 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Information Processing in Large Language Models: Insights from Information Bottleneck Theory
Jan 06, 2025



Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of tasks by understanding input information and predicting corresponding outputs. However, the internal mechanisms by which LLMs comprehend input and make effective predictions remain poorly understood. In this paper, we explore the working mechanism of LLMs in information processing from the perspective of Information Bottleneck Theory. We propose a non-training construction strategy to define a task space and identify the following key findings: (1) LLMs compress input information into specific task spaces (e.g., sentiment space, topic space) to facilitate task understanding; (2) they then extract and utilize relevant information from the task space at critical moments to generate accurate predictions. Based on these insights, we introduce two novel approaches: an Information Compression-based Context Learning (IC-ICL) and a Task-Space-guided Fine-Tuning (TS-FT). IC-ICL enhances reasoning performance and inference efficiency by compressing retrieved example information into the task space. TS-FT employs a space-guided loss to fine-tune LLMs, encouraging the learning of more effective compression and selection mechanisms. Experiments across multiple datasets validate the effectiveness of task space construction. Additionally, IC-ICL not only improves performance but also accelerates inference speed by over 40\%, while TS-FT achieves superior results with a minimal strategy adjustment.
E-ICL: Enhancing Fine-Grained Emotion Recognition through the Lens of Prototype Theory
Jun 04, 2024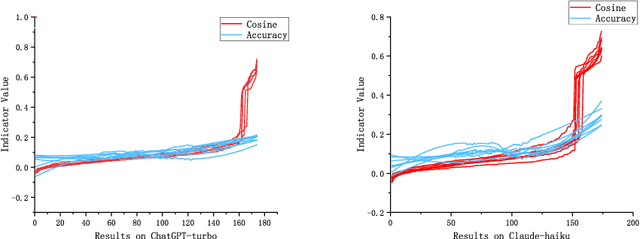
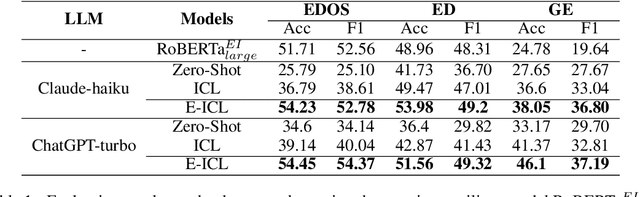
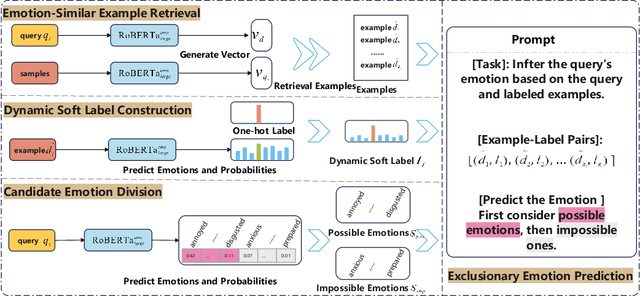
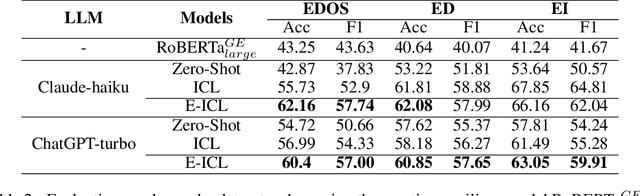
In-context learning (ICL) achieves remarkable performance in various domains such as knowledge acquisition, commonsense reasoning, and semantic understanding. However, its performance significantly deteriorates for emotion detection tasks, especially fine-grained emotion recognition. The underlying reasons for this remain unclear. In this paper, we identify the reasons behind ICL's poor performance from the perspective of prototype theory and propose a method to address this issue. Specifically, we conduct extensive pilot experiments and find that ICL conforms to the prototype theory on fine-grained emotion recognition. Based on this theory, we uncover the following deficiencies in ICL: (1) It relies on prototypes (example-label pairs) that are semantically similar but emotionally inaccurate to predict emotions. (2) It is prone to interference from irrelevant categories, affecting the accuracy and robustness of the predictions. To address these issues, we propose an Emotion Context Learning method (E-ICL) on fine-grained emotion recognition. E-ICL relies on more emotionally accurate prototypes to predict categories by referring to emotionally similar examples with dynamic labels. Simultaneously, E-ICL employs an exclusionary emotion prediction strategy to avoid interference from irrelevant categories, thereby increasing its accuracy and robustness. Note that the entire process is accomplished with the assistance of a plug-and-play emotion auxiliary model, without additional training. Experiments on the fine-grained emotion datasets EDOS, Empathetic-Dialogues, EmpatheticIntent, and GoEmotions show that E-ICL achieves superior emotion prediction performance. Furthermore, even when the emotion auxiliary model used is lower than 10% of the LLMs, E-ICL can still boost the performance of LLMs by over 4% on multiple datasets.
