 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAEGIS: From Clues to Verdicts -- Graph-Guided Deep Vulnerability Reasoning via Dialectics and Meta-Auditing
Mar 21, 2026Large Language Models (LLMs) are increasingly adopted for vulnerability detection, yet their reasoning remains fundamentally unsound. We identify a root cause shared by both major mitigation paradigms (agent-based debate and retrieval augmentation): reasoning in an ungrounded deliberative space that lacks a bounded, hypothesis-specific evidence base. Without such grounding, agents fabricate cross-function dependencies, and retrieval heuristics supply generic knowledge decoupled from the repository's data-flow topology. Consequently, the resulting conclusions are driven by rhetorical persuasiveness rather than verifiable facts. To ground this deliberation, we present AEGIS, a novel multi-agent framework that shifts detection from ungrounded speculation to forensic verification over a closed factual substrate. Guided by a "From Clue to Verdict" philosophy, AEGIS first identifies suspicious code anomalies (clues), then dynamically reconstructs per-variable dependency chains for each clue via on-demand slicing over a repository-level Code Property Graph. Within this closed evidence boundary, a Verifier Agent constructs competing dialectical arguments for and against exploitability, while an independent Audit Agent scrutinizes every claim against the trace, exercising veto power to prevent hallucinated verdicts. Evaluation on the rigorous PrimeVul dataset demonstrates that AEGIS establishes a new state-of-the-art, achieving 122 Pair-wise Correct Predictions. To our knowledge, this is the first approach to surpass 100 on this benchmark. It reduces the false positive rate by up to 54.40% compared to leading baselines, at an average cost of $0.09 per sample without any task-specific training.
Iterative Semantic Reasoning from Individual to Group Interests for Generative Recommendation with LLMs
Mar 14, 2026Recommendation systems aim to learn user interests from historical behaviors and deliver relevant items. Recent methods leverage large language models (LLMs) to construct and integrate semantic representations of users and items for capturing user interests. However, user behavior theories suggest that truly understanding user interests requires not only semantic integration but also semantic reasoning from explicit individual interests to implicit group interests. To this end, we propose an Iterative Semantic Reasoning Framework (ISRF) for generative recommendation. ISRF leverages LLMs to bridge explicit individual interests and implicit group interests in three steps. First, we perform multi-step bidirectional reasoning over item attributes to infer semantic item features and build a semantic interaction graph capturing users' explicit interests. Second, we generate semantic user features based on the semantic item features and construct a similarity-based user graph to infer the implicit interests of similar user groups. Third, we adopt an iterative batch optimization strategy, where individual explicit interests directly guide the refinement of group implicit interests, while group implicit interests indirectly enhance individual modeling. This iterative process ensures consistent and progressive interest reasoning, enabling more accurate and comprehensive user interest learning. Extensive experiments on the Sports, Beauty, and Toys datasets demonstrate that ISRF outperforms state-of-the-art baselines. The code is available at https://github.com/htired/ISRF.
Revis: Sparse Latent Steering to Mitigate Object Hallucination in Large Vision-Language Models
Feb 12, 2026Despite the advanced capabilities of Large Vision-Language Models (LVLMs), they frequently suffer from object hallucination. One reason is that visual features and pretrained textual representations often become intertwined in the deeper network layers. To address this, we propose REVIS, a training-free framework designed to explicitly re-activate this suppressed visual information. Rooted in latent space geometry, REVIS extracts the pure visual information vector via orthogonal projection and employs a calibrated strategy to perform sparse intervention only at the precise depth where suppression occurs. This surgical approach effectively restores visual information with minimal computational cost. Empirical evaluations on standard benchmarks demonstrate that REVIS reduces object hallucination rates by approximately 19% compared to state-of-the-art baselines, while preserving general reasoning capabilities.
