 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProAct: Agentic Lookahead in Interactive Environments
Feb 05, 2026Existing Large Language Model (LLM) agents struggle in interactive environments requiring long-horizon planning, primarily due to compounding errors when simulating future states. To address this, we propose ProAct, a framework that enables agents to internalize accurate lookahead reasoning through a two-stage training paradigm. First, we introduce Grounded LookAhead Distillation (GLAD), where the agent undergoes supervised fine-tuning on trajectories derived from environment-based search. By compressing complex search trees into concise, causal reasoning chains, the agent learns the logic of foresight without the computational overhead of inference-time search. Second, to further refine decision accuracy, we propose the Monte-Carlo Critic (MC-Critic), a plug-and-play auxiliary value estimator designed to enhance policy-gradient algorithms like PPO and GRPO. By leveraging lightweight environment rollouts to calibrate value estimates, MC-Critic provides a low-variance signal that facilitates stable policy optimization without relying on expensive model-based value approximation. Experiments on both stochastic (e.g., 2048) and deterministic (e.g., Sokoban) environments demonstrate that ProAct significantly improves planning accuracy. Notably, a 4B parameter model trained with ProAct outperforms all open-source baselines and rivals state-of-the-art closed-source models, while demonstrating robust generalization to unseen environments. The codes and models are available at https://github.com/GreatX3/ProAct
Cross-Domain Offline Policy Adaptation via Selective Transition Correction
Feb 05, 2026It remains a critical challenge to adapt policies across domains with mismatched dynamics in reinforcement learning (RL). In this paper, we study cross-domain offline RL, where an offline dataset from another similar source domain can be accessed to enhance policy learning upon a target domain dataset. Directly merging the two datasets may lead to suboptimal performance due to potential dynamics mismatches. Existing approaches typically mitigate this issue through source domain transition filtering or reward modification, which, however, may lead to insufficient exploitation of the valuable source domain data. Instead, we propose to modify the source domain data into the target domain data. To that end, we leverage an inverse policy model and a reward model to correct the actions and rewards of source transitions, explicitly achieving alignment with the target dynamics. Since limited data may result in inaccurate model training, we further employ a forward dynamics model to retain corrected samples that better match the target dynamics than the original transitions. Consequently, we propose the Selective Transition Correction (STC) algorithm, which enables reliable usage of source domain data for policy adaptation. Experiments on various environments with dynamics shifts demonstrate that STC achieves superior performance against existing baselines.
EntroPIC: Towards Stable Long-Term Training of LLMs via Entropy Stabilization with Proportional-Integral Control
Nov 19, 2025Long-term training of large language models (LLMs) requires maintaining stable exploration to prevent the model from collapsing into sub-optimal behaviors. Entropy is crucial in this context, as it controls exploration and helps avoid premature convergence to sub-optimal solutions. However, existing reinforcement learning methods struggle to maintain an appropriate level of entropy, as the training process involves a mix of positive and negative samples, each affecting entropy in different ways across steps. To address this, we propose Entropy stablilization via Proportional-Integral Control (EntroPIC), a novel method that adaptively adjusts the influence of positive and negative samples by dynamically tuning their loss coefficients. This approach stabilizes entropy throughout training, ensuring efficient exploration and steady progress. We provide a comprehensive theoretical analysis for both on-policy and off-policy learning settings, demonstrating that EntroPIC is effective at controlling entropy in large-scale LLM training. Experimental results show that our method successfully maintains desired entropy levels, enabling stable and optimal RL training for LLMs.
