 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBorderless Long Speech Synthesis
Mar 20, 2026Most existing text-to-speech (TTS) systems either synthesize speech sentence by sentence and stitch the results together, or drive synthesis from plain-text dialogues alone. Both approaches leave models with little understanding of global context or paralinguistic cues, making it hard to capture real-world phenomena such as multi-speaker interactions (interruptions, overlapping speech), evolving emotional arcs, and varied acoustic environments. We introduce the Borderless Long Speech Synthesis framework for agent-centric, borderless long audio synthesis. Rather than targeting a single narrow task, the system is designed as a unified capability set spanning VoiceDesigner, multi-speaker synthesis, Instruct TTS, and long-form text synthesis. On the data side, we propose a "Labeling over filtering/cleaning" strategy and design a top-down, multi-level annotation schema we call Global-Sentence-Token. On the model side, we adopt a backbone with a continuous tokenizer and add Chain-of-Thought (CoT) reasoning together with Dimension Dropout, both of which markedly improve instruction following under complex conditions. We further show that the system is Native Agentic by design: the hierarchical annotation doubles as a Structured Semantic Interface between the LLM Agent and the synthesis engine, creating a layered control protocol stack that spans from scene semantics down to phonetic detail. Text thereby becomes an information-complete, wide-band control channel, enabling a front-end LLM to convert inputs of any modality into structured generation commands, extending the paradigm from Text2Speech to borderless long speech synthesis.
SYKI-SVC: Advancing Singing Voice Conversion with Post-Processing Innovations and an Open-Source Professional Testset
Jan 06, 2025Singing voice conversion aims to transform a source singing voice into that of a target singer while preserving the original lyrics, melody, and various vocal techniques. In this paper, we propose a high-fidelity singing voice conversion system. Our system builds upon the SVCC T02 framework and consists of three key components: a feature extractor, a voice converter, and a post-processor. The feature extractor utilizes the ContentVec and Whisper models to derive F0 contours and extract speaker-independent linguistic features from the input singing voice. The voice converter then integrates the extracted timbre, F0, and linguistic content to synthesize the target speaker's waveform. The post-processor augments high-frequency information directly from the source through simple and effective signal processing to enhance audio quality. Due to the lack of a standardized professional dataset for evaluating expressive singing conversion systems, we have created and made publicly available a specialized test set. Comparative evaluations demonstrate that our system achieves a remarkably high level of naturalness, and further analysis confirms the efficacy of our proposed system design.
FGCL: Fine-grained Contrastive Learning For Mandarin Stuttering Event Detection
Oct 08, 2024
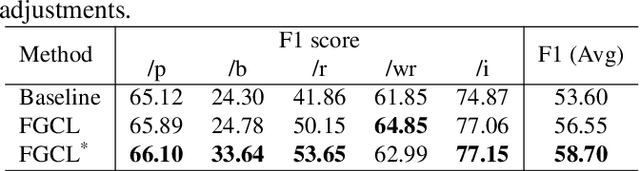
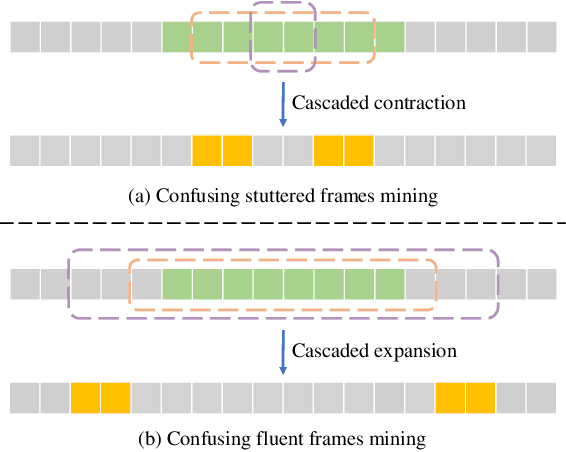
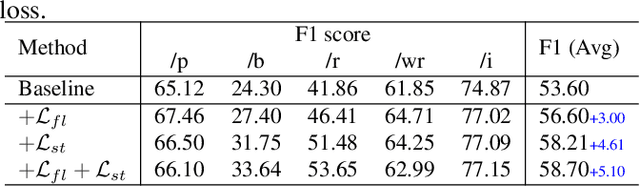
This paper presents the T031 team's approach to the StutteringSpeech Challenge in SLT2024. Mandarin Stuttering Event Detection (MSED) aims to detect instances of stuttering events in Mandarin speech. We propose a detailed acoustic analysis method to improve the accuracy of stutter detection by capturing subtle nuances that previous Stuttering Event Detection (SED) techniques have overlooked. To this end, we introduce the Fine-Grained Contrastive Learning (FGCL) framework for MSED. Specifically, we model the frame-level probabilities of stuttering events and introduce a mining algorithm to identify both easy and confusing frames. Then, we propose a stutter contrast loss to enhance the distinction between stuttered and fluent speech frames, thereby improving the discriminative capability of stuttered feature embeddings. Extensive evaluations on English and Mandarin datasets demonstrate the effectiveness of FGCL, achieving a significant increase of over 5.0% in F1 score on Mandarin data.