 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Discovery for Cross-Sectional Data Based on Super-Structure and Divide-and-Conquer
Feb 03, 2026This paper tackles a critical bottleneck in Super-Structure-based divide-and-conquer causal discovery: the high computational cost of constructing accurate Super-Structures--particularly when conditional independence (CI) tests are expensive and domain knowledge is unavailable. We propose a novel, lightweight framework that relaxes the strict requirements on Super-Structure construction while preserving the algorithmic benefits of divide-and-conquer. By integrating weakly constrained Super-Structures with efficient graph partitioning and merging strategies, our approach substantially lowers CI test overhead without sacrificing accuracy. We instantiate the framework in a concrete causal discovery algorithm and rigorously evaluate its components on synthetic data. Comprehensive experiments on Gaussian Bayesian networks, including magic-NIAB, ECOLI70, and magic-IRRI, demonstrate that our method matches or closely approximates the structural accuracy of PC and FCI while drastically reducing the number of CI tests. Further validation on the real-world China Health and Retirement Longitudinal Study (CHARLS) dataset confirms its practical applicability. Our results establish that accurate, scalable causal discovery is achievable even under minimal assumptions about the initial Super-Structure, opening new avenues for applying divide-and-conquer methods to large-scale, knowledge-scarce domains such as biomedical and social science research.
Latent Zoning Network: A Unified Principle for Generative Modeling, Representation Learning, and Classification
Sep 19, 2025Generative modeling, representation learning, and classification are three core problems in machine learning (ML), yet their state-of-the-art (SoTA) solutions remain largely disjoint. In this paper, we ask: Can a unified principle address all three? Such unification could simplify ML pipelines and foster greater synergy across tasks. We introduce Latent Zoning Network (LZN) as a step toward this goal. At its core, LZN creates a shared Gaussian latent space that encodes information across all tasks. Each data type (e.g., images, text, labels) is equipped with an encoder that maps samples to disjoint latent zones, and a decoder that maps latents back to data. ML tasks are expressed as compositions of these encoders and decoders: for example, label-conditional image generation uses a label encoder and image decoder; image embedding uses an image encoder; classification uses an image encoder and label decoder. We demonstrate the promise of LZN in three increasingly complex scenarios: (1) LZN can enhance existing models (image generation): When combined with the SoTA Rectified Flow model, LZN improves FID on CIFAR10 from 2.76 to 2.59-without modifying the training objective. (2) LZN can solve tasks independently (representation learning): LZN can implement unsupervised representation learning without auxiliary loss functions, outperforming the seminal MoCo and SimCLR methods by 9.3% and 0.2%, respectively, on downstream linear classification on ImageNet. (3) LZN can solve multiple tasks simultaneously (joint generation and classification): With image and label encoders/decoders, LZN performs both tasks jointly by design, improving FID and achieving SoTA classification accuracy on CIFAR10. The code and trained models are available at https://github.com/microsoft/latent-zoning-networks. The project website is at https://zinanlin.me/blogs/latent_zoning_networks.html.
Leveraging Geometric Visual Illusions as Perceptual Inductive Biases for Vision Models
Sep 18, 2025Contemporary deep learning models have achieved impressive performance in image classification by primarily leveraging statistical regularities within large datasets, but they rarely incorporate structured insights drawn directly from perceptual psychology. To explore the potential of perceptually motivated inductive biases, we propose integrating classic geometric visual illusions well-studied phenomena from human perception into standard image-classification training pipelines. Specifically, we introduce a synthetic, parametric geometric-illusion dataset and evaluate three multi-source learning strategies that combine illusion recognition tasks with ImageNet classification objectives. Our experiments reveal two key conceptual insights: (i) incorporating geometric illusions as auxiliary supervision systematically improves generalization, especially in visually challenging cases involving intricate contours and fine textures; and (ii) perceptually driven inductive biases, even when derived from synthetic stimuli traditionally considered unrelated to natural image recognition, can enhance the structural sensitivity of both CNN and transformer-based architectures. These results demonstrate a novel integration of perceptual science and machine learning and suggest new directions for embedding perceptual priors into vision model design.
