 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing Live Experiments in Recommender Systems: User Simulation to Evaluate Preference Elicitation Policies
Sep 26, 2024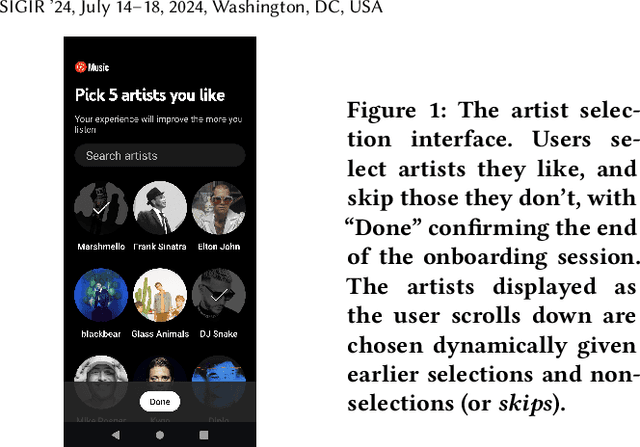
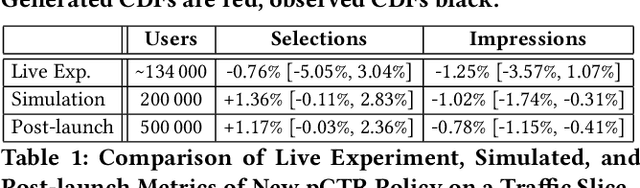
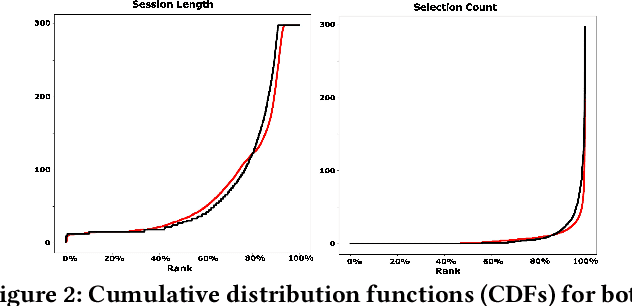
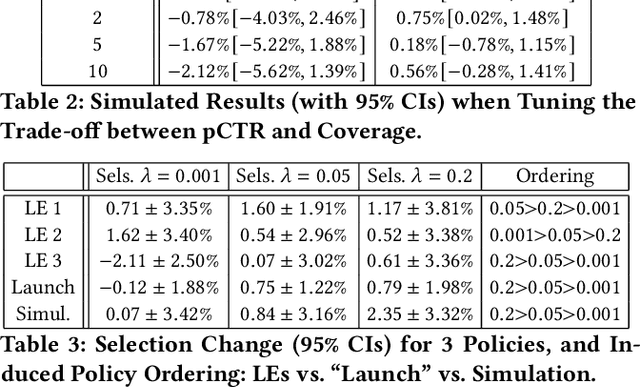
Evaluation of policies in recommender systems typically involves A/B testing using live experiments on real users to assess a new policy's impact on relevant metrics. This ``gold standard'' comes at a high cost, however, in terms of cycle time, user cost, and potential user retention. In developing policies for ``onboarding'' new users, these costs can be especially problematic, since on-boarding occurs only once. In this work, we describe a simulation methodology used to augment (and reduce) the use of live experiments. We illustrate its deployment for the evaluation of ``preference elicitation'' algorithms used to onboard new users of the YouTube Music platform. By developing counterfactually robust user behavior models, and a simulation service that couples such models with production infrastructure, we are able to test new algorithms in a way that reliably predicts their performance on key metrics when deployed live. We describe our domain, our simulation models and platform, results of experiments and deployment, and suggest future steps needed to further realistic simulation as a powerful complement to live experiments.
Embedding-Aligned Language Models
May 24, 2024We propose a novel approach for training large language models (LLMs) to adhere to objectives defined within a latent embedding space. Our method leverages reinforcement learning (RL), treating a pre-trained LLM as an environment. Our embedding-aligned guided language (EAGLE) agent is trained to iteratively steer the LLM's generation towards optimal regions of the latent embedding space, w.r.t. some predefined criterion. We demonstrate the effectiveness of the EAGLE agent using the MovieLens 25M dataset to surface content gaps that satisfy latent user demand. We also demonstrate the benefit of using an optimal design of a state-dependent action set to improve EAGLE's efficiency. Our work paves the way for controlled and grounded text generation using LLMs, ensuring consistency with domain-specific knowledge and data representations.
Factual and Personalized Recommendations using Language Models and Reinforcement Learning
Oct 09, 2023



Recommender systems (RSs) play a central role in connecting users to content, products, and services, matching candidate items to users based on their preferences. While traditional RSs rely on implicit user feedback signals, conversational RSs interact with users in natural language. In this work, we develop a comPelling, Precise, Personalized, Preference-relevant language model (P4LM) that recommends items to users while putting emphasis on explaining item characteristics and their relevance. P4LM uses the embedding space representation of a user's preferences to generate compelling responses that are factually-grounded and relevant w.r.t. the user's preferences. Moreover, we develop a joint reward function that measures precision, appeal, and personalization, which we use as AI-based feedback in a reinforcement learning-based language model framework. Using the MovieLens 25M dataset, we demonstrate that P4LM delivers compelling, personalized movie narratives to users.
