 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Unbalance in High-frequency Trading
Mar 13, 2025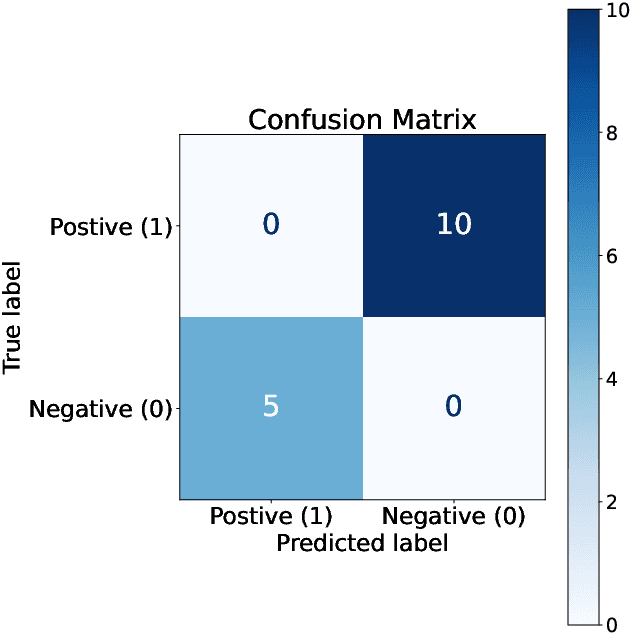
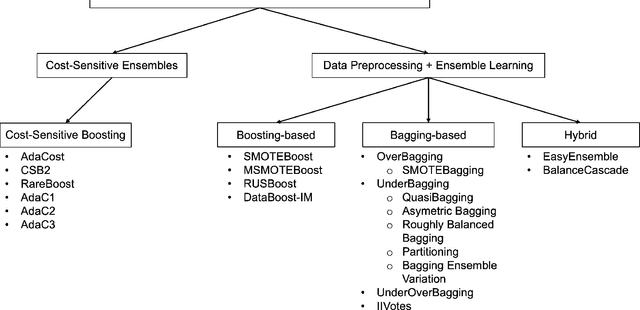
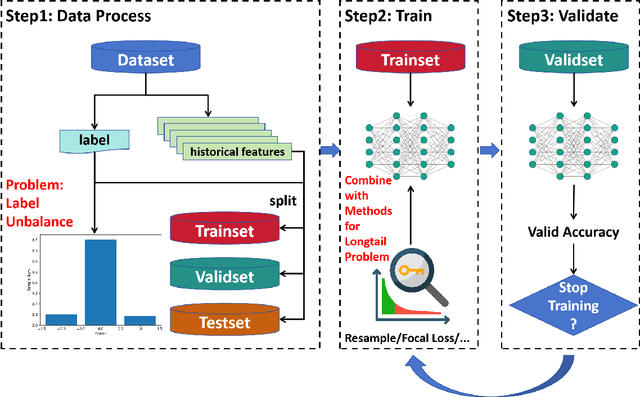
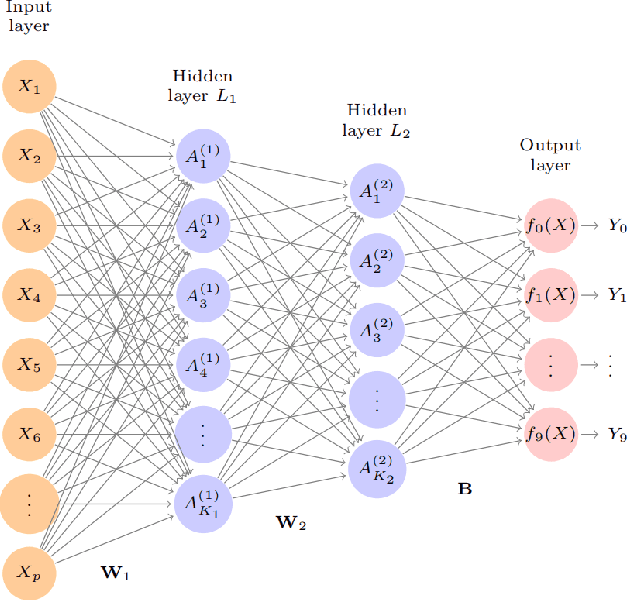
In financial trading, return prediction is one of the foundation for a successful trading system. By the fast development of the deep learning in various areas such as graphical processing, natural language, it has also demonstrate significant edge in handling with financial data. While the success of the deep learning relies on huge amount of labeled sample, labeling each time/event as profitable or unprofitable, under the transaction cost, especially in the high-frequency trading world, suffers from serious label imbalance issue.In this paper, we adopts rigurious end-to-end deep learning framework with comprehensive label imbalance adjustment methods and succeed in predicting in high-frequency return in the Chinese future market. The code for our method is publicly available at https://github.com/RS2002/Label-Unbalance-in-High-Frequency-Trading .
