 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Many and Adapting to the Unknown in Open-set Test Streams
Apr 01, 2026Large Language Models (LLMs) generalize across tasks via reusable representations and flexible reasoning, yet remain brittle in real deployment under evolving tasks and continual distribution shift. A common approach is Test-Time Adaptation (TTA), existing ones of which updates models with hand-designed unsupervised objectives over the full parameter space and mostly overlook preserving shared source knowledge and the reliability of adaptation signals. Drawing on molecular signaling cascades of memory updating in Drosophila, we propose Synapse Consolidation (SyCo), a parameter-efficient LLM adaptation method that updates low-rank adapters through Rac1 and MAPK pathways under the guidance of a structured TTA objective driven by problem understanding, process understanding, and source-domain guardrail. Rac1 confines plasticity to a tail-gradient subspace that is less critical for source knowledge, enabling rapid specialization while preserving source representations. MAPK uses a tiered controller to suppress noisy updates and consolidate useful adaptations under non-stationary streams. To model real deployments with multiple sources and continually emerging tasks, we introduce Multi-source Open-set Adaptation (MOA) setting, where a model is trained on multiple labeled source tasks and then adapts on open, non-stationary unlabeled test streams that mix seen and unseen tasks with partial overlap in label and intent space. Across 18 NLP datasets and the MOA setting, SyCo consistently outperforms strong baselines, achieving 78.31\% on unseen-task adaptation and 85.37\% on unseen-data shifts.
Experimental study on surveillance video-based indoor occupancy measurement with occupant-centric control
Mar 27, 2026Accurate occupancy information is essential for closed-loop occupant-centric control (OCC) in smart buildings. However, existing vision-based occupancy measurement methods often struggle to provide stable and accurate measurements in real indoor environments, and their implications for downstream HVAC control remain insufficiently studied. To achieve Net Zero emissions by 2050, this paper presents an experimental study of large language models (LLMs)-enhanced vision-based indoor occupancy measurement and its impact on OCC-enabled HVAC operation. Detection-only, tracking-based, and LLM-based refinement pipelines are compared under identical conditions using real surveillance data collected from a research laboratory in China, with frame-level manual ground-truth annotations. Results show that tracking-based methods improve temporal stability over detection-only measurement, while LLM-based refinement further improves occupancy measurement performance and reduces false unoccupied prediction. The best-performing pipeline, YOLOv8+DeepSeek, achieves an accuracy of 0.8824 and an F1-score of 0.9320. This pipeline is then integrated into an HVAC supervisory model predictive control framework in OpenStudio-EnergyPlus. Experimental results demonstrate that the proposed framework can support more efficient OCC operation, achieving a substantial HVAC energy-saving potential of 17.94%. These findings provide an effective methodology and practical foundation for future research in AI-enhanced smart building operations.
GlobeDiff: State Diffusion Process for Partial Observability in Multi-Agent Systems
Feb 17, 2026In the realm of multi-agent systems, the challenge of \emph{partial observability} is a critical barrier to effective coordination and decision-making. Existing approaches, such as belief state estimation and inter-agent communication, often fall short. Belief-based methods are limited by their focus on past experiences without fully leveraging global information, while communication methods often lack a robust model to effectively utilize the auxiliary information they provide. To solve this issue, we propose Global State Diffusion Algorithm~(GlobeDiff) to infer the global state based on the local observations. By formulating the state inference process as a multi-modal diffusion process, GlobeDiff overcomes ambiguities in state estimation while simultaneously inferring the global state with high fidelity. We prove that the estimation error of GlobeDiff under both unimodal and multi-modal distributions can be bounded. Extensive experimental results demonstrate that GlobeDiff achieves superior performance and is capable of accurately inferring the global state.
PAG: Multi-Turn Reinforced LLM Self-Correction with Policy as Generative Verifier
Jun 12, 2025Large Language Models (LLMs) have demonstrated impressive capabilities in complex reasoning tasks, yet they still struggle to reliably verify the correctness of their own outputs. Existing solutions to this verification challenge often depend on separate verifier models or require multi-stage self-correction training pipelines, which limit scalability. In this paper, we propose Policy as Generative Verifier (PAG), a simple and effective framework that empowers LLMs to self-correct by alternating between policy and verifier roles within a unified multi-turn reinforcement learning (RL) paradigm. Distinct from prior approaches that always generate a second attempt regardless of model confidence, PAG introduces a selective revision mechanism: the model revises its answer only when its own generative verification step detects an error. This verify-then-revise workflow not only alleviates model collapse but also jointly enhances both reasoning and verification abilities. Extensive experiments across diverse reasoning benchmarks highlight PAG's dual advancements: as a policy, it enhances direct generation and self-correction accuracy; as a verifier, its self-verification outperforms self-consistency.
