognition. Based on this theory, we uncover the following deficiencies in ICL: (1) It relies on prototypes (example-label pairs) that are semantically similar but emotionally inaccurate to predict emotions. (2) It is prone to interference from irrelevant categories, affecting the accuracy and robustness of the predictions. To address these issues, we propose an Emotion Context Learning method (E-ICL) on fine-grained emotion recognition. E-ICL relies on more emotionally accurate prototypes to predict categories by referring to emotionally similar examples with dynamic labels. Simultaneously, E-ICL employs an exclusionary emotion prediction strategy to avoid interference from irrelevant categories, thereby increasing its accuracy and robustness. Note that the entire process is accomplished with the assistance of a plug-and-play emotion auxiliary model, without additional training. Experiments on the fine-grained emotion datasets EDOS, Empathetic-Dialogues, EmpatheticIntent, and GoEmotions show that E-ICL achieves superior emotion prediction performance. Furthermore, even when the emotion auxiliary model used is lower than 10% of the LLMs, E-ICL can still boost the performance of LLMs by over 4% on multiple datasets.
Deep Clustering Evaluation: How to Validate Internal Clustering Validation Measures
Mar 21, 2024Deep clustering, a method for partitioning complex, high-dimensional data using deep neural networks, presents unique evaluation challenges. Traditional clustering validation measures, designed for low-dimensional spaces, are problematic for deep clustering, which involves projecting data into lower-dimensional embeddings before partitioning. Two key issues are identified: 1) the curse of dimensionality when applying these measures to raw data, and 2) the unreliable comparison of clustering results across different embedding spaces stemming from variations in training procedures and parameter settings in different clustering models. This paper addresses these challenges in evaluating clustering quality in deep learning. We present a theoretical framework to highlight ineffectiveness arising from using internal validation measures on raw and embedded data and propose a systematic approach to applying clustering validity indices in deep clustering contexts. Experiments show that this framework aligns better with external validation measures, effectively reducing the misguidance from the improper use of clustering validity indices in deep learning.
Locally Adaptive and Differentiable Regression
Aug 14, 2023
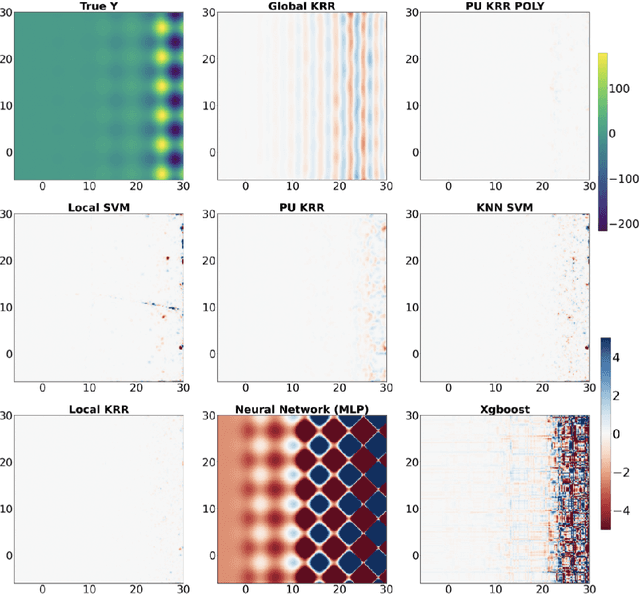

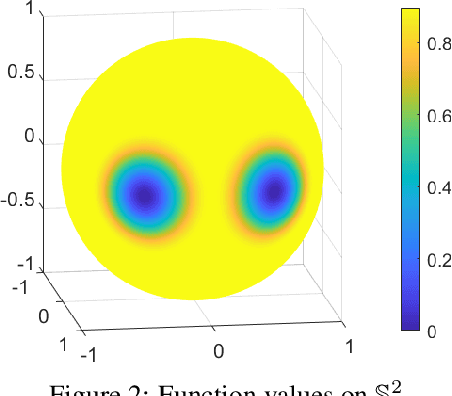
Over-parameterized models like deep nets and random forests have become very popular in machine learning. However, the natural goals of continuity and differentiability, common in regression models, are now often ignored in modern overparametrized, locally-adaptive models. We propose a general framework to construct a global continuous and differentiable model based on a weighted average of locally learned models in corresponding local regions. This model is competitive in dealing with data with different densities or scales of function values in different local regions. We demonstrate that when we mix kernel ridge and polynomial regression terms in the local models, and stitch them together continuously, we achieve faster statistical convergence in theory and improved performance in various practical settings.