Light Alignment Improves LLM Safety via Model Self-Reflection with a Single Neuron
Feb 02, 2026The safety of large language models (LLMs) has increasingly emerged as a fundamental aspect of their development. Existing safety alignment for LLMs is predominantly achieved through post-training methods, which are computationally expensive and often fail to generalize well across different models. A small number of lightweight alignment approaches either rely heavily on prior-computed safety injections or depend excessively on the model's own capabilities, resulting in limited generalization and degraded efficiency and usability during generation. In this work, we propose a safety-aware decoding method that requires only low-cost training of an expert model and employs a single neuron as a gating mechanism. By effectively balancing the model's intrinsic capabilities with external guidance, our approach simultaneously preserves utility and enhances output safety. It demonstrates clear advantages in training overhead and generalization across model scales, offering a new perspective on lightweight alignment for the safe and practical deployment of large language models. Code: https://github.com/Beijing-AISI/NGSD.
Discovering Transmission Dynamics of COVID-19 in China
Dec 28, 2025A comprehensive retrospective analysis of public health interventions, such as large scale testing, quarantining, and contact tracing, can help identify mechanisms most effective in mitigating COVID-19. We investigate China based SARS-CoV-2 transmission patterns (e.g., infection type and likely transmission source) using publicly released tracking data. We collect case reports from local health commissions, the Chinese CDC, and official local government social media, then apply NLP and manual curation to construct transmission/tracking chains. We further analyze tracking data together with Wuhan population mobility data to quantify and visualize temporal and spatial spread dynamics. Results indicate substantial regional differences, with larger cities showing more infections, likely driven by social activities. Most symptomatic individuals (79\%) were hospitalized within 5 days of symptom onset, and those with confirmed-case contact sought admission in under 5 days. Infection sources also shifted over time: early cases were largely linked to travel to (or contact with travelers from) Hubei Province, while later transmission was increasingly associated with social activities.
"My productivity is boosted, but ..." Demystifying Users' Perception on AI Coding Assistants
Aug 17, 2025This paper aims to explore fundamental questions in the era when AI coding assistants like GitHub Copilot are widely adopted: what do developers truly value and criticize in AI coding assistants, and what does this reveal about their needs and expectations in real-world software development? Unlike previous studies that conduct observational research in controlled and simulated environments, we analyze extensive, first-hand user reviews of AI coding assistants, which capture developers' authentic perspectives and experiences drawn directly from their actual day-to-day work contexts. We identify 1,085 AI coding assistants from the Visual Studio Code Marketplace. Although they only account for 1.64% of all extensions, we observe a surge in these assistants: over 90% of them are released within the past two years. We then manually analyze the user reviews sampled from 32 AI coding assistants that have sufficient installations and reviews to construct a comprehensive taxonomy of user concerns and feedback about these assistants. We manually annotate each review's attitude when mentioning certain aspects of coding assistants, yielding nuanced insights into user satisfaction and dissatisfaction regarding specific features, concerns, and overall tool performance. Built on top of the findings-including how users demand not just intelligent suggestions but also context-aware, customizable, and resource-efficient interactions-we propose five practical implications and suggestions to guide the enhancement of AI coding assistants that satisfy user needs.
A Split-Window Transformer for Multi-Model Sequence Spammer Detection using Multi-Model Variational Autoencoder
Feb 23, 2025



This paper introduces a new Transformer, called MS$^2$Dformer, that can be used as a generalized backbone for multi-modal sequence spammer detection. Spammer detection is a complex multi-modal task, thus the challenges of applying Transformer are two-fold. Firstly, complex multi-modal noisy information about users can interfere with feature mining. Secondly, the long sequence of users' historical behaviors also puts a huge GPU memory pressure on the attention computation. To solve these problems, we first design a user behavior Tokenization algorithm based on the multi-modal variational autoencoder (MVAE). Subsequently, a hierarchical split-window multi-head attention (SW/W-MHA) mechanism is proposed. The split-window strategy transforms the ultra-long sequences hierarchically into a combination of intra-window short-term and inter-window overall attention. Pre-trained on the public datasets, MS$^2$Dformer's performance far exceeds the previous state of the art. The experiments demonstrate MS$^2$Dformer's ability to act as a backbone.
Do Existing Testing Tools Really Uncover Gender Bias in Text-to-Image Models?