Fewer May Be Better: Enhancing Offline Reinforcement Learning with Reduced Dataset
Feb 26, 2025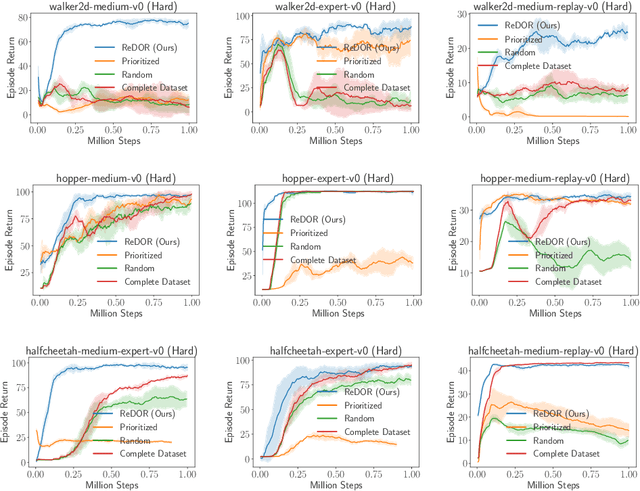
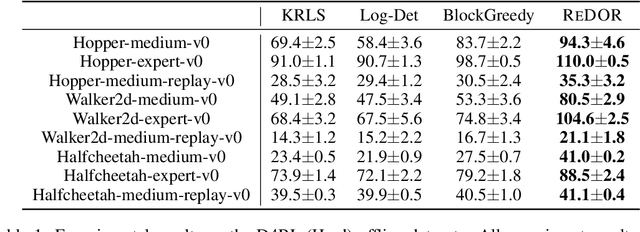

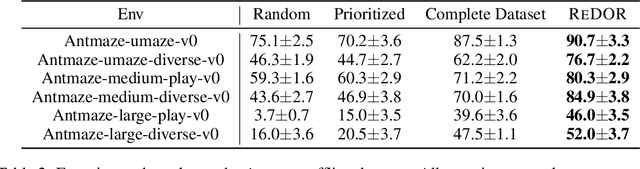
Offline reinforcement learning (RL) represents a significant shift in RL research, allowing agents to learn from pre-collected datasets without further interaction with the environment. A key, yet underexplored, challenge in offline RL is selecting an optimal subset of the offline dataset that enhances both algorithm performance and training efficiency. Reducing dataset size can also reveal the minimal data requirements necessary for solving similar problems. In response to this challenge, we introduce ReDOR (Reduced Datasets for Offline RL), a method that frames dataset selection as a gradient approximation optimization problem. We demonstrate that the widely used actor-critic framework in RL can be reformulated as a submodular optimization objective, enabling efficient subset selection. To achieve this, we adapt orthogonal matching pursuit (OMP), incorporating several novel modifications tailored for offline RL. Our experimental results show that the data subsets identified by ReDOR not only boost algorithm performance but also do so with significantly lower computational complexity.
Episodic Novelty Through Temporal Distance
Jan 26, 2025Exploration in sparse reward environments remains a significant challenge in reinforcement learning, particularly in Contextual Markov Decision Processes (CMDPs), where environments differ across episodes. Existing episodic intrinsic motivation methods for CMDPs primarily rely on count-based approaches, which are ineffective in large state spaces, or on similarity-based methods that lack appropriate metrics for state comparison. To address these shortcomings, we propose Episodic Novelty Through Temporal Distance (ETD), a novel approach that introduces temporal distance as a robust metric for state similarity and intrinsic reward computation. By employing contrastive learning, ETD accurately estimates temporal distances and derives intrinsic rewards based on the novelty of states within the current episode. Extensive experiments on various benchmark tasks demonstrate that ETD significantly outperforms state-of-the-art methods, highlighting its effectiveness in enhancing exploration in sparse reward CMDPs.
