 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Item ID Generation for Large-Scale LLM-based Recommendation
Sep 03, 2025Integrating product catalogs and user behavior into LLMs can enhance recommendations with broad world knowledge, but the scale of real-world item catalogs, often containing millions of discrete item identifiers (Item IDs), poses a significant challenge. This contrasts with the smaller, tokenized text vocabularies typically used in LLMs. The predominant view within the LLM-based recommendation literature is that it is infeasible to treat item ids as a first class citizen in the LLM and instead some sort of tokenization of an item into multiple tokens is required. However, this creates a key practical bottleneck in serving these models for real-time low-latency applications. Our paper challenges this predominant practice and integrates item ids as first class citizens into the LLM. We provide simple, yet highly effective, novel training and inference modifications that enable single-token representations of items and single-step decoding. Our method shows improvements in recommendation quality (Recall and NDCG) over existing techniques on the Amazon shopping datasets while significantly improving inference efficiency by 5x-14x. Our work offers an efficiency perspective distinct from that of other popular approaches within LLM-based recommendation, potentially inspiring further research and opening up a new direction for integrating IDs into LLMs. Our code is available here https://drive.google.com/file/d/1cUMj37rV0Z1bCWMdhQ6i4q4eTRQLURtC
REGEN: A Dataset and Benchmarks with Natural Language Critiques and Narratives
Mar 14, 2025This paper introduces a novel dataset REGEN (Reviews Enhanced with GEnerative Narratives), designed to benchmark the conversational capabilities of recommender Large Language Models (LLMs), addressing the limitations of existing datasets that primarily focus on sequential item prediction. REGEN extends the Amazon Product Reviews dataset by inpainting two key natural language features: (1) user critiques, representing user "steering" queries that lead to the selection of a subsequent item, and (2) narratives, rich textual outputs associated with each recommended item taking into account prior context. The narratives include product endorsements, purchase explanations, and summaries of user preferences. Further, we establish an end-to-end modeling benchmark for the task of conversational recommendation, where models are trained to generate both recommendations and corresponding narratives conditioned on user history (items and critiques). For this joint task, we introduce a modeling framework LUMEN (LLM-based Unified Multi-task Model with Critiques, Recommendations, and Narratives) which uses an LLM as a backbone for critiquing, retrieval and generation. We also evaluate the dataset's quality using standard auto-rating techniques and benchmark it by training both traditional and LLM-based recommender models. Our results demonstrate that incorporating critiques enhances recommendation quality by enabling the recommender to learn language understanding and integrate it with recommendation signals. Furthermore, LLMs trained on our dataset effectively generate both recommendations and contextual narratives, achieving performance comparable to state-of-the-art recommenders and language models.
