 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
How Far Are Large Multimodal Models from Human-Level Spatial Action? A Benchmark for Goal-Oriented Embodied Navigation in Urban Airspace
Apr 09, 2026Large multimodal models (LMMs) show strong visual-linguistic reasoning but their capacity for spatial decision-making and action remains unclear. In this work, we investigate whether LMMs can achieve embodied spatial action like human through a challenging scenario: goal-oriented navigation in urban 3D spaces. We first spend over 500 hours constructing a dataset comprising 5,037 high-quality goal-oriented navigation samples, with an emphasis on 3D vertical actions and rich urban semantic information. Then, we comprehensively assess 17 representative models, including non-reasoning LMMs, reasoning LMMs, agent-based methods, and vision-language-action models. Experiments show that current LMMs exhibit emerging action capabilities, yet remain far from human-level performance. Furthermore, we reveal an intriguing phenomenon: navigation errors do not accumulate linearly but instead diverge rapidly from the destination after a critical decision bifurcation. The limitations of LMMs are investigated by analyzing their behavior at these critical decision bifurcations. Finally, we experimentally explore four promising directions for improvement: geometric perception, cross-view understanding, spatial imagination, and long-term memory. The project is available at: https://github.com/serenditipy-AC/Embodied-Navigation-Bench.
Grasp as You Dream: Imitating Functional Grasping from Generated Human Demonstrations
Apr 08, 2026Building generalist robots capable of performing functional grasping in everyday, open-world environments remains a significant challenge due to the vast diversity of objects and tasks. Existing methods are either constrained to narrow object/task sets or rely on prohibitively large-scale data collection to capture real-world variability. In this work, we present an alternative approach, GraspDreamer, a method that leverages human demonstrations synthesized by visual generative models (VGMs) (e.g., video generation models) to enable zero-shot functional grasping without labor-intensive data collection. The key idea is that VGMs pre-trained on internet-scale human data implicitly encode generalized priors about how humans interact with the physical world, which can be combined with embodiment-specific action optimization to enable functional grasping with minimal effort. Extensive experiments on the public benchmarks with different robot hands demonstrate the superior data efficiency and generalization performance of GraspDreamer compared to previous methods. Real-world evaluations further validate the effectiveness on real robots. Additionally, we showcase that GraspDreamer can (1) be naturally extended to downstream manipulation tasks, and (2) can generate data to support visuomotor policy learning.
Deep Dubbing: End-to-End Auto-Audiobook System with Text-to-Timbre and Context-Aware Instruct-TTS
Sep 19, 2025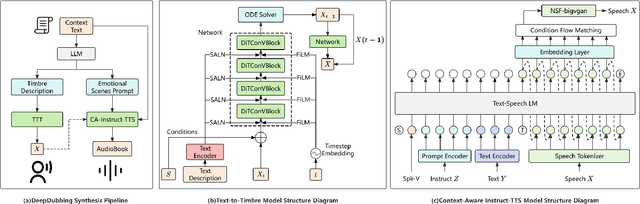


The pipeline for multi-participant audiobook production primarily consists of three stages: script analysis, character voice timbre selection, and speech synthesis. Among these, script analysis can be automated with high accuracy using NLP models, whereas character voice timbre selection still relies on manual effort. Speech synthesis uses either manual dubbing or text-to-speech (TTS). While TTS boosts efficiency, it struggles with emotional expression, intonation control, and contextual scene adaptation. To address these challenges, we propose DeepDubbing, an end-to-end automated system for multi-participant audiobook production. The system comprises two main components: a Text-to-Timbre (TTT) model and a Context-Aware Instruct-TTS (CA-Instruct-TTS) model. The TTT model generates role-specific timbre embeddings conditioned on text descriptions. The CA-Instruct-TTS model synthesizes expressive speech by analyzing contextual dialogue and incorporating fine-grained emotional instructions. This system enables the automated generation of multi-participant audiobooks with both timbre-matched character voices and emotionally expressive narration, offering a novel solution for audiobook production.
