 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHCDN: A Change Detection Network for Construction Housekeeping Using Feature Fusion and Large Vision Models
Oct 23, 2024Workplace safety has received increasing attention as millions of workers worldwide suffer from work-related accidents. Despite poor housekeeping is a significant contributor to construction accidents, there remains a significant lack of technological research focused on improving housekeeping practices in construction sites. Recognizing and locating poor housekeeping in a dynamic construction site is an important task that can be improved through computer vision approaches. Despite advances in AI and computer vision, existing methods for detecting poor housekeeping conditions face many challenges, including limited explanations, lack of locating of poor housekeeping, and lack of annotated datasets. On the other hand, change detection which aims to detect the changed environmental conditions (e.g., changing from good to poor housekeeping) and 'where' the change has occurred (e.g., location of objects causing poor housekeeping), has not been explored to the problem of housekeeping management. To address these challenges, we propose the Housekeeping Change Detection Network (HCDN), an advanced change detection neural network that integrates a feature fusion module and a large vision model, achieving state-of-the-art performance. Additionally, we introduce the approach to establish a novel change detection dataset (named Housekeeping-CCD) focused on housekeeping in construction sites, along with a housekeeping segmentation dataset. Our contributions include significant performance improvements compared to existing methods, providing an effective tool for enhancing construction housekeeping and safety. To promote further development, we share our source code and trained models for global researchers: https://github.com/NUS-DBE/Housekeeping-CD.
Overcoming Imbalanced Safety Data Using Extended Accident Triangle
Aug 12, 2024There is growing interest in using safety analytics and machine learning to support the prevention of workplace incidents, especially in high-risk industries like construction and trucking. Although existing safety analytics studies have made remarkable progress, they suffer from imbalanced datasets, a common problem in safety analytics, resulting in prediction inaccuracies. This can lead to management problems, e.g., incorrect resource allocation and improper interventions. To overcome the imbalanced data problem, we extend the theory of accident triangle to claim that the importance of data samples should be based on characteristics such as injury severity, accident frequency, and accident type. Thus, three oversampling methods are proposed based on assigning different weights to samples in the minority class. We find robust improvements among different machine learning algorithms. For the lack of open-source safety datasets, we are sharing three imbalanced datasets, e.g., a 9-year nationwide construction accident record dataset, and their corresponding codes.
Toward Pedestrian Head Tracking: A Benchmark Dataset and an Information Fusion Network