Episodic Novelty Through Temporal Distance
Jan 26, 2025Exploration in sparse reward environments remains a significant challenge in reinforcement learning, particularly in Contextual Markov Decision Processes (CMDPs), where environments differ across episodes. Existing episodic intrinsic motivation methods for CMDPs primarily rely on count-based approaches, which are ineffective in large state spaces, or on similarity-based methods that lack appropriate metrics for state comparison. To address these shortcomings, we propose Episodic Novelty Through Temporal Distance (ETD), a novel approach that introduces temporal distance as a robust metric for state similarity and intrinsic reward computation. By employing contrastive learning, ETD accurately estimates temporal distances and derives intrinsic rewards based on the novelty of states within the current episode. Extensive experiments on various benchmark tasks demonstrate that ETD significantly outperforms state-of-the-art methods, highlighting its effectiveness in enhancing exploration in sparse reward CMDPs.
Efficient Multi-agent Reinforcement Learning by Planning
May 20, 2024Multi-agent reinforcement learning (MARL) algorithms have accomplished remarkable breakthroughs in solving large-scale decision-making tasks. Nonetheless, most existing MARL algorithms are model-free, limiting sample efficiency and hindering their applicability in more challenging scenarios. In contrast, model-based reinforcement learning (MBRL), particularly algorithms integrating planning, such as MuZero, has demonstrated superhuman performance with limited data in many tasks. Hence, we aim to boost the sample efficiency of MARL by adopting model-based approaches. However, incorporating planning and search methods into multi-agent systems poses significant challenges. The expansive action space of multi-agent systems often necessitates leveraging the nearly-independent property of agents to accelerate learning. To tackle this issue, we propose the MAZero algorithm, which combines a centralized model with Monte Carlo Tree Search (MCTS) for policy search. We design a novel network structure to facilitate distributed execution and parameter sharing. To enhance search efficiency in deterministic environments with sizable action spaces, we introduce two novel techniques: Optimistic Search Lambda (OS($\lambda$)) and Advantage-Weighted Policy Optimization (AWPO). Extensive experiments on the SMAC benchmark demonstrate that MAZero outperforms model-free approaches in terms of sample efficiency and provides comparable or better performance than existing model-based methods in terms of both sample and computational efficiency. Our code is available at https://github.com/liuqh16/MAZero.