Traits Run Deep: Enhancing Personality Assessment via Psychology-Guided LLM Representations and Multimodal Apparent Behaviors
Jul 30, 2025



Accurate and reliable personality assessment plays a vital role in many fields, such as emotional intelligence, mental health diagnostics, and personalized education. Unlike fleeting emotions, personality traits are stable, often subconsciously leaked through language, facial expressions, and body behaviors, with asynchronous patterns across modalities. It was hard to model personality semantics with traditional superficial features and seemed impossible to achieve effective cross-modal understanding. To address these challenges, we propose a novel personality assessment framework called \textit{\textbf{Traits Run Deep}}. It employs \textit{\textbf{psychology-informed prompts}} to elicit high-level personality-relevant semantic representations. Besides, it devises a \textit{\textbf{Text-Centric Trait Fusion Network}} that anchors rich text semantics to align and integrate asynchronous signals from other modalities. To be specific, such fusion module includes a Chunk-Wise Projector to decrease dimensionality, a Cross-Modal Connector and a Text Feature Enhancer for effective modality fusion and an ensemble regression head to improve generalization in data-scarce situations. To our knowledge, we are the first to apply personality-specific prompts to guide large language models (LLMs) in extracting personality-aware semantics for improved representation quality. Furthermore, extracting and fusing audio-visual apparent behavior features further improves the accuracy. Experimental results on the AVI validation set have demonstrated the effectiveness of the proposed components, i.e., approximately a 45\% reduction in mean squared error (MSE). Final evaluations on the test set of the AVI Challenge 2025 confirm our method's superiority, ranking first in the Personality Assessment track. The source code will be made available at https://github.com/MSA-LMC/TraitsRunDeep.
Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy
Jul 02, 2025Despite the critical role of reward models (RMs) in reinforcement learning from human feedback (RLHF), current state-of-the-art open RMs perform poorly on most existing evaluation benchmarks, failing to capture the spectrum of nuanced and sophisticated human preferences. Even approaches that incorporate advanced training techniques have not yielded meaningful performance improvements. We hypothesize that this brittleness stems primarily from limitations in preference datasets, which are often narrowly scoped, synthetically labeled, or lack rigorous quality control. To address these challenges, we present a large-scale preference dataset comprising 40 million preference pairs, named SynPref-40M. To enable data curation at scale, we design a human-AI synergistic two-stage pipeline that leverages the complementary strengths of human annotation quality and AI scalability. In this pipeline, humans provide verified annotations, while large language models perform automatic curation based on human guidance. Training on this preference mixture, we introduce Skywork-Reward-V2, a suite of eight reward models ranging from 0.6B to 8B parameters, trained on a carefully curated subset of 26 million preference pairs from SynPref-40M. We demonstrate that Skywork-Reward-V2 is versatile across a wide range of capabilities, including alignment with human preferences, objective correctness, safety, resistance to stylistic biases, and best-of-N scaling, achieving state-of-the-art performance across seven major reward model benchmarks. Ablation studies confirm that the effectiveness of our approach stems not only from data scale but also from high-quality curation. The Skywork-Reward-V2 series represents substantial progress in open reward models, highlighting the untapped potential of existing preference datasets and demonstrating how human-AI curation synergy can unlock significantly higher data quality.
Skywork Open Reasoner 1 Technical Report
May 29, 2025The success of DeepSeek-R1 underscores the significant role of reinforcement learning (RL) in enhancing the reasoning capabilities of large language models (LLMs). In this work, we present Skywork-OR1, an effective and scalable RL implementation for long Chain-of-Thought (CoT) models. Building on the DeepSeek-R1-Distill model series, our RL approach achieves notable performance gains, increasing average accuracy across AIME24, AIME25, and LiveCodeBench from 57.8% to 72.8% (+15.0%) for the 32B model and from 43.6% to 57.5% (+13.9%) for the 7B model. Our Skywork-OR1-32B model surpasses both DeepSeek-R1 and Qwen3-32B on the AIME24 and AIME25 benchmarks, while achieving comparable results on LiveCodeBench. The Skywork-OR1-7B and Skywork-OR1-Math-7B models demonstrate competitive reasoning capabilities among models of similar size. We perform comprehensive ablation studies on the core components of our training pipeline to validate their effectiveness. Additionally, we thoroughly investigate the phenomenon of entropy collapse, identify key factors affecting entropy dynamics, and demonstrate that mitigating premature entropy collapse is critical for improved test performance. To support community research, we fully open-source our model weights, training code, and training datasets.
