 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODRL: A Benchmark for Off-Dynamics Reinforcement Learning
Paper and Code
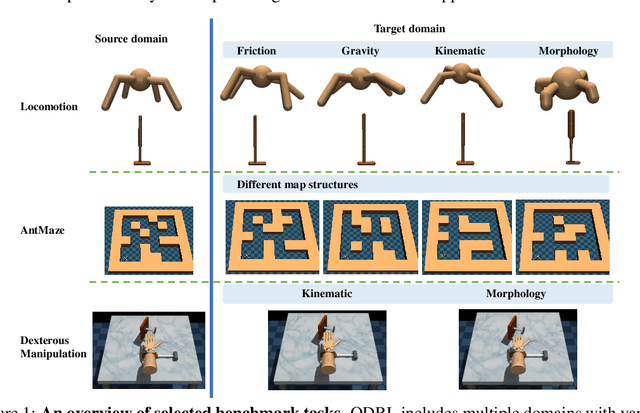

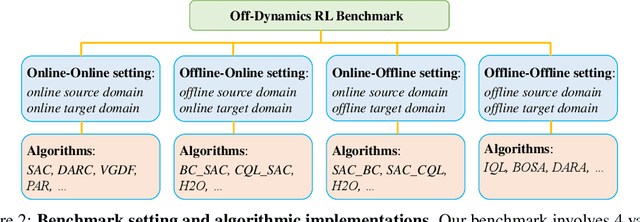

We consider off-dynamics reinforcement learning (RL) where one needs to transfer policies across different domains with dynamics mismatch. Despite the focus on developing dynamics-aware algorithms, this field is hindered due to the lack of a standard benchmark. To bridge this gap, we introduce ODRL, the first benchmark tailored for evaluating off-dynamics RL methods. ODRL contains four experimental settings where the source and target domains can be either online or offline, and provides diverse tasks and a broad spectrum of dynamics shifts, making it a reliable platform to comprehensively evaluate the agent's adaptation ability to the target domain. Furthermore, ODRL includes recent off-dynamics RL algorithms in a unified framework and introduces some extra baselines for different settings, all implemented in a single-file manner. To unpack the true adaptation capability of existing methods, we conduct extensive benchmarking experiments, which show that no method has universal advantages across varied dynamics shifts. We hope this benchmark can serve as a cornerstone for future research endeavors. Our code is publicly available at https://github.com/OffDynamicsRL/off-dynamics-rl.