SEABO: A Simple Search-Based Method for Offline Imitation Learning
Feb 06, 2024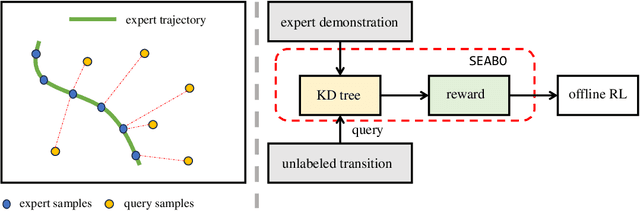
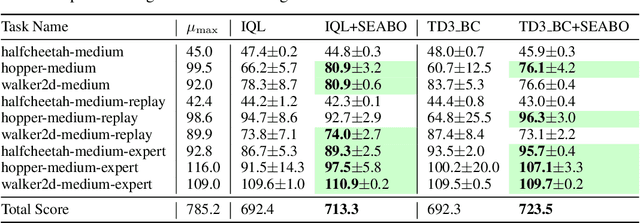
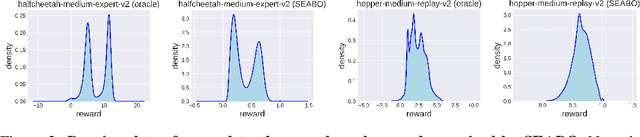

Offline reinforcement learning (RL) has attracted much attention due to its ability in learning from static offline datasets and eliminating the need of interacting with the environment. Nevertheless, the success of offline RL relies heavily on the offline transitions annotated with reward labels. In practice, we often need to hand-craft the reward function, which is sometimes difficult, labor-intensive, or inefficient. To tackle this challenge, we set our focus on the offline imitation learning (IL) setting, and aim at getting a reward function based on the expert data and unlabeled data. To that end, we propose a simple yet effective search-based offline IL method, tagged SEABO. SEABO allocates a larger reward to the transition that is close to its closest neighbor in the expert demonstration, and a smaller reward otherwise, all in an unsupervised learning manner. Experimental results on a variety of D4RL datasets indicate that SEABO can achieve competitive performance to offline RL algorithms with ground-truth rewards, given only a single expert trajectory, and can outperform prior reward learning and offline IL methods across many tasks. Moreover, we demonstrate that SEABO also works well if the expert demonstrations contain only observations. Our code is publicly available at https://github.com/dmksjfl/SEABO.
What is Essential for Unseen Goal Generalization of Offline Goal-conditioned RL?
Jun 02, 2023

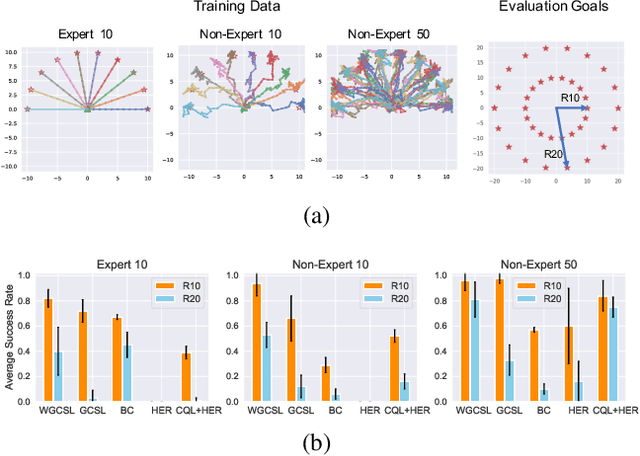
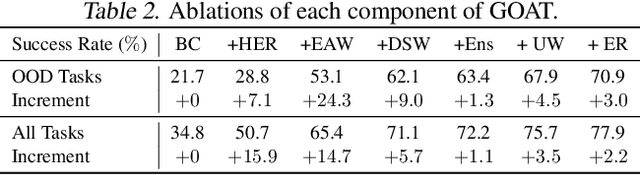
Offline goal-conditioned RL (GCRL) offers a way to train general-purpose agents from fully offline datasets. In addition to being conservative within the dataset, the generalization ability to achieve unseen goals is another fundamental challenge for offline GCRL. However, to the best of our knowledge, this problem has not been well studied yet. In this paper, we study out-of-distribution (OOD) generalization of offline GCRL both theoretically and empirically to identify factors that are important. In a number of experiments, we observe that weighted imitation learning enjoys better generalization than pessimism-based offline RL method. Based on this insight, we derive a theory for OOD generalization, which characterizes several important design choices. We then propose a new offline GCRL method, Generalizable Offline goAl-condiTioned RL (GOAT), by combining the findings from our theoretical and empirical studies. On a new benchmark containing 9 independent identically distributed (IID) tasks and 17 OOD tasks, GOAT outperforms current state-of-the-art methods by a large margin.
