 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-on-Graph: Iterative Programmatic Reasoning via Large Language Models on Knowledge Graphs
Jun 02, 2026Knowledge Graphs (KGs) are widely used to mitigate the limitations of Large Language Models (LLMs), such as outdated knowledge and hallucinations. Existing LLM-KG integration frameworks typically rely on predefined operators to retrieve factual knowledge from KGs and inject it into prompts for answer generation. This paradigm faces two critical bottlenecks: 1) Inflexibility: The predefined operators are limited in scope and thus lack sufficient compositional expressiveness to fully capture the complex semantics required by KG questions. 2) Unscalability: Direct injection of factual knowledge into prompts limits scalability in handling large-scale factual knowledge. To address these two bottlenecks, we propose Code-on-Graph (CoG), a programmatic reasoning framework for LLM-KG integration. Specifically, given the factual knowledge retrieved at each reasoning step, CoG first identifies the corresponding KG schemas and represents these schemas as Python classes, which serve as abstract interfaces to the retrieved facts. It then generates executable code grounded in these classes, with the retrieved facts instantiated as objects of the corresponding classes during execution. This design enables flexible code-based reasoning while avoiding the direct injection of large-scale factual knowledge into prompts. Experiments on WebQSP, CWQ, and GrailQA demonstrate that CoG outperforms prior state-of-the-art models by up to 10.5%.
Efficient Item ID Generation for Large-Scale LLM-based Recommendation
Sep 03, 2025Integrating product catalogs and user behavior into LLMs can enhance recommendations with broad world knowledge, but the scale of real-world item catalogs, often containing millions of discrete item identifiers (Item IDs), poses a significant challenge. This contrasts with the smaller, tokenized text vocabularies typically used in LLMs. The predominant view within the LLM-based recommendation literature is that it is infeasible to treat item ids as a first class citizen in the LLM and instead some sort of tokenization of an item into multiple tokens is required. However, this creates a key practical bottleneck in serving these models for real-time low-latency applications. Our paper challenges this predominant practice and integrates item ids as first class citizens into the LLM. We provide simple, yet highly effective, novel training and inference modifications that enable single-token representations of items and single-step decoding. Our method shows improvements in recommendation quality (Recall and NDCG) over existing techniques on the Amazon shopping datasets while significantly improving inference efficiency by 5x-14x. Our work offers an efficiency perspective distinct from that of other popular approaches within LLM-based recommendation, potentially inspiring further research and opening up a new direction for integrating IDs into LLMs. Our code is available here https://drive.google.com/file/d/1cUMj37rV0Z1bCWMdhQ6i4q4eTRQLURtC
Generative Modeling of Adversarial Lane-Change Scenario
Mar 15, 2025