PROF: An LLM-based Reward Code Preference Optimization Framework for Offline Imitation Learning
Nov 14, 2025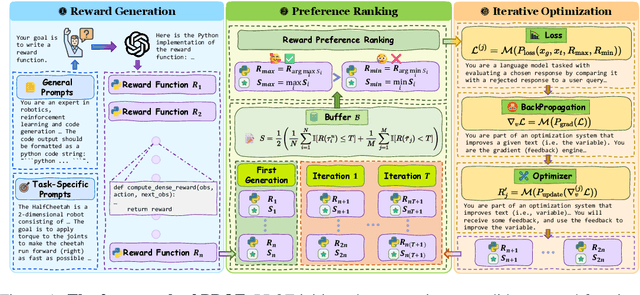
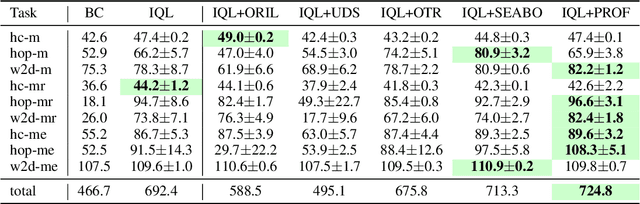

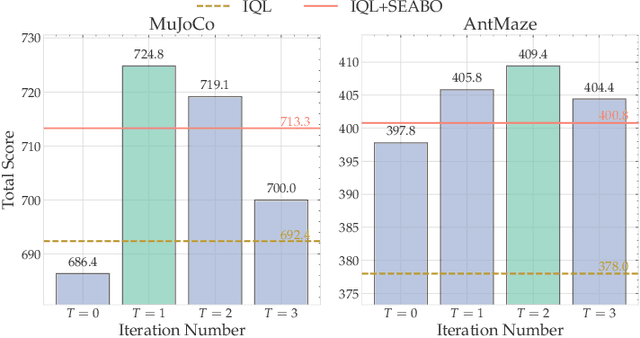
Offline imitation learning (offline IL) enables training effective policies without requiring explicit reward annotations. Recent approaches attempt to estimate rewards for unlabeled datasets using a small set of expert demonstrations. However, these methods often assume that the similarity between a trajectory and an expert demonstration is positively correlated with the reward, which oversimplifies the underlying reward structure. We propose PROF, a novel framework that leverages large language models (LLMs) to generate and improve executable reward function codes from natural language descriptions and a single expert trajectory. We propose Reward Preference Ranking (RPR), a novel reward function quality assessment and ranking strategy without requiring environment interactions or RL training. RPR calculates the dominance scores of the reward functions, where higher scores indicate better alignment with expert preferences. By alternating between RPR and text-based gradient optimization, PROF fully automates the selection and refinement of optimal reward functions for downstream policy learning. Empirical results on D4RL demonstrate that PROF surpasses or matches recent strong baselines across numerous datasets and domains, highlighting the effectiveness of our approach.
ADG: Ambient Diffusion-Guided Dataset Recovery for Corruption-Robust Offline Reinforcement Learning
May 29, 2025Real-world datasets collected from sensors or human inputs are prone to noise and errors, posing significant challenges for applying offline reinforcement learning (RL). While existing methods have made progress in addressing corrupted actions and rewards, they remain insufficient for handling corruption in high-dimensional state spaces and for cases where multiple elements in the dataset are corrupted simultaneously. Diffusion models, known for their strong denoising capabilities, offer a promising direction for this problem-but their tendency to overfit noisy samples limits their direct applicability. To overcome this, we propose Ambient Diffusion-Guided Dataset Recovery (ADG), a novel approach that pioneers the use of diffusion models to tackle data corruption in offline RL. First, we introduce Ambient Denoising Diffusion Probabilistic Models (DDPM) from approximated distributions, which enable learning on partially corrupted datasets with theoretical guarantees. Second, we use the noise-prediction property of Ambient DDPM to distinguish between clean and corrupted data, and then use the clean subset to train a standard DDPM. Third, we employ the trained standard DDPM to refine the previously identified corrupted data, enhancing data quality for subsequent offline RL training. A notable strength of ADG is its versatility-it can be seamlessly integrated with any offline RL algorithm. Experiments on a range of benchmarks, including MuJoCo, Kitchen, and Adroit, demonstrate that ADG effectively mitigates the impact of corrupted data and improves the robustness of offline RL under various noise settings, achieving state-of-the-art results.