Toward Pedestrian Head Tracking: A Benchmark Dataset and an Information Fusion Network
Aug 12, 2024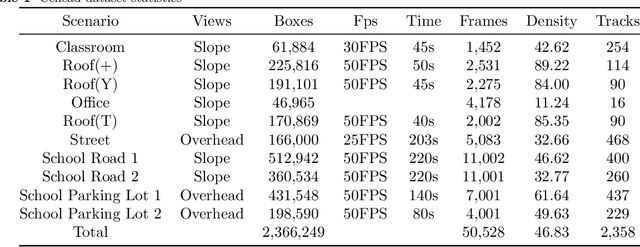


Pedestrian detection and tracking in crowded video sequences have a wide range of applications, including autonomous driving, robot navigation and pedestrian flow surveillance. However, detecting and tracking pedestrians in high-density crowds face many challenges, including intra-class occlusions, complex motions, and diverse poses. Although deep learning models have achieved remarkable progress in head detection, head tracking datasets and methods are extremely lacking. Existing head datasets have limited coverage of complex pedestrian flows and scenes (e.g., pedestrian interactions, occlusions, and object interference). It is of great importance to develop new head tracking datasets and methods. To address these challenges, we present a Chinese Large-scale Cross-scene Pedestrian Head Tracking dataset (Cchead) and a Multi-Source Information Fusion Network (MIFN). Our dataset has features that are of considerable interest, including 10 diverse scenes of 50,528 frames with over 2,366,249 heads and 2,358 tracks annotated. Our dataset contains diverse human moving speeds, directions, and complex crowd pedestrian flows with collision avoidance behaviors. We provide a comprehensive analysis and comparison with existing state-of-the-art (SOTA) algorithms. Moreover, our MIFN is the first end-to-end CNN-based head detection and tracking network that jointly trains RGB frames, pixel-level motion information (optical flow and frame difference maps), depth maps, and density maps in videos. Compared with SOTA pedestrian detection and tracking methods, MIFN achieves superior performance on our Cchead dataset. We believe our datasets and baseline will become valuable resources towards developing pedestrian tracking in dense crowds.
A Two-Stage Masked Autoencoder Based Network for Indoor Depth Completion
Jun 14, 2024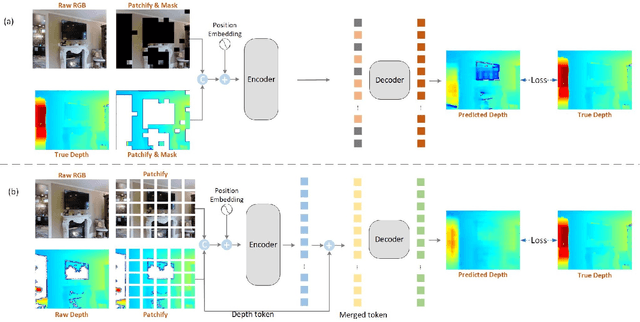
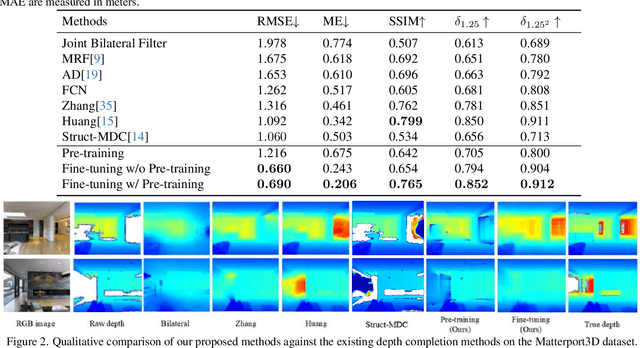
Depth images have a wide range of applications, such as 3D reconstruction, autonomous driving, augmented reality, robot navigation, and scene understanding. Commodity-grade depth cameras are hard to sense depth for bright, glossy, transparent, and distant surfaces. Although existing depth completion methods have achieved remarkable progress, their performance is limited when applied to complex indoor scenarios. To address these problems, we propose a two-step Transformer-based network for indoor depth completion. Unlike existing depth completion approaches, we adopt a self-supervision pre-training encoder based on the masked autoencoder to learn an effective latent representation for the missing depth value; then we propose a decoder based on a token fusion mechanism to complete (i.e., reconstruct) the full depth from the jointly RGB and incomplete depth image. Compared to the existing methods, our proposed network, achieves the state-of-the-art performance on the Matterport3D dataset. In addition, to validate the importance of the depth completion task, we apply our methods to indoor 3D reconstruction. The code, dataset, and demo are available at https://github.com/kailaisun/Indoor-Depth-Completion.