Decision-making in long-tail scenarios is crucial to autonomous driving development, with realistic and challenging simulations playing a pivotal role in testing safety-critical situations. However, the current open-source datasets do not systematically include long-tail distributed scenario data, making acquiring such scenarios a formidable task. To address this problem, a data mining framework is proposed, which performs in-depth analysis on two widely-used datasets, NGSIM and INTERACTION, to pinpoint data with hazardous behavioral traits, aiming to bridge the gap in these overlooked scenarios. The approach utilizes Generative Adversarial Imitation Learning (GAIL) based on an enhanced Proximal Policy Optimization (PPO) model, integrated with the vehicle's environmental analysis, to iteratively refine and represent the newly generated vehicle trajectory. Innovatively, the solution optimizes the generation of adversarial scenario data from the perspectives of sensitivity and reasonable adversarial. It is demonstrated through experiments that, compared to the unfiltered data and baseline models, the approach exhibits more adversarial yet natural behavior regarding collision rate, acceleration, and lane changes, thereby validating its suitability for generating scenario data and providing constructive insights for the development of future scenarios and subsequent decision training.
REGEN: A Dataset and Benchmarks with Natural Language Critiques and Narratives
Mar 14, 2025This paper introduces a novel dataset REGEN (Reviews Enhanced with GEnerative Narratives), designed to benchmark the conversational capabilities of recommender Large Language Models (LLMs), addressing the limitations of existing datasets that primarily focus on sequential item prediction. REGEN extends the Amazon Product Reviews dataset by inpainting two key natural language features: (1) user critiques, representing user "steering" queries that lead to the selection of a subsequent item, and (2) narratives, rich textual outputs associated with each recommended item taking into account prior context. The narratives include product endorsements, purchase explanations, and summaries of user preferences. Further, we establish an end-to-end modeling benchmark for the task of conversational recommendation, where models are trained to generate both recommendations and corresponding narratives conditioned on user history (items and critiques). For this joint task, we introduce a modeling framework LUMEN (LLM-based Unified Multi-task Model with Critiques, Recommendations, and Narratives) which uses an LLM as a backbone for critiquing, retrieval and generation. We also evaluate the dataset's quality using standard auto-rating techniques and benchmark it by training both traditional and LLM-based recommender models. Our results demonstrate that incorporating critiques enhances recommendation quality by enabling the recommender to learn language understanding and integrate it with recommendation signals. Furthermore, LLMs trained on our dataset effectively generate both recommendations and contextual narratives, achieving performance comparable to state-of-the-art recommenders and language models.
Diff4Steer: Steerable Diffusion Prior for Generative Music Retrieval with Semantic Guidance
Dec 06, 2024Modern music retrieval systems often rely on fixed representations of user preferences, limiting their ability to capture users' diverse and uncertain retrieval needs. To address this limitation, we introduce Diff4Steer, a novel generative retrieval framework that employs lightweight diffusion models to synthesize diverse seed embeddings from user queries that represent potential directions for music exploration. Unlike deterministic methods that map user query to a single point in embedding space, Diff4Steer provides a statistical prior on the target modality (audio) for retrieval, effectively capturing the uncertainty and multi-faceted nature of user preferences. Furthermore, Diff4Steer can be steered by image or text inputs, enabling more flexible and controllable music discovery combined with nearest neighbor search. Our framework outperforms deterministic regression methods and LLM-based generative retrieval baseline in terms of retrieval and ranking metrics, demonstrating its effectiveness in capturing user preferences, leading to more diverse and relevant recommendations. Listening examples are available at tinyurl.com/diff4steer.
Tell What You Hear From What You See -- Video to Audio Generation Through Text
Nov 08, 2024



The content of visual and audio scenes is multi-faceted such that a video can be paired with various audio and vice-versa. Thereby, in video-to-audio generation task, it is imperative to introduce steering approaches for controlling the generated audio. While Video-to-Audio generation is a well-established generative task, existing methods lack such controllability. In this work, we propose VATT, a multi-modal generative framework that takes a video and an optional text prompt as input, and generates audio and optional textual description of the audio. Such a framework has two advantages: i) Video-to-Audio generation process can be refined and controlled via text which complements the context of visual information, and ii) The model can suggest what audio to generate for the video by generating audio captions. VATT consists of two key modules: VATT Converter, a LLM that is fine-tuned for instructions and includes a projection layer that maps video features to the LLM vector space; and VATT Audio, a transformer that generates audio tokens from visual frames and from optional text prompt using iterative parallel decoding. The audio tokens are converted to a waveform by pretrained neural codec. Experiments show that when VATT is compared to existing video-to-audio generation methods in objective metrics, it achieves competitive performance when the audio caption is not provided. When the audio caption is provided as a prompt, VATT achieves even more refined performance (lowest KLD score of 1.41). Furthermore, subjective studies show that VATT Audio has been chosen as preferred generated audio than audio generated by existing methods. VATT enables controllable video-to-audio generation through text as well as suggesting text prompts for videos through audio captions, unlocking novel applications such as text-guided video-to-audio generation and video-to-audio captioning.
Beyond Retrieval: Generating Narratives in Conversational Recommender Systems
Oct 22, 2024
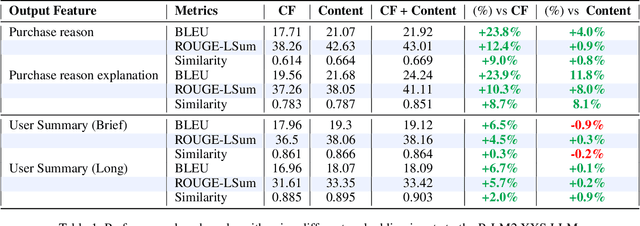