Aug 12, 2024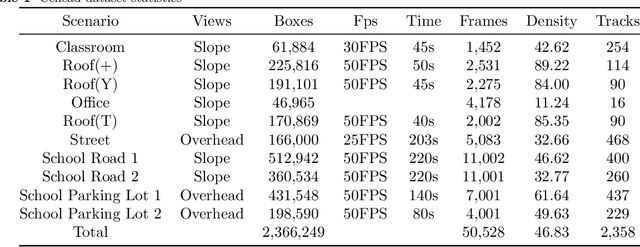


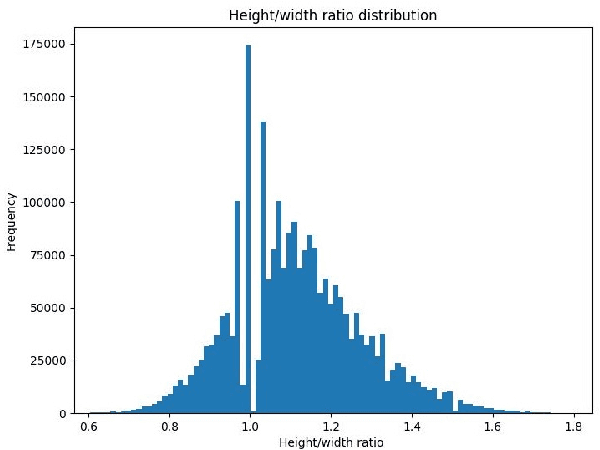
Pedestrian detection and tracking in crowded video sequences have a wide range of applications, including autonomous driving, robot navigation and pedestrian flow surveillance. However, detecting and tracking pedestrians in high-density crowds face many challenges, including intra-class occlusions, complex motions, and diverse poses. Although deep learning models have achieved remarkable progress in head detection, head tracking datasets and methods are extremely lacking. Existing head datasets have limited coverage of complex pedestrian flows and scenes (e.g., pedestrian interactions, occlusions, and object interference). It is of great importance to develop new head tracking datasets and methods. To address these challenges, we present a Chinese Large-scale Cross-scene Pedestrian Head Tracking dataset (Cchead) and a Multi-Source Information Fusion Network (MIFN). Our dataset has features that are of considerable interest, including 10 diverse scenes of 50,528 frames with over 2,366,249 heads and 2,358 tracks annotated. Our dataset contains diverse human moving speeds, directions, and complex crowd pedestrian flows with collision avoidance behaviors. We provide a comprehensive analysis and comparison with existing state-of-the-art (SOTA) algorithms. Moreover, our MIFN is the first end-to-end CNN-based head detection and tracking network that jointly trains RGB frames, pixel-level motion information (optical flow and frame difference maps), depth maps, and density maps in videos. Compared with SOTA pedestrian detection and tracking methods, MIFN achieves superior performance on our Cchead dataset. We believe our datasets and baseline will become valuable resources towards developing pedestrian tracking in dense crowds.
A Two-Stage Masked Autoencoder Based Network for Indoor Depth Completion
Jun 14, 2024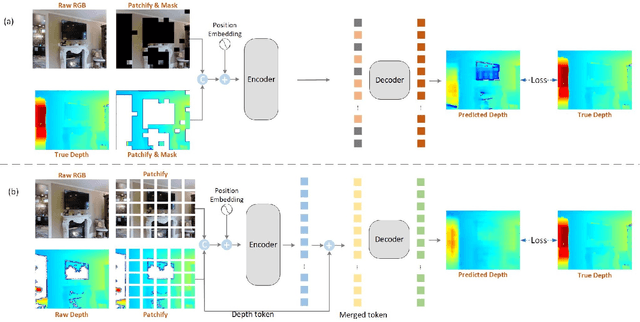
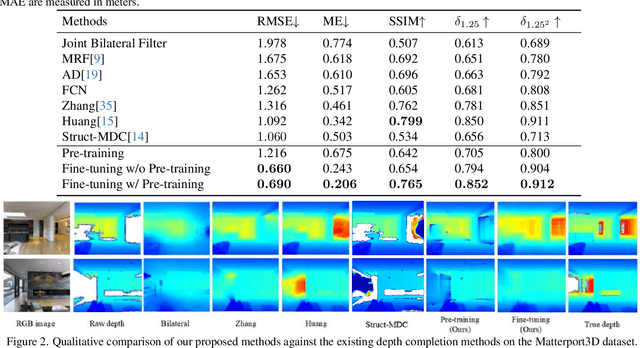
Depth images have a wide range of applications, such as 3D reconstruction, autonomous driving, augmented reality, robot navigation, and scene understanding. Commodity-grade depth cameras are hard to sense depth for bright, glossy, transparent, and distant surfaces. Although existing depth completion methods have achieved remarkable progress, their performance is limited when applied to complex indoor scenarios. To address these problems, we propose a two-step Transformer-based network for indoor depth completion. Unlike existing depth completion approaches, we adopt a self-supervision pre-training encoder based on the masked autoencoder to learn an effective latent representation for the missing depth value; then we propose a decoder based on a token fusion mechanism to complete (i.e., reconstruct) the full depth from the jointly RGB and incomplete depth image. Compared to the existing methods, our proposed network, achieves the state-of-the-art performance on the Matterport3D dataset. In addition, to validate the importance of the depth completion task, we apply our methods to indoor 3D reconstruction. The code, dataset, and demo are available at https://github.com/kailaisun/Indoor-Depth-Completion.