The ART of Transfer Learning: An Adaptive and Robust Pipeline
Apr 30, 2023Transfer learning is an essential tool for improving the performance of primary tasks by leveraging information from auxiliary data resources. In this work, we propose Adaptive Robust Transfer Learning (ART), a flexible pipeline of performing transfer learning with generic machine learning algorithms. We establish the non-asymptotic learning theory of ART, providing a provable theoretical guarantee for achieving adaptive transfer while preventing negative transfer. Additionally, we introduce an ART-integrated-aggregating machine that produces a single final model when multiple candidate algorithms are considered. We demonstrate the promising performance of ART through extensive empirical studies on regression, classification, and sparse learning. We further present a real-data analysis for a mortality study.
Meta Clustering for Collaborative Learning
May 29, 2020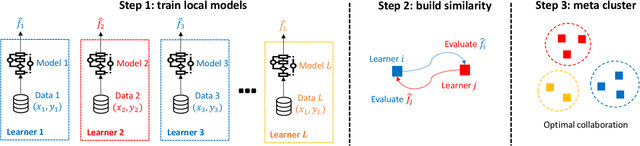
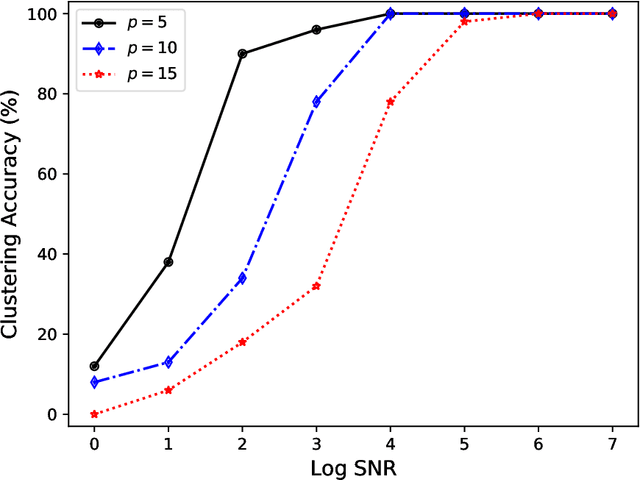
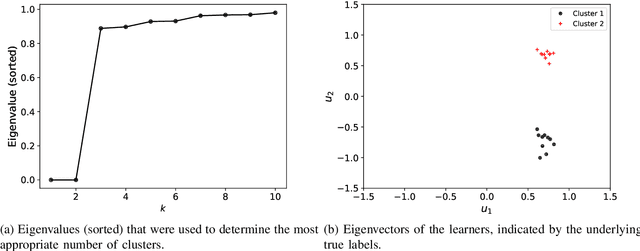
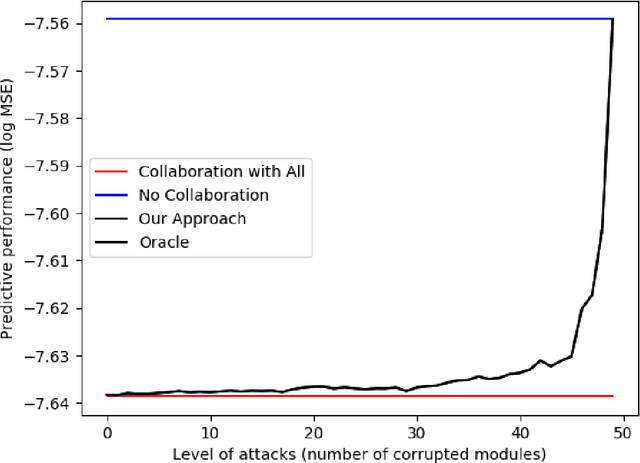
An emerging number of learning scenarios involve a set of learners/analysts each equipped with a unique dataset and algorithm, who may collaborate with each other to enhance their learning performance. From the perspective of a particular learner, a careless collaboration with task-irrelevant other learners is likely to incur modeling error. A crucial problem is to search for the most appropriate collaborators so that their data and modeling resources can be effectively leveraged. Motivated by this, we propose to study the problem of `meta clustering', where the goal is to identify subsets of relevant learners whose collaboration will improve the performance of each individual learner. In particular, we study the scenario where each learner is performing a supervised regression, and the meta clustering aims to categorize the underlying supervised relations (between responses and predictors) instead of the raw data. We propose a general method named as Select-Exchange-Cluster (SEC) for performing such a clustering. Our method is computationally efficient as it does not require each learner to exchange their raw data. We prove that the SEC method can accurately cluster the learners into appropriate collaboration sets according to their underlying regression functions. Synthetic and real data examples show the desired performance and wide applicability of SEC to a variety of learning tasks.