M$^2$CD: A Unified MultiModal Framework for Optical-SAR Change Detection with Mixture of Experts and Self-Distillation
Mar 25, 2025Most existing change detection (CD) methods focus on optical images captured at different times, and deep learning (DL) has achieved remarkable success in this domain. However, in extreme scenarios such as disaster response, synthetic aperture radar (SAR), with its active imaging capability, is more suitable for providing post-event data. This introduces new challenges for CD methods, as existing weight-sharing Siamese networks struggle to effectively learn the cross-modal data distribution between optical and SAR images. To address this challenge, we propose a unified MultiModal CD framework, M$^2$CD. We integrate Mixture of Experts (MoE) modules into the backbone to explicitly handle diverse modalities, thereby enhancing the model's ability to learn multimodal data distributions. Additionally, we innovatively propose an Optical-to-SAR guided path (O2SP) and implement self-distillation during training to reduce the feature space discrepancy between different modalities, further alleviating the model's learning burden. We design multiple variants of M$^2$CD based on both CNN and Transformer backbones. Extensive experiments validate the effectiveness of the proposed framework, with the MiT-b1 version of M$^2$CD outperforming all state-of-the-art (SOTA) methods in optical-SAR CD tasks.
Generative Modeling of Adversarial Lane-Change Scenario
Mar 15, 2025



Decision-making in long-tail scenarios is crucial to autonomous driving development, with realistic and challenging simulations playing a pivotal role in testing safety-critical situations. However, the current open-source datasets do not systematically include long-tail distributed scenario data, making acquiring such scenarios a formidable task. To address this problem, a data mining framework is proposed, which performs in-depth analysis on two widely-used datasets, NGSIM and INTERACTION, to pinpoint data with hazardous behavioral traits, aiming to bridge the gap in these overlooked scenarios. The approach utilizes Generative Adversarial Imitation Learning (GAIL) based on an enhanced Proximal Policy Optimization (PPO) model, integrated with the vehicle's environmental analysis, to iteratively refine and represent the newly generated vehicle trajectory. Innovatively, the solution optimizes the generation of adversarial scenario data from the perspectives of sensitivity and reasonable adversarial. It is demonstrated through experiments that, compared to the unfiltered data and baseline models, the approach exhibits more adversarial yet natural behavior regarding collision rate, acceleration, and lane changes, thereby validating its suitability for generating scenario data and providing constructive insights for the development of future scenarios and subsequent decision training.
UIPE: Enhancing LLM Unlearning by Removing Knowledge Related to Forgetting Targets
Mar 06, 2025Large Language Models (LLMs) inevitably acquire harmful information during training on massive datasets. LLM unlearning aims to eliminate the influence of such harmful information while maintaining the model's overall performance. Existing unlearning methods, represented by gradient ascent-based approaches, primarily focus on forgetting target data while overlooking the crucial impact of logically related knowledge on the effectiveness of unlearning. In this paper, through both theoretical and experimental analyses, we first demonstrate that a key reason for the suboptimal unlearning performance is that models can reconstruct the target content through reasoning with logically related knowledge. To address this issue, we propose Unlearning Improvement via Parameter Extrapolation (UIPE), a method that removes knowledge highly correlated with the forgetting targets. Experimental results show that UIPE significantly enhances the performance of various mainstream LLM unlearning methods on the TOFU benchmark.
SYKI-SVC: Advancing Singing Voice Conversion with Post-Processing Innovations and an Open-Source Professional Testset
Jan 06, 2025Singing voice conversion aims to transform a source singing voice into that of a target singer while preserving the original lyrics, melody, and various vocal techniques. In this paper, we propose a high-fidelity singing voice conversion system. Our system builds upon the SVCC T02 framework and consists of three key components: a feature extractor, a voice converter, and a post-processor. The feature extractor utilizes the ContentVec and Whisper models to derive F0 contours and extract speaker-independent linguistic features from the input singing voice. The voice converter then integrates the extracted timbre, F0, and linguistic content to synthesize the target speaker's waveform. The post-processor augments high-frequency information directly from the source through simple and effective signal processing to enhance audio quality. Due to the lack of a standardized professional dataset for evaluating expressive singing conversion systems, we have created and made publicly available a specialized test set. Comparative evaluations demonstrate that our system achieves a remarkably high level of naturalness, and further analysis confirms the efficacy of our proposed system design.