Predicting trucking accidents with truck drivers 'safety climate perception across companies: A transfer learning approach
Feb 19, 2024
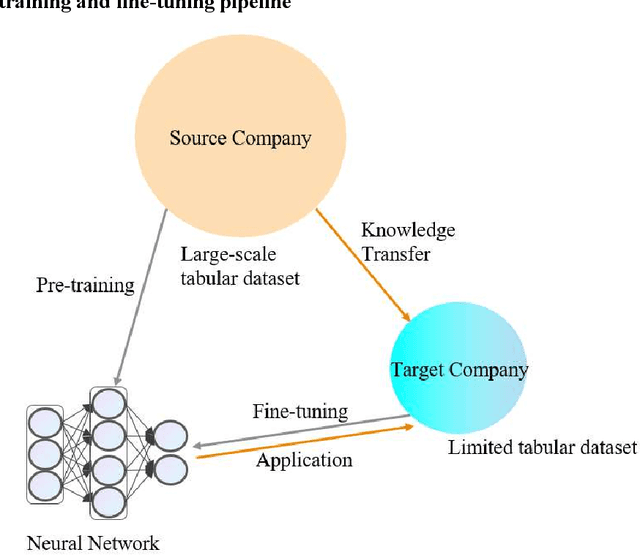


There is a rising interest in using artificial intelligence (AI)-powered safety analytics to predict accidents in the trucking industry. Companies may face the practical challenge, however, of not having enough data to develop good safety analytics models. Although pretrained models may offer a solution for such companies, existing safety research using transfer learning has mostly focused on computer vision and natural language processing, rather than accident analytics. To fill the above gap, we propose a pretrain-then-fine-tune transfer learning approach to help any company leverage other companies' data to develop AI models for a more accurate prediction of accident risk. We also develop SafeNet, a deep neural network algorithm for classification tasks suitable for accident prediction. Using the safety climate survey data from seven trucking companies with different data sizes, we show that our proposed approach results in better model performance compared to training the model from scratch using only the target company's data. We also show that for the transfer learning model to be effective, the pretrained model should be developed with larger datasets from diverse sources. The trucking industry may, thus, consider pooling safety analytics data from a wide range of companies to develop pretrained models and share them within the industry for better knowledge and resource transfer. The above contributions point to the promise of advanced safety analytics to make the industry safer and more sustainable.
An interpretable clustering approach to safety climate analysis: examining driver group distinction in safety climate perceptions
Oct 30, 2023



The transportation industry, particularly the trucking sector, is prone to workplace accidents and fatalities. Accidents involving large trucks accounted for a considerable percentage of overall traffic fatalities. Recognizing the crucial role of safety climate in accident prevention, researchers have sought to understand its factors and measure its impact within organizations. While existing data-driven safety climate studies have made remarkable progress, clustering employees based on their safety climate perception is innovative and has not been extensively utilized in research. Identifying clusters of drivers based on their safety climate perception allows the organization to profile its workforce and devise more impactful interventions. The lack of utilizing the clustering approach could be due to difficulties interpreting or explaining the factors influencing employees' cluster membership. Moreover, existing safety-related studies did not compare multiple clustering algorithms, resulting in potential bias. To address these issues, this study introduces an interpretable clustering approach for safety climate analysis. This study compares 5 algorithms for clustering truck drivers based on their safety climate perceptions. It proposes a novel method for quantitatively evaluating partial dependence plots (QPDP). To better interpret the clustering results, this study introduces different interpretable machine learning measures (SHAP, PFI, and QPDP). Drawing on data collected from more than 7,000 American truck drivers, this study significantly contributes to the scientific literature. It highlights the critical role of supervisory care promotion in distinguishing various driver groups. The Python code is available at https://github.com/NUS-DBE/truck-driver-safety-climate.
MGPSN: Motion-Guided Pseudo Siamese Network for Indoor Video Head Detection
Oct 07, 2021



Head detection in real-world videos is an important research topic in computer vision. However, existing studies face some challenges in complex scenes. The performance of head detectors deteriorates when objects which have similar head appearance exist for indoor videos. Moreover, heads have small scales and diverse poses, which increases the difficulty in detection. To handle these issues, we propose Motion-Guided Pseudo Siamese Network for Indoor Video Head Detection (MGPSN), an end-to-end model to learn the robust head motion features. MGPSN integrates spatial-temporal information on pixel level, guiding the model to extract effective head features. Experiments show that MGPSN is able to suppress static objects and enhance motion instances. Compared with previous methods, it achieves state-of-the-art performance on the crowd Brainwash dataset. Different backbone networks and detectors are evaluated to verify the flexibility and generality of MGPSN.