Demystifying Embedding Spaces using Large Language Models
Oct 06, 2023Embeddings have become a pivotal means to represent complex, multi-faceted information about entities, concepts, and relationships in a condensed and useful format. Nevertheless, they often preclude direct interpretation. While downstream tasks make use of these compressed representations, meaningful interpretation usually requires visualization using dimensionality reduction or specialized machine learning interpretability methods. This paper addresses the challenge of making such embeddings more interpretable and broadly useful, by employing Large Language Models (LLMs) to directly interact with embeddings -- transforming abstract vectors into understandable narratives. By injecting embeddings into LLMs, we enable querying and exploration of complex embedding data. We demonstrate our approach on a variety of diverse tasks, including: enhancing concept activation vectors (CAVs), communicating novel embedded entities, and decoding user preferences in recommender systems. Our work couples the immense information potential of embeddings with the interpretative power of LLMs.
RecSim NG: Toward Principled Uncertainty Modeling for Recommender Ecosystems
Mar 14, 2021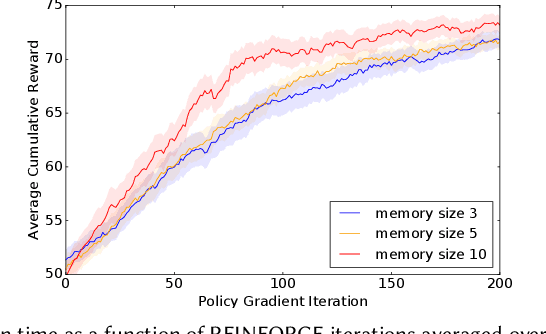
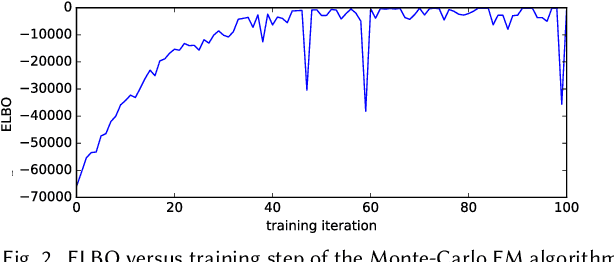
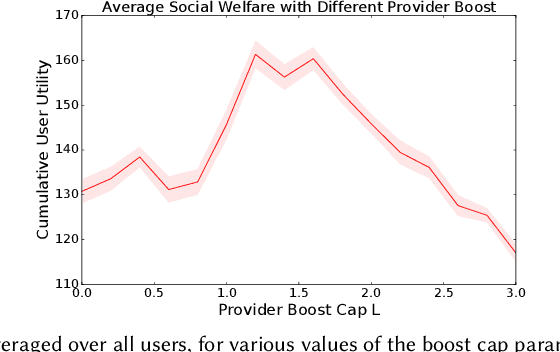
The development of recommender systems that optimize multi-turn interaction with users, and model the interactions of different agents (e.g., users, content providers, vendors) in the recommender ecosystem have drawn increasing attention in recent years. Developing and training models and algorithms for such recommenders can be especially difficult using static datasets, which often fail to offer the types of counterfactual predictions needed to evaluate policies over extended horizons. To address this, we develop RecSim NG, a probabilistic platform for the simulation of multi-agent recommender systems. RecSim NG is a scalable, modular, differentiable simulator implemented in Edward2 and TensorFlow. It offers: a powerful, general probabilistic programming language for agent-behavior specification; tools for probabilistic inference and latent-variable model learning, backed by automatic differentiation and tracing; and a TensorFlow-based runtime for running simulations on accelerated hardware. We describe RecSim NG and illustrate how it can be used to create transparent, configurable, end-to-end models of a recommender ecosystem, complemented by a small set of simple use cases that demonstrate how RecSim NG can help both researchers and practitioners easily develop and train novel algorithms for recommender systems.
Differentiable Meta-Learning in Contextual Bandits
Jun 09, 2020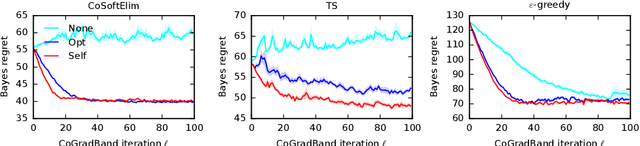
We study a contextual bandit setting where the learning agent has access to sampled bandit instances from an unknown prior distribution $\mathcal{P}$. The goal of the agent is to achieve high reward on average over the instances drawn from $\mathcal{P}$. This setting is of a particular importance because it formalizes the offline optimization of bandit policies, to perform well on average over anticipated bandit instances. The main idea in our work is to optimize differentiable bandit policies by policy gradients. We derive reward gradients that reflect the structure of our problem, and propose contextual policies that are parameterized in a differentiable way and have low regret. Our algorithmic and theoretical contributions are supported by extensive experiments that show the importance of baseline subtraction, learned biases, and the practicality of our approach on a range of classification tasks.