Minimizing Live Experiments in Recommender Systems: User Simulation to Evaluate Preference Elicitation Policies
Sep 26, 2024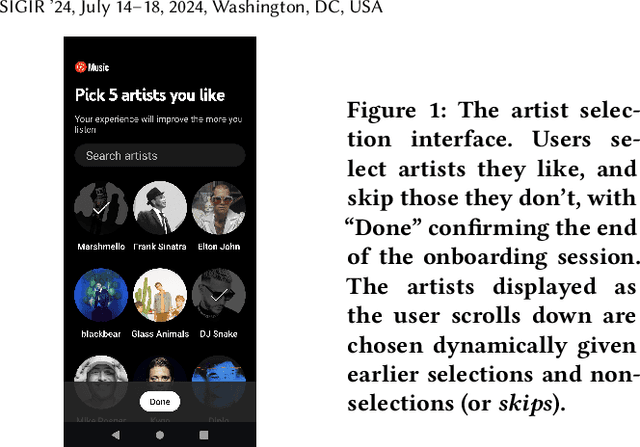
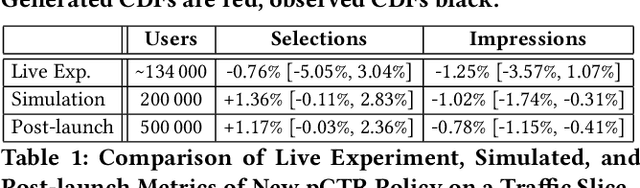
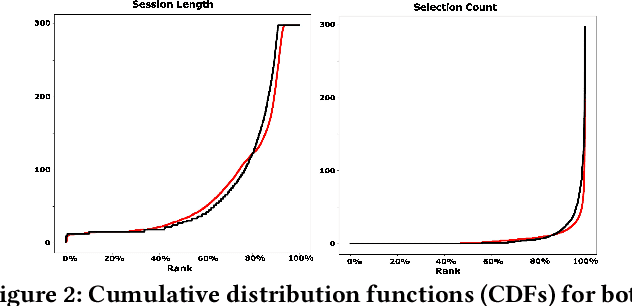
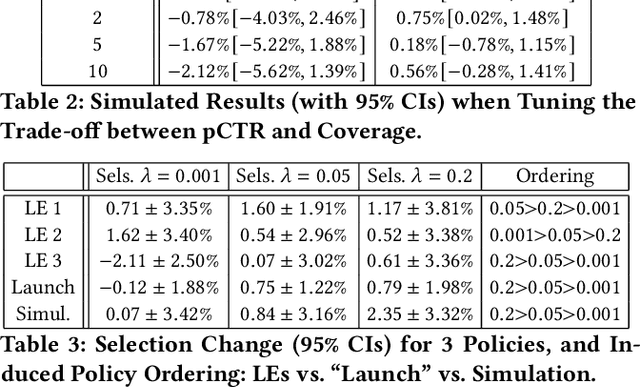
Evaluation of policies in recommender systems typically involves A/B testing using live experiments on real users to assess a new policy's impact on relevant metrics. This ``gold standard'' comes at a high cost, however, in terms of cycle time, user cost, and potential user retention. In developing policies for ``onboarding'' new users, these costs can be especially problematic, since on-boarding occurs only once. In this work, we describe a simulation methodology used to augment (and reduce) the use of live experiments. We illustrate its deployment for the evaluation of ``preference elicitation'' algorithms used to onboard new users of the YouTube Music platform. By developing counterfactually robust user behavior models, and a simulation service that couples such models with production infrastructure, we are able to test new algorithms in a way that reliably predicts their performance on key metrics when deployed live. We describe our domain, our simulation models and platform, results of experiments and deployment, and suggest future steps needed to further realistic simulation as a powerful complement to live experiments.
FLARE: Fusing Language Models and Collaborative Architectures for Recommender Enhancement
Sep 18, 2024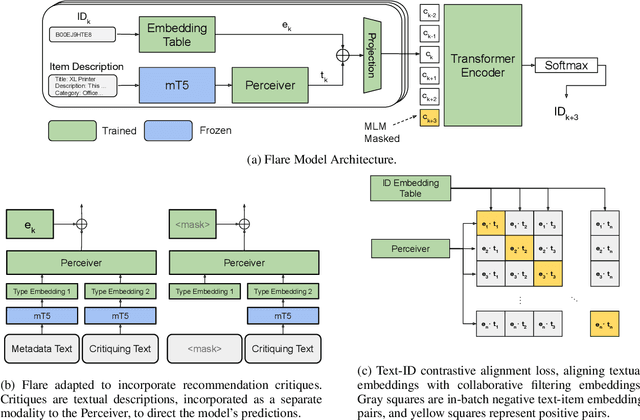


Hybrid recommender systems, combining item IDs and textual descriptions, offer potential for improved accuracy. However, previous work has largely focused on smaller datasets and model architectures. This paper introduces Flare (Fusing Language models and collaborative Architectures for Recommender Enhancement), a novel hybrid recommender that integrates a language model (mT5) with a collaborative filtering model (Bert4Rec) using a Perceiver network. This architecture allows Flare to effectively combine collaborative and content information for enhanced recommendations. We conduct a two-stage evaluation, first assessing Flare's performance against established baselines on smaller datasets, where it demonstrates competitive accuracy. Subsequently, we evaluate Flare on a larger, more realistic dataset with a significantly larger item vocabulary, introducing new baselines for this setting. Finally, we showcase Flare's inherent ability to support critiquing, enabling users to provide feedback and refine recommendations. We further leverage critiquing as an evaluation method to assess the model's language understanding and its transferability to the recommendation task.