Cross-lingual Dependency Parsing as Domain Adaptation
Dec 24, 2020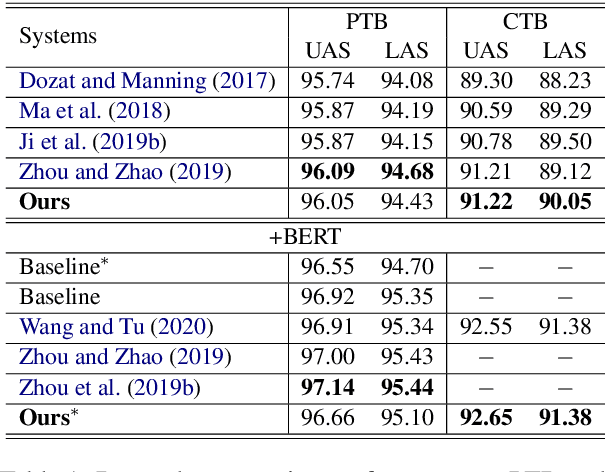
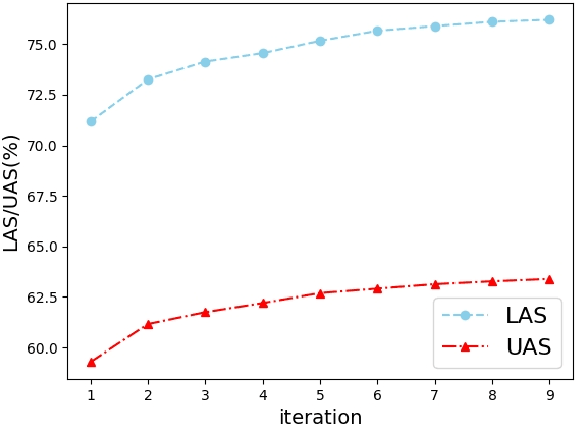
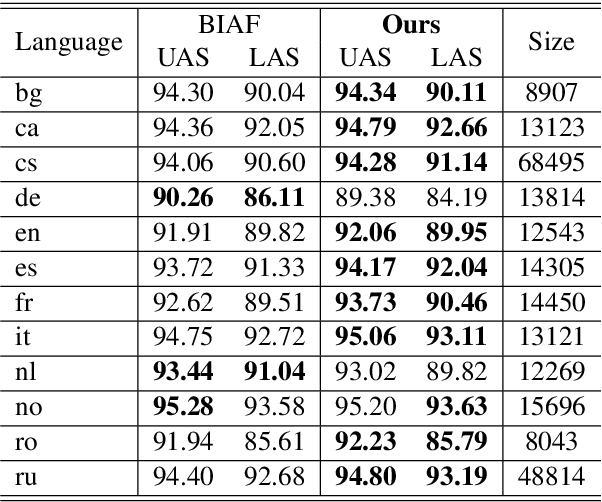
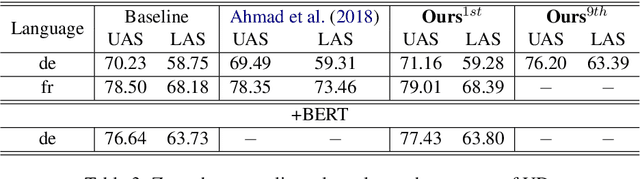
In natural language processing (NLP), cross-lingual transfer learning is as essential as in-domain learning due to the unavailability of annotated resources for low-resource languages. In this paper, we use the ability of a pre-training task that extracts universal features without supervision. We add two pre-training tasks as the auxiliary task into dependency parsing as multi-tasking, which improves the performance of the model in both in-domain and cross-lingual aspects. Moreover, inspired by the usefulness of self-training in cross-domain learning, we combine the traditional self-training and the two pre-training tasks. In this way, we can continuously extract universal features not only in training corpus but also in extra unannotated data and gain further improvement.