Wearable intelligent throat enables natural speech in stroke patients with dysarthria
Nov 28, 2024



Wearable silent speech systems hold significant potential for restoring communication in patients with speech impairments. However, seamless, coherent speech remains elusive, and clinical efficacy is still unproven. Here, we present an AI-driven intelligent throat (IT) system that integrates throat muscle vibrations and carotid pulse signal sensors with large language model (LLM) processing to enable fluent, emotionally expressive communication. The system utilizes ultrasensitive textile strain sensors to capture high-quality signals from the neck area and supports token-level processing for real-time, continuous speech decoding, enabling seamless, delay-free communication. In tests with five stroke patients with dysarthria, IT's LLM agents intelligently corrected token errors and enriched sentence-level emotional and logical coherence, achieving low error rates (4.2% word error rate, 2.9% sentence error rate) and a 55% increase in user satisfaction. This work establishes a portable, intuitive communication platform for patients with dysarthria with the potential to be applied broadly across different neurological conditions and in multi-language support systems.
FGCL: Fine-grained Contrastive Learning For Mandarin Stuttering Event Detection
Oct 08, 2024
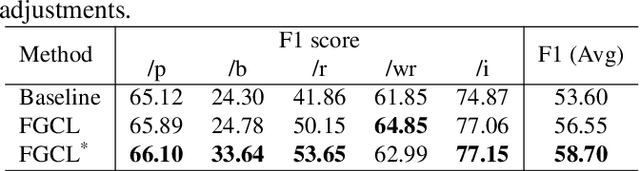
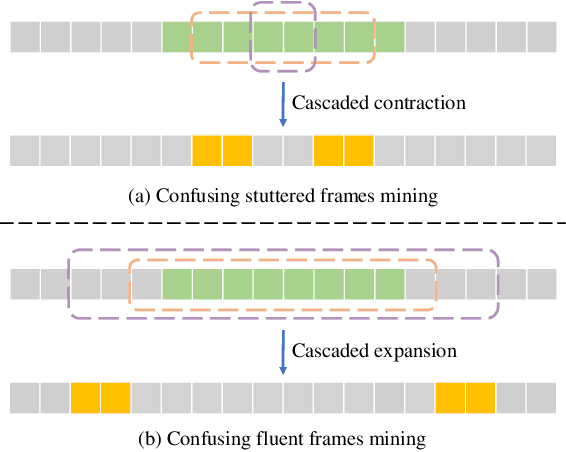
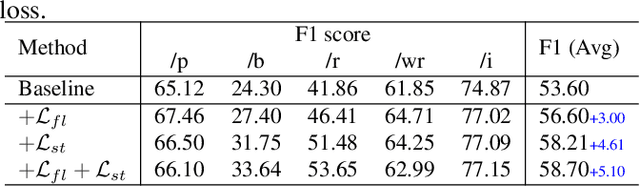
This paper presents the T031 team's approach to the StutteringSpeech Challenge in SLT2024. Mandarin Stuttering Event Detection (MSED) aims to detect instances of stuttering events in Mandarin speech. We propose a detailed acoustic analysis method to improve the accuracy of stutter detection by capturing subtle nuances that previous Stuttering Event Detection (SED) techniques have overlooked. To this end, we introduce the Fine-Grained Contrastive Learning (FGCL) framework for MSED. Specifically, we model the frame-level probabilities of stuttering events and introduce a mining algorithm to identify both easy and confusing frames. Then, we propose a stutter contrast loss to enhance the distinction between stuttered and fluent speech frames, thereby improving the discriminative capability of stuttered feature embeddings. Extensive evaluations on English and Mandarin datasets demonstrate the effectiveness of FGCL, achieving a significant increase of over 5.0% in F1 score on Mandarin data.
Medical Image Segmentation via Single-Source Domain Generalization with Random Amplitude Spectrum Synthesis
Sep 07, 2024



The field of medical image segmentation is challenged by domain generalization (DG) due to domain shifts in clinical datasets. The DG challenge is exacerbated by the scarcity of medical data and privacy concerns. Traditional single-source domain generalization (SSDG) methods primarily rely on stacking data augmentation techniques to minimize domain discrepancies. In this paper, we propose Random Amplitude Spectrum Synthesis (RASS) as a training augmentation for medical images. RASS enhances model generalization by simulating distribution changes from a frequency perspective. This strategy introduces variability by applying amplitude-dependent perturbations to ensure broad coverage of potential domain variations. Furthermore, we propose random mask shuffle and reconstruction components, which can enhance the ability of the backbone to process structural information and increase resilience intra- and cross-domain changes. The proposed Random Amplitude Spectrum Synthesis for Single-Source Domain Generalization (RAS^4DG) is validated on 3D fetal brain images and 2D fundus photography, and achieves an improved DG segmentation performance compared to other SSDG models.