Exploration by Random Distribution Distillation
May 16, 2025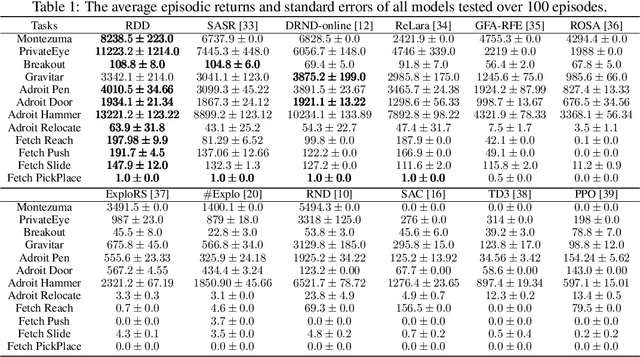
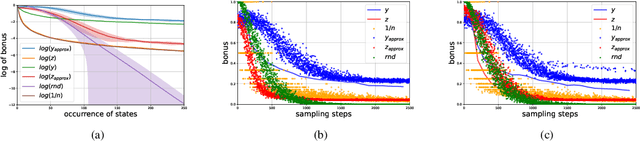
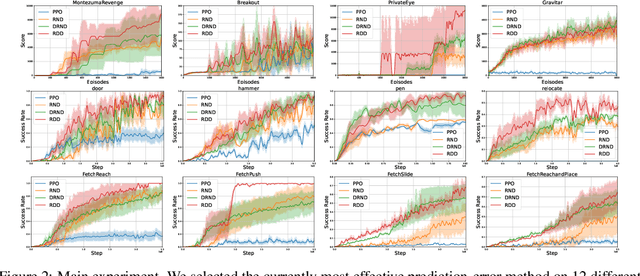
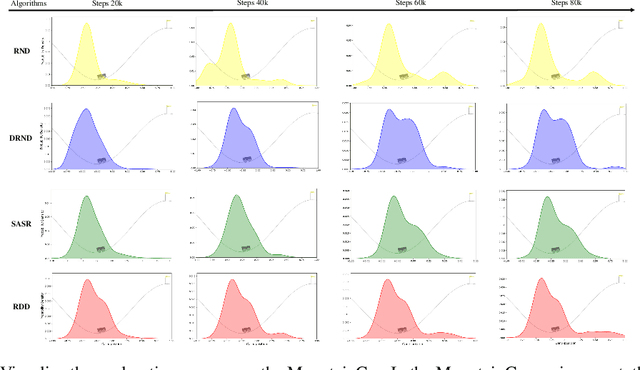
Exploration remains a critical challenge in online reinforcement learning, as an agent must effectively explore unknown environments to achieve high returns. Currently, the main exploration algorithms are primarily count-based methods and curiosity-based methods, with prediction-error methods being a prominent example. In this paper, we propose a novel method called \textbf{R}andom \textbf{D}istribution \textbf{D}istillation (RDD), which samples the output of a target network from a normal distribution. RDD facilitates a more extensive exploration by explicitly treating the difference between the prediction network and the target network as an intrinsic reward. Furthermore, by introducing randomness into the output of the target network for a given state and modeling it as a sample from a normal distribution, intrinsic rewards are bounded by two key components: a pseudo-count term ensuring proper exploration decay and a discrepancy term accounting for predictor convergence. We demonstrate that RDD effectively unifies both count-based and prediction-error approaches. It retains the advantages of prediction-error methods in high-dimensional spaces, while also implementing an intrinsic reward decay mode akin to the pseudo-count method. In the experimental section, RDD is compared with more advanced methods in a series of environments. Both theoretical analysis and experimental results confirm the effectiveness of our approach in improving online exploration for reinforcement learning tasks.
GenPRM: Scaling Test-Time Compute of Process Reward Models via Generative Reasoning
Apr 01, 2025Recent advancements in Large Language Models (LLMs) have shown that it is promising to utilize Process Reward Models (PRMs) as verifiers to enhance the performance of LLMs. However, current PRMs face three key challenges: (1) limited process supervision and generalization capabilities, (2) dependence on scalar value prediction without leveraging the generative abilities of LLMs, and (3) inability to scale the test-time compute of PRMs. In this work, we introduce GenPRM, a generative process reward model that performs explicit Chain-of-Thought (CoT) reasoning with code verification before providing judgment for each reasoning step. To obtain high-quality process supervision labels and rationale data, we propose Relative Progress Estimation (RPE) and a rationale synthesis framework that incorporates code verification. Experimental results on ProcessBench and several mathematical reasoning tasks show that GenPRM significantly outperforms prior PRMs with only 23K training data from MATH dataset. Through test-time scaling, a 1.5B GenPRM outperforms GPT-4o, and a 7B GenPRM surpasses Qwen2.5-Math-PRM-72B on ProcessBench. Additionally, GenPRM demonstrates strong abilities to serve as a critic model for policy model refinement. This work establishes a new paradigm for process supervision that bridges the gap between PRMs and critic models in LLMs. Our code, model, and data will be available in https://ryanliu112.github.io/GenPRM.
