 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Dependency Parsing as Domain Adaptation
Paper and Code
Dec 24, 2020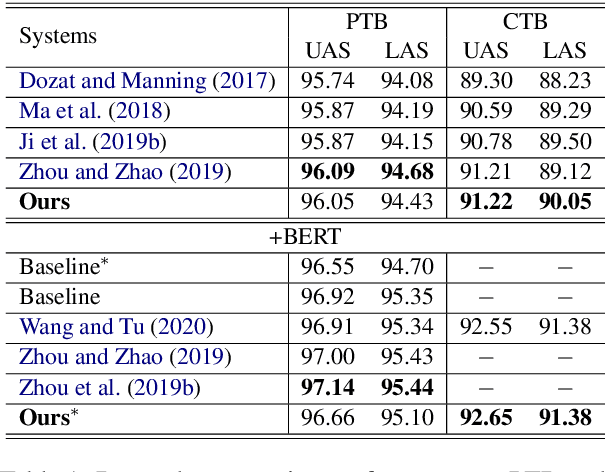
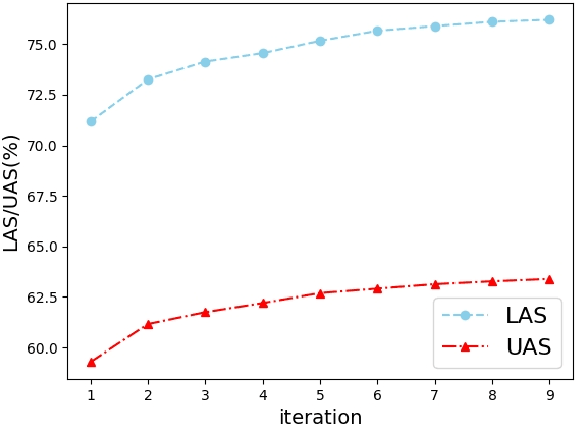
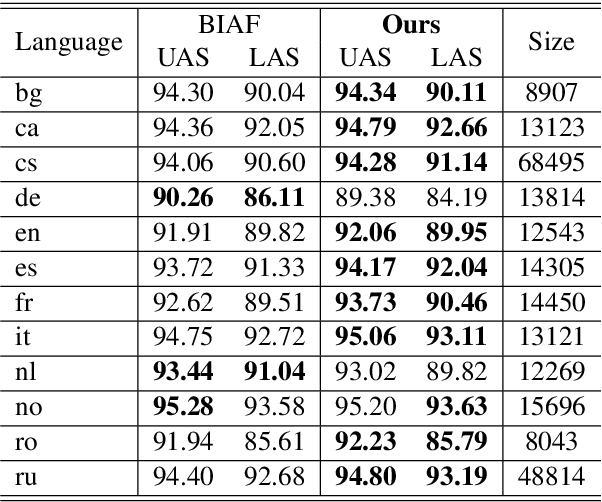
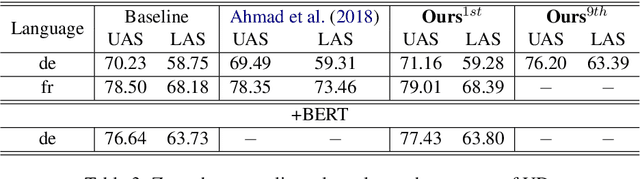
In natural language processing (NLP), cross-lingual transfer learning is as essential as in-domain learning due to the unavailability of annotated resources for low-resource languages. In this paper, we use the ability of a pre-training task that extracts universal features without supervision. We add two pre-training tasks as the auxiliary task into dependency parsing as multi-tasking, which improves the performance of the model in both in-domain and cross-lingual aspects. Moreover, inspired by the usefulness of self-training in cross-domain learning, we combine the traditional self-training and the two pre-training tasks. In this way, we can continuously extract universal features not only in training corpus but also in extra unannotated data and gain further improvement.