Differentiable Bandit Exploration
Feb 17, 2020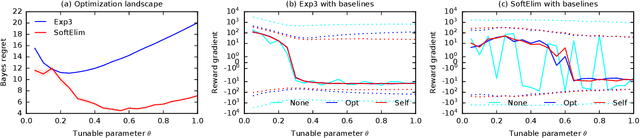
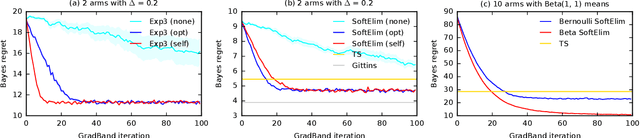
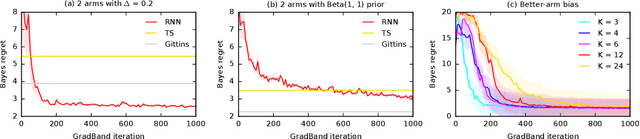
We learn bandit policies that maximize the average reward over bandit instances drawn from an unknown distribution $\mathcal{P}$, from a sample from $\mathcal{P}$. Our approach is an instance of meta-learning and its appeal is that the properties of $\mathcal{P}$ can be exploited without restricting it. We parameterize our policies in a differentiable way and optimize them by policy gradients - an approach that is easy to implement and pleasantly general. Then the challenge is to design effective gradient estimators and good policy classes. To make policy gradients practical, we introduce novel variance reduction techniques. We experiment with various bandit policy classes, including neural networks and a novel soft-elimination policy. The latter has regret guarantees and is a natural starting point for our optimization. Our experiments highlight the versatility of our approach. We also observe that neural network policies can learn implicit biases, which are only expressed through sampled bandit instances during training.
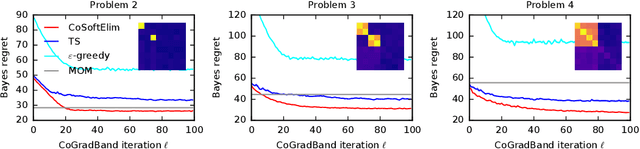
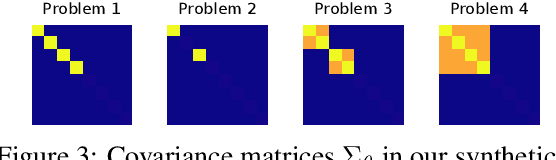
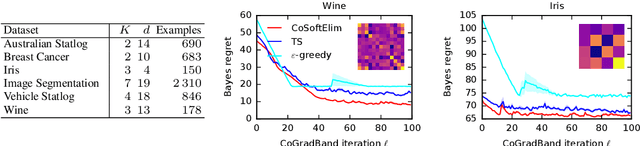
Empirical Bayes Regret Minimization
Apr 04, 2019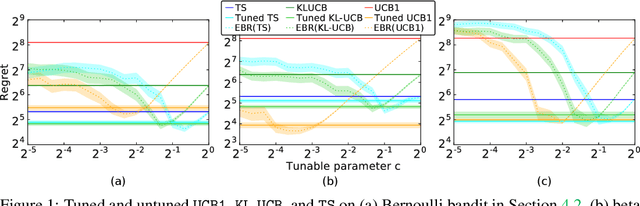

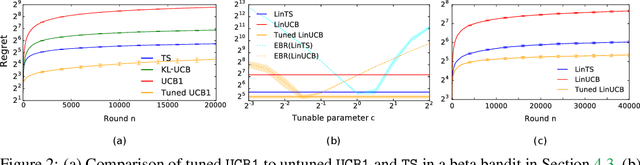
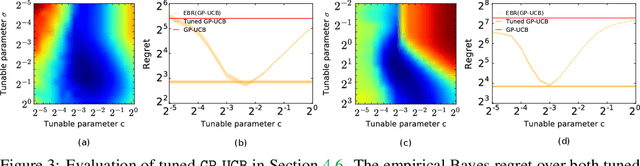
The prevalent approach to bandit algorithm design is to have a low-regret algorithm by design. While celebrated, this approach is often conservative because it ignores many intricate properties of actual problem instances. In this work, we pioneer the idea of minimizing an empirical approximation to the Bayes regret, the expected regret with respect to a distribution over problems. This approach can be viewed as an instance of learning-to-learn, it is conceptually straightforward, and easy to implement. We conduct a comprehensive empirical study of empirical Bayes regret minimization in a wide range of bandit problems, from Bernoulli bandits to structured problems, such as generalized linear and Gaussian process bandits. We report significant improvements over state-of-the-art bandit algorithms, often by an order of magnitude, by simply optimizing over a sample from the distribution.