VLP: Vision-Language Preference Learning for Embodied Manipulation
Feb 17, 2025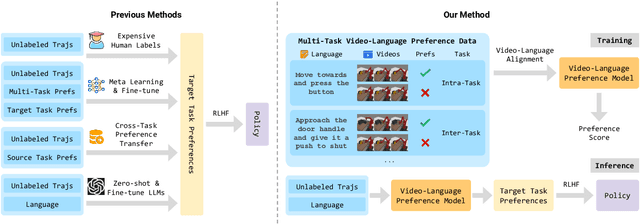

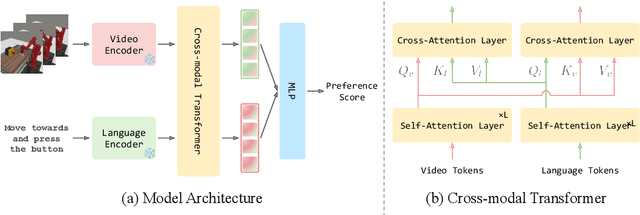
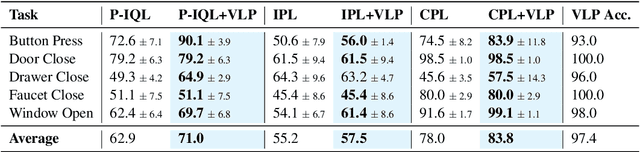
Reward engineering is one of the key challenges in Reinforcement Learning (RL). Preference-based RL effectively addresses this issue by learning from human feedback. However, it is both time-consuming and expensive to collect human preference labels. In this paper, we propose a novel \textbf{V}ision-\textbf{L}anguage \textbf{P}reference learning framework, named \textbf{VLP}, which learns a vision-language preference model to provide preference feedback for embodied manipulation tasks. To achieve this, we define three types of language-conditioned preferences and construct a vision-language preference dataset, which contains versatile implicit preference orders without human annotations. The preference model learns to extract language-related features, and then serves as a preference annotator in various downstream tasks. The policy can be learned according to the annotated preferences via reward learning or direct policy optimization. Extensive empirical results on simulated embodied manipulation tasks demonstrate that our method provides accurate preferences and generalizes to unseen tasks and unseen language instructions, outperforming the baselines by a large margin.
Novelty-Guided Data Reuse for Efficient and Diversified Multi-Agent Reinforcement Learning
Dec 20, 2024Recently, deep Multi-Agent Reinforcement Learning (MARL) has demonstrated its potential to tackle complex cooperative tasks, pushing the boundaries of AI in collaborative environments. However, the efficiency of these systems is often compromised by inadequate sample utilization and a lack of diversity in learning strategies. To enhance MARL performance, we introduce a novel sample reuse approach that dynamically adjusts policy updates based on observation novelty. Specifically, we employ a Random Network Distillation (RND) network to gauge the novelty of each agent's current state, assigning additional sample update opportunities based on the uniqueness of the data. We name our method Multi-Agent Novelty-GuidEd sample Reuse (MANGER). This method increases sample efficiency and promotes exploration and diverse agent behaviors. Our evaluations confirm substantial improvements in MARL effectiveness in complex cooperative scenarios such as Google Research Football and super-hard StarCraft II micromanagement tasks.
ODRL: A Benchmark for Off-Dynamics Reinforcement Learning
Oct 28, 2024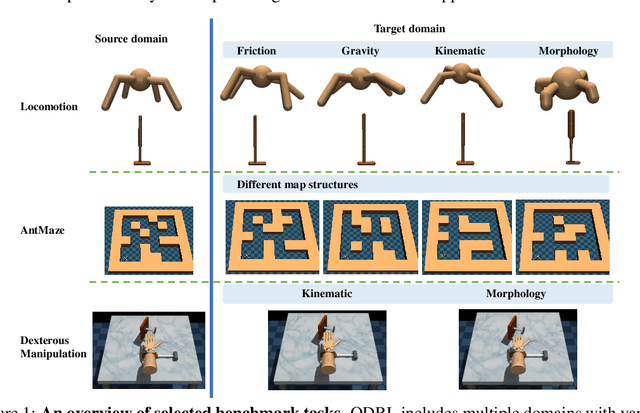

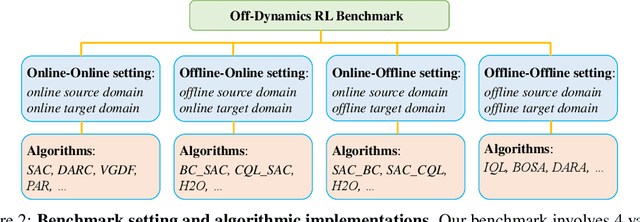

We consider off-dynamics reinforcement learning (RL) where one needs to transfer policies across different domains with dynamics mismatch. Despite the focus on developing dynamics-aware algorithms, this field is hindered due to the lack of a standard benchmark. To bridge this gap, we introduce ODRL, the first benchmark tailored for evaluating off-dynamics RL methods. ODRL contains four experimental settings where the source and target domains can be either online or offline, and provides diverse tasks and a broad spectrum of dynamics shifts, making it a reliable platform to comprehensively evaluate the agent's adaptation ability to the target domain. Furthermore, ODRL includes recent off-dynamics RL algorithms in a unified framework and introduces some extra baselines for different settings, all implemented in a single-file manner. To unpack the true adaptation capability of existing methods, we conduct extensive benchmarking experiments, which show that no method has universal advantages across varied dynamics shifts. We hope this benchmark can serve as a cornerstone for future research endeavors. Our code is publicly available at https://github.com/OffDynamicsRL/off-dynamics-rl.