An Iterative Associative Memory Model for Empathetic Response Generation
Feb 28, 2024
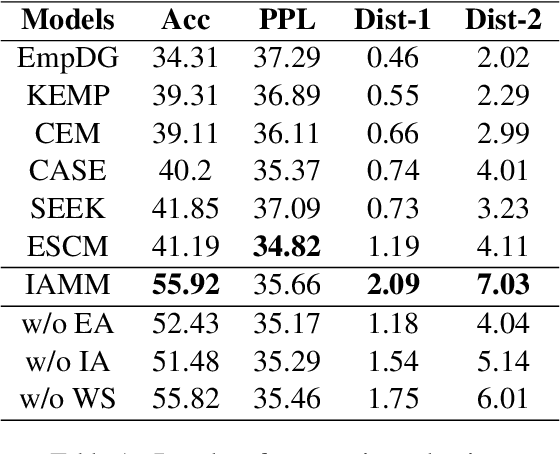
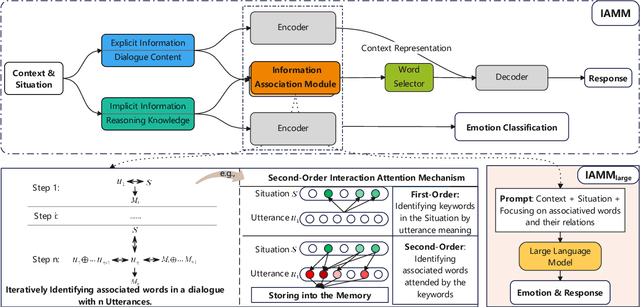
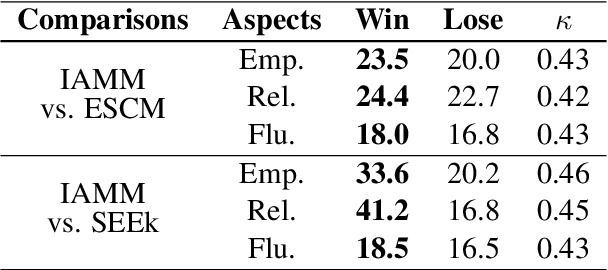
Empathetic response generation is to comprehend the cognitive and emotional states in dialogue utterances and generate proper responses. Psychological theories posit that comprehending emotional and cognitive states necessitates iteratively capturing and understanding associated words across dialogue utterances. However, existing approaches regard dialogue utterances as either a long sequence or independent utterances for comprehension, which are prone to overlook the associated words between them. To address this issue, we propose an Iterative Associative Memory Model (IAMM) for empathetic response generation. Specifically, we employ a novel second-order interaction attention mechanism to iteratively capture vital associated words between dialogue utterances and situations, dialogue history, and a memory module (for storing associated words), thereby accurately and nuancedly comprehending the utterances. We conduct experiments on the Empathetic-Dialogue dataset. Both automatic and human evaluations validate the efficacy of the model. Meanwhile, variant experiments on LLMs also demonstrate that attending to associated words improves empathetic comprehension and expression.