Jan 27, 2025



Text-to-Image (T2I) models have recently gained significant attention due to their ability to generate high-quality images and are consequently used in a wide range of applications. However, there are concerns about the gender bias of these models. Previous studies have shown that T2I models can perpetuate or even amplify gender stereotypes when provided with neutral text prompts. Researchers have proposed automated gender bias uncovering detectors for T2I models, but a crucial gap exists: no existing work comprehensively compares the various detectors and understands how the gender bias detected by them deviates from the actual situation. This study addresses this gap by validating previous gender bias detectors using a manually labeled dataset and comparing how the bias identified by various detectors deviates from the actual bias in T2I models, as verified by manual confirmation. We create a dataset consisting of 6,000 images generated from three cutting-edge T2I models: Stable Diffusion XL, Stable Diffusion 3, and Dreamlike Photoreal 2.0. During the human-labeling process, we find that all three T2I models generate a portion (12.48% on average) of low-quality images (e.g., generate images with no face present), where human annotators cannot determine the gender of the person. Our analysis reveals that all three T2I models show a preference for generating male images, with SDXL being the most biased. Additionally, images generated using prompts containing professional descriptions (e.g., lawyer or doctor) show the most bias. We evaluate seven gender bias detectors and find that none fully capture the actual level of bias in T2I models, with some detectors overestimating bias by up to 26.95%. We further investigate the causes of inaccurate estimations, highlighting the limitations of detectors in dealing with low-quality images. Based on our findings, we propose an enhanced detector...
Exploring Information Processing in Large Language Models: Insights from Information Bottleneck Theory
Jan 06, 2025



Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of tasks by understanding input information and predicting corresponding outputs. However, the internal mechanisms by which LLMs comprehend input and make effective predictions remain poorly understood. In this paper, we explore the working mechanism of LLMs in information processing from the perspective of Information Bottleneck Theory. We propose a non-training