Cross-Domain Policy Adaptation via Value-Guided Data Filtering
May 28, 2023Generalizing policies across different domains with dynamics mismatch poses a significant challenge in reinforcement learning. For example, a robot learns the policy in a simulator, but when it is deployed in the real world, the dynamics of the environment may be different. Given the source and target domain with dynamics mismatch, we consider the online dynamics adaptation problem, in which case the agent can access sufficient source domain data while online interactions with the target domain are limited. Existing research has attempted to solve the problem from the dynamics discrepancy perspective. In this work, we reveal the limitations of these methods and explore the problem from the value difference perspective via a novel insight on the value consistency across domains. Specifically, we present the Value-Guided Data Filtering (VGDF) algorithm, which selectively shares transitions from the source domain based on the proximity of paired value targets across the two domains. Empirical results on various environments with kinematic and morphology shifts demonstrate that our method achieves superior performance compared to prior approaches.
Learning Diverse Risk Preferences in Population-based Self-play
May 19, 2023



Among the great successes of Reinforcement Learning (RL), self-play algorithms play an essential role in solving competitive games. Current self-play algorithms optimize the agent to maximize expected win-rates against its current or historical copies, making it often stuck in the local optimum and its strategy style simple and homogeneous. A possible solution is to improve the diversity of policies, which helps the agent break the stalemate and enhances its robustness when facing different opponents. However, enhancing diversity in the self-play algorithms is not trivial. In this paper, we aim to introduce diversity from the perspective that agents could have diverse risk preferences in the face of uncertainty. Specifically, we design a novel reinforcement learning algorithm called Risk-sensitive Proximal Policy Optimization (RPPO), which smoothly interpolates between worst-case and best-case policy learning and allows for policy learning with desired risk preferences. Seamlessly integrating RPPO with population-based self-play, agents in the population optimize dynamic risk-sensitive objectives with experiences from playing against diverse opponents. Empirical results show that our method achieves comparable or superior performance in competitive games and that diverse modes of behaviors emerge. Our code is public online at \url{https://github.com/Jackory/RPBT}.
Uncertainty-driven Trajectory Truncation for Model-based Offline Reinforcement Learning
Apr 10, 2023



Equipped with the trained environmental dynamics, model-based offline reinforcement learning (RL) algorithms can often successfully learn good policies from fixed-sized datasets, even some datasets with poor quality. Unfortunately, however, it can not be guaranteed that the generated samples from the trained dynamics model are reliable (e.g., some synthetic samples may lie outside of the support region of the static dataset). To address this issue, we propose Trajectory Truncation with Uncertainty (TATU), which adaptively truncates the synthetic trajectory if the accumulated uncertainty along the trajectory is too large. We theoretically show the performance bound of TATU to justify its benefits. To empirically show the advantages of TATU, we first combine it with two classical model-based offline RL algorithms, MOPO and COMBO. Furthermore, we integrate TATU with several off-the-shelf model-free offline RL algorithms, e.g., BCQ. Experimental results on the D4RL benchmark show that TATU significantly improves their performance, often by a large margin.