Bayesian Design Principles for Offline-to-Online Reinforcement Learning
May 31, 2024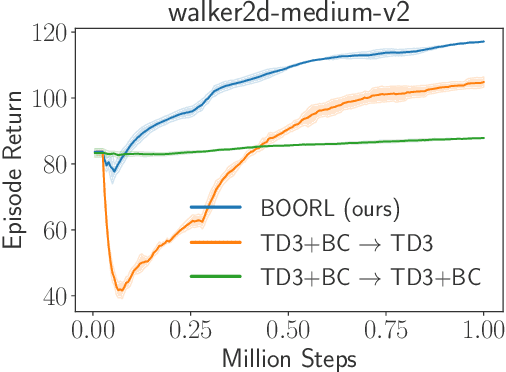

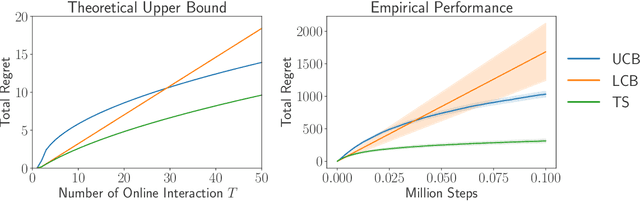

Offline reinforcement learning (RL) is crucial for real-world applications where exploration can be costly or unsafe. However, offline learned policies are often suboptimal, and further online fine-tuning is required. In this paper, we tackle the fundamental dilemma of offline-to-online fine-tuning: if the agent remains pessimistic, it may fail to learn a better policy, while if it becomes optimistic directly, performance may suffer from a sudden drop. We show that Bayesian design principles are crucial in solving such a dilemma. Instead of adopting optimistic or pessimistic policies, the agent should act in a way that matches its belief in optimal policies. Such a probability-matching agent can avoid a sudden performance drop while still being guaranteed to find the optimal policy. Based on our theoretical findings, we introduce a novel algorithm that outperforms existing methods on various benchmarks, demonstrating the efficacy of our approach. Overall, the proposed approach provides a new perspective on offline-to-online RL that has the potential to enable more effective learning from offline data.
No Prior Mask: Eliminate Redundant Action for Deep Reinforcement Learning
Dec 11, 2023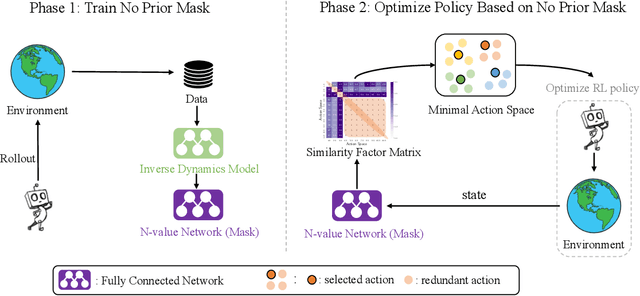
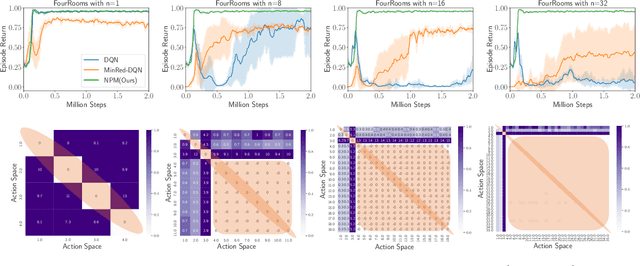
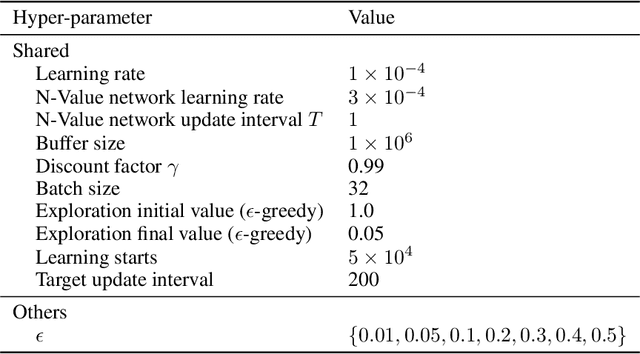
The large action space is one fundamental obstacle to deploying Reinforcement Learning methods in the real world. The numerous redundant actions will cause the agents to make repeated or invalid attempts, even leading to task failure. Although current algorithms conduct some initial explorations for this issue, they either suffer from rule-based systems or depend on expert demonstrations, which significantly limits their applicability in many real-world settings. In this work, we examine the theoretical analysis of what action can be eliminated in policy optimization and propose a novel redundant action filtering mechanism. Unlike other works, our method constructs the similarity factor by estimating the distance between the state distributions, which requires no prior knowledge. In addition, we combine the modified inverse model to avoid extensive computation in high-dimensional state space. We reveal the underlying structure of action spaces and propose a simple yet efficient redundant action filtering mechanism named No Prior Mask (NPM) based on the above techniques. We show the superior performance of our method by conducting extensive experiments on high-dimensional, pixel-input, and stochastic problems with various action redundancy. Our code is public online at https://github.com/zhongdy15/npm.