The recent advances in Large Language Model's generation and reasoning capabilities present an opportunity to develop truly conversational recommendation systems. However, effectively integrating recommender system knowledge into LLMs for natural language generation which is tailored towards recommendation tasks remains a challenge. This paper addresses this challenge by making two key contributions. First, we introduce a new dataset (REGEN) for natural language generation tasks in conversational recommendations. REGEN (Reviews Enhanced with GEnerative Narratives) extends the Amazon Product Reviews dataset with rich user narratives, including personalized explanations of product preferences, product endorsements for recommended items, and summaries of user purchase history. REGEN is made publicly available to facilitate further research. Furthermore, we establish benchmarks using well-known generative metrics, and perform an automated evaluation of the new dataset using a rater LLM. Second, the paper introduces a fusion architecture (CF model with an LLM) which serves as a baseline for REGEN. And to the best of our knowledge, represents the first attempt to analyze the capabilities of LLMs in understanding recommender signals and generating rich narratives. We demonstrate that LLMs can effectively learn from simple fusion architectures utilizing interaction-based CF embeddings, and this can be further enhanced using the metadata and personalization data associated with items. Our experiments show that combining CF and content embeddings leads to improvements of 4-12% in key language metrics compared to using either type of embedding individually. We also provide an analysis to interpret how CF and content embeddings contribute to this new generative task.
UniMuMo: Unified Text, Music and Motion Generation
Oct 06, 2024



We introduce UniMuMo, a unified multimodal model capable of taking arbitrary text, music, and motion data as input conditions to generate outputs across all three modalities. To address the lack of time-synchronized data, we align unpaired music and motion data based on rhythmic patterns to leverage existing large-scale music-only and motion-only datasets. By converting music, motion, and text into token-based representation, our model bridges these modalities through a unified encoder-decoder transformer architecture. To support multiple generation tasks within a single framework, we introduce several architectural improvements. We propose encoding motion with a music codebook, mapping motion into the same feature space as music. We introduce a music-motion parallel generation scheme that unifies all music and motion generation tasks into a single transformer decoder architecture with a single training task of music-motion joint generation. Moreover, the model is designed by fine-tuning existing pre-trained single-modality models, significantly reducing computational demands. Extensive experiments demonstrate that UniMuMo achieves competitive results on all unidirectional generation benchmarks across music, motion, and text modalities. Quantitative results are available in the \href{https://hanyangclarence.github.io/unimumo_demo/}{project page}.
From Vision to Audio and Beyond: A Unified Model for Audio-Visual Representation and Generation
Sep 27, 2024



Video encompasses both visual and auditory data, creating a perceptually rich experience where these two modalities complement each other. As such, videos are a valuable type of media for the investigation of the interplay between audio and visual elements. Previous studies of audio-visual modalities primarily focused on either audio-visual representation learning or generative modeling of a modality conditioned on the other, creating a disconnect between these two branches. A unified framework that learns representation and generates modalities has not been developed yet. In this work, we introduce a novel framework called Vision to Audio and Beyond (VAB) to bridge the gap between audio-visual representation learning and vision-to-audio generation. The key approach of VAB is that rather than working with raw video frames and audio data, VAB performs representation learning and generative modeling within latent spaces. In particular, VAB uses a pre-trained audio tokenizer and an image encoder to obtain audio tokens and visual features, respectively. It then performs the pre-training task of visual-conditioned masked audio token prediction. This training strategy enables the model to engage in contextual learning and simultaneous video-to-audio generation. After the pre-training phase, VAB employs the iterative-decoding approach to rapidly generate audio tokens conditioned on visual features. Since VAB is a unified model, its backbone can be fine-tuned for various audio-visual downstream tasks. Our experiments showcase the efficiency of VAB in producing high-quality audio from video, and its capability to acquire semantic audio-visual features, leading to competitive results in audio-visual retrieval and classification.
Medical Image Segmentation via Single-Source Domain Generalization with Random Amplitude Spectrum Synthesis
Sep 07, 2024



The field of medical image segmentation is challenged by domain generalization (DG) due to domain shifts in clinical datasets. The DG challenge is exacerbated by the scarcity of medical data and privacy concerns. Traditional single-source domain generalization (SSDG) methods primarily rely on stacking data augmentation techniques to minimize domain discrepancies. In this paper, we propose Random Amplitude Spectrum Synthesis (RASS) as a training augmentation for medical images. RASS enhances model generalization by simulating distribution changes from a frequency perspective. This strategy introduces variability by applying amplitude-dependent perturbations to ensure broad coverage of potential domain variations. Furthermore, we propose random mask shuffle and reconstruction components, which can enhance the ability of the backbone to process structural information and increase resilience intra- and cross-domain changes. The proposed Random Amplitude Spectrum Synthesis for Single-Source Domain Generalization (RAS^4DG) is validated on 3D fetal brain images and 2D fundus photography, and achieves an improved DG segmentation performance compared to other SSDG models.