construction strategy to define a task space and identify the following key findings: (1) LLMs compress input information into specific task spaces (e.g., sentiment space, topic space) to facilitate task understanding; (2) they then extract and utilize relevant information from the task space at critical moments to generate accurate predictions. Based on these insights, we introduce two novel approaches: an Information Compression-based Context Learning (IC-ICL) and a Task-Space-guided Fine-Tuning (TS-FT). IC-ICL enhances reasoning performance and inference efficiency by compressing retrieved example information into the task space. TS-FT employs a space-guided loss to fine-tune LLMs, encouraging the learning of more effective compression and selection mechanisms. Experiments across multiple datasets validate the effectiveness of task space construction. Additionally, IC-ICL not only improves performance but also accelerates inference speed by over 40\%, while TS-FT achieves superior results with a minimal strategy adjustment.
Bias in Large Language Models: Origin, Evaluation, and Mitigation
Nov 16, 2024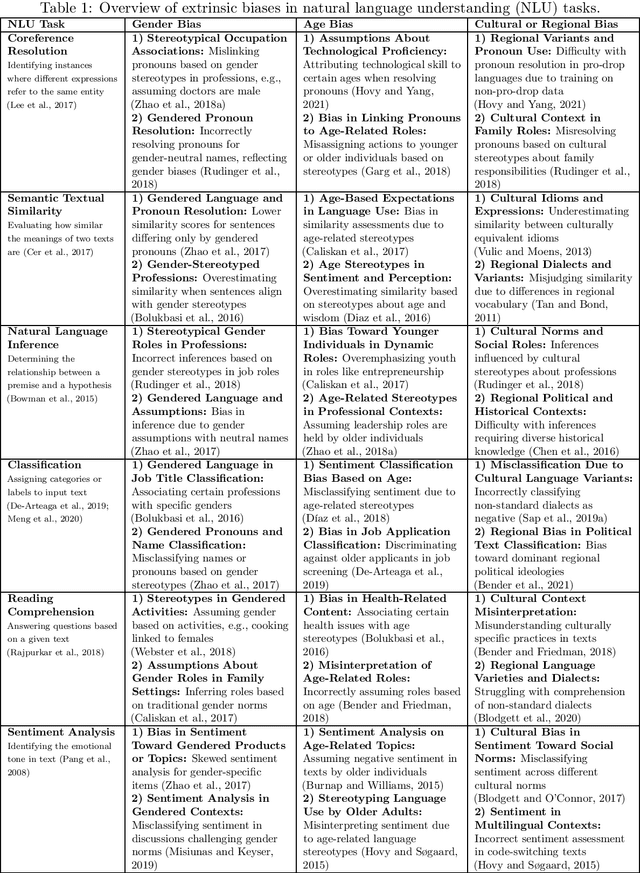
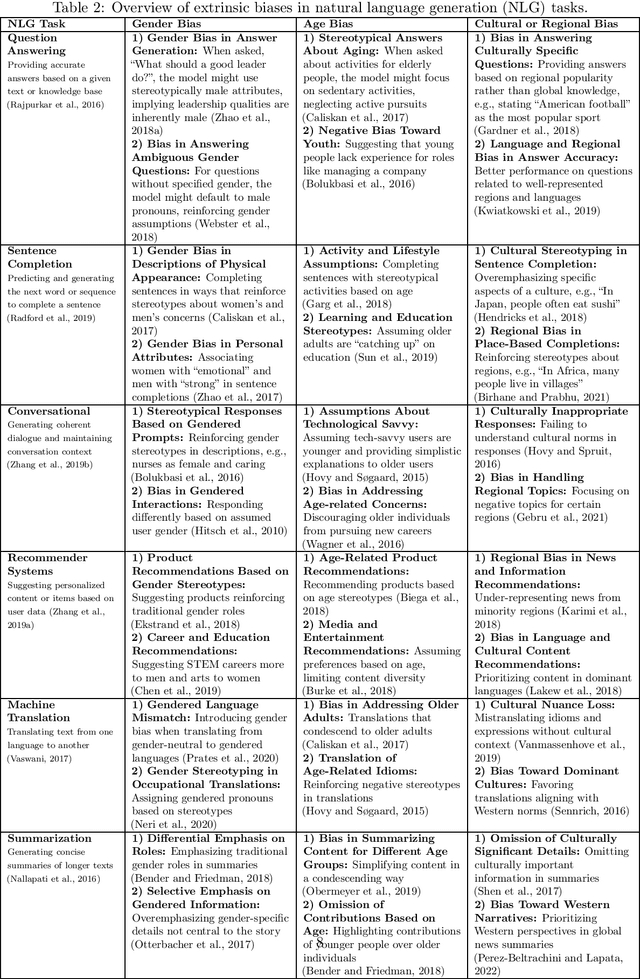
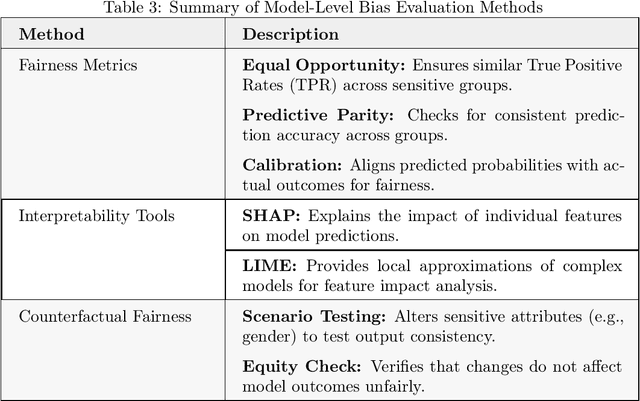

Large Language Models (LLMs) have revolutionized natural language processing, but their susceptibility to biases poses significant challenges. This comprehensive review examines the landscape of bias in LLMs, from its origins to current mitigation strategies. We categorize biases as intrinsic and extrinsic, analyzing their manifestations in various NLP tasks. The review critically assesses a range of bias evaluation methods, including data-level, model-level, and output-level approaches, providing researchers with a robust toolkit for bias detection. We further explore mitigation strategies, categorizing them into pre-model, intra-model, and post-model techniques, highlighting their effectiveness and limitations. Ethical and legal implications of biased LLMs are discussed, emphasizing potential harms in real-world applications such as healthcare and criminal justice. By synthesizing current knowledge on bias in LLMs, this review contributes to the ongoing effort to develop fair and responsible AI systems. Our work serves as a comprehensive resource for researchers and practitioners working towards understanding, evaluating, and mitigating bias in LLMs, fostering the development of more equitable AI technologies.