Policy Regularization on Globally Accessible States in Cross-Dynamics Reinforcement Learning
Mar 10, 2025To learn from data collected in diverse dynamics, Imitation from Observation (IfO) methods leverage expert state trajectories based on the premise that recovering expert state distributions in other dynamics facilitates policy learning in the current one. However, Imitation Learning inherently imposes a performance upper bound of learned policies. Additionally, as the environment dynamics change, certain expert states may become inaccessible, rendering their distributions less valuable for imitation. To address this, we propose a novel framework that integrates reward maximization with IfO, employing F-distance regularized policy optimization. This framework enforces constraints on globally accessible states--those with nonzero visitation frequency across all considered dynamics--mitigating the challenge posed by inaccessible states. By instantiating F-distance in different ways, we derive two theoretical analysis and develop a practical algorithm called Accessible State Oriented Policy Regularization (ASOR). ASOR serves as a general add-on module that can be incorporated into various RL approaches, including offline RL and off-policy RL. Extensive experiments across multiple benchmarks demonstrate ASOR's effectiveness in enhancing state-of-the-art cross-domain policy transfer algorithms, significantly improving their performance.
CLOVER: A Test Case Generation Benchmark with Coverage, Long-Context, and Verification
Feb 12, 2025Software testing is a critical aspect of software development, yet generating test cases remains a routine task for engineers. This paper presents a benchmark, CLOVER, to evaluate models' capabilities in generating and completing test cases under specific conditions. Spanning from simple assertion completions to writing test cases that cover specific code blocks across multiple files, these tasks are based on 12 python repositories, analyzing 845 problems with context lengths ranging from 4k to 128k tokens. Utilizing code testing frameworks, we propose a method to construct retrieval contexts using coverage information. While models exhibit comparable performance with short contexts, notable differences emerge with 16k contexts. Notably, models like GPT-4o and Claude 3.5 can effectively leverage relevant snippets; however, all models score below 35\% on the complex Task III, even with the oracle context provided, underscoring the benchmark's significance and the potential for model improvement. The benchmark is containerized for code execution across tasks, and we will release the code, data, and construction methodologies.
BOLT: Bootstrap Long Chain-of-Thought in Language Models without Distillation
Feb 06, 2025



Large language models (LLMs), such as o1 from OpenAI, have demonstrated remarkable reasoning capabilities. o1 generates a long chain-of-thought (LongCoT) before answering a question. LongCoT allows LLMs to analyze problems, devise plans, reflect, and backtrack effectively. These actions empower LLM to solve complex problems. After the release of o1, many teams have attempted to replicate its LongCoT and reasoning capabilities. In terms of methods, they primarily rely on knowledge distillation with data from existing models with LongCoT capacities (e.g., OpenAI-o1, Qwen-QwQ, DeepSeek-R1-Preview), leaving significant uncertainties on systematically developing such reasoning abilities. In terms of data domains, these works focus narrowly on math while a few others include coding, limiting their generalizability. This paper introduces a novel approach to enable LLM's LongCoT capacity without distillation from o1-like models or expensive human annotations, where we bootstrap LongCoT (BOLT) from a standard instruct model. BOLT involves three stages: 1) LongCoT data bootstrapping with in-context learning on a standard instruct model; 2) LongCoT supervised finetuning; 3) online training to further refine LongCoT capacities. In BOLT, only a few in-context examples need to be constructed during the bootstrapping stage; in our experiments, we created 10 examples, demonstrating the feasibility of this approach. We use Llama-3.1-70B-Instruct to bootstrap LongCoT and apply our method to various model scales (7B, 8B, 70B). We achieve impressive performance on a variety of benchmarks, Arena-Hard, MT-Bench, WildBench, ZebraLogic, MATH500, which evaluate diverse task-solving and reasoning capabilities.