Single-Trajectory Distributionally Robust Reinforcement Learning
Jan 27, 2023

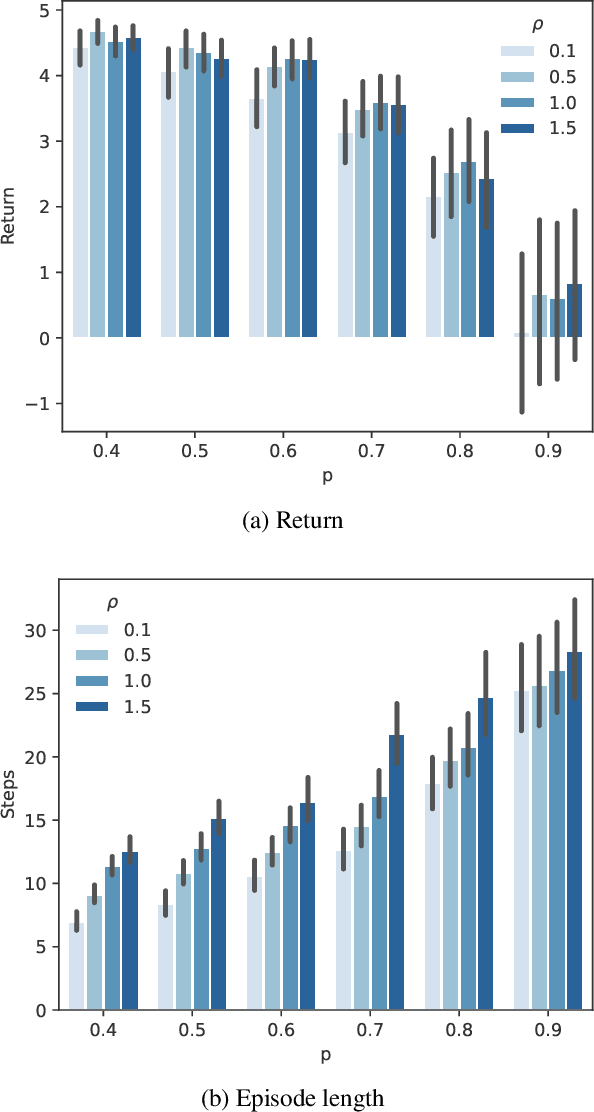

As a framework for sequential decision-making, Reinforcement Learning (RL) has been regarded as an essential component leading to Artificial General Intelligence (AGI). However, RL is often criticized for having the same training environment as the test one, which also hinders its application in the real world. To mitigate this problem, Distributionally Robust RL (DRRL) is proposed to improve the worst performance in a set of environments that may contain the unknown test environment. Due to the nonlinearity of the robustness goal, most of the previous work resort to the model-based approach, learning with either an empirical distribution learned from the data or a simulator that can be sampled infinitely, which limits their applications in simple dynamics environments. In contrast, we attempt to design a DRRL algorithm that can be trained along a single trajectory, i.e., no repeated sampling from a state. Based on the standard Q-learning, we propose distributionally robust Q-learning with the single trajectory (DRQ) and its average-reward variant named differential DRQ. We provide asymptotic convergence guarantees and experiments for both settings, demonstrating their superiority in the perturbed environments against the non-robust ones.
Distributionally Robust Offline Reinforcement Learning with Linear Function Approximation
Sep 29, 2022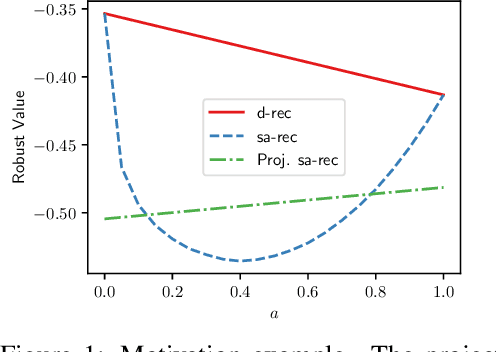
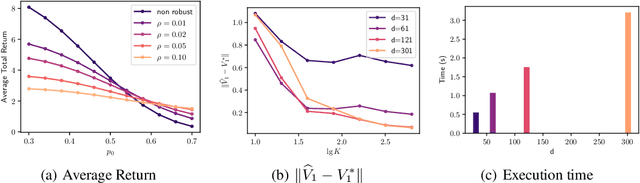
Among the reasons hindering reinforcement learning (RL) applications to real-world problems, two factors are critical: limited data and the mismatch between the testing environment (real environment in which the policy is deployed) and the training environment (e.g., a simulator). This paper attempts to address these issues simultaneously with distributionally robust offline RL, where we learn a distributionally robust policy using historical data obtained from the source environment by optimizing against a worst-case perturbation thereof. In particular, we move beyond tabular settings and consider linear function approximation. More specifically, we consider two settings, one where the dataset is well-explored and the other where the dataset has sufficient coverage. We propose two algorithms -- one for each of the two settings -- that achieve error bounds $\tilde{O}(d^{1/2}/N^{1/2})$ and $\tilde{O}(d^{3/2}/N^{1/2})$ respectively, where $d$ is the dimension in the linear function approximation and $N$ is the number of trajectories in the dataset. To the best of our knowledge, they provide the first non-asymptotic results of the sample complexity in this setting. Diverse experiments are conducted to demonstrate our theoretical findings, showing the superiority of our algorithm against the non-robust one.