 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormalize, Don't Optimize: The Heuristic Trap in LLM-Generated Combinatorial Solvers
May 12, 2026Large Language Models (LLMs) struggle to solve complex combinatorial problems through direct reasoning, so recent neuro-symbolic systems increasingly use them to synthesize executable solvers. A central design question is how the LLM should represent the solver, and whether it should also attempt to optimize search. We introduce CP-SynC-XL, a benchmark of 100 combinatorial problems (4,577 instances), and evaluate three solver-construction paradigms: native algorithmic search (Python), constraint modeling through a Python solver API (Python + OR-Tools), and declarative constraint modeling (MiniZinc + OR-Tools). We find a consistent representational divergence: Python + OR-Tools attains the highest correctness across LLMs, while MiniZinc + OR-Tools has lower absolute coverage despite using the same OR-Tools back-end. Native Python is the most likely to return a schema-valid solution that fails verification, whereas solver-backed paths preserve higher conditional fidelity. On the heuristic axis, prompting for search optimization yields only small median speed-ups (1.03-1.12x) and a strongly bimodal effect: many instances slow down, and correctness drops sharply on a long tail of problems. A paired code-level audit traces these regressions to a recurring heuristic trap. Under an efficiency-oriented prompt, the LLM may replace complete search with local approximations (Python), inject unverified bounds (Python + OR-Tools), or add redundant declarative machinery that overwhelms or over-constrains the model (MiniZinc + OR-Tools). These findings support a conservative design principle for LLM-generated combinatorial solvers: use the LLM primarily to formalize variables, constraints, and objectives for verified solvers, and separately check any LLM-authored search optimization before use.
Multi-Objective Preference Optimization: Improving Human Alignment of Generative Models
May 16, 2025Post-training of LLMs with RLHF, and subsequently preference optimization algorithms such as DPO, IPO, etc., made a big difference in improving human alignment. However, all such techniques can only work with a single (human) objective. In practice, human users have multiple objectives, such as helpfulness and harmlessness, and there is no natural way to aggregate them into a single objective. In this paper, we address the multi-objective preference-alignment problem, where a policy must optimize several, potentially conflicting, objectives. We introduce the Multi-Objective Preference Optimization (MOPO) algorithm, which frames alignment as a constrained KL-regularized optimization: the primary objective is maximized while secondary objectives are lower-bounded by tunable safety thresholds. Unlike prior work, MOPO operates directly on pairwise preference data, requires no point-wise reward assumption, and avoids heuristic prompt-context engineering. The method recovers policies on the Pareto front whenever the front is attainable; practically, it reduces to simple closed-form iterative updates suitable for large-scale training. On synthetic benchmarks with diverse canonical preference structures, we show that MOPO approximates the Pareto front. When fine-tuning a 1.3B-parameter language model on real-world human-preference datasets, MOPO attains higher rewards and yields policies that Pareto-dominate baselines; ablation studies confirm optimization stability and robustness to hyperparameters.
Distributionally Robust Direct Preference Optimization
Feb 04, 2025



A major challenge in aligning large language models (LLMs) with human preferences is the issue of distribution shift. LLM alignment algorithms rely on static preference datasets, assuming that they accurately represent real-world user preferences. However, user preferences vary significantly across geographical regions, demographics, linguistic patterns, and evolving cultural trends. This preference distribution shift leads to catastrophic alignment failures in many real-world applications. We address this problem using the principled framework of distributionally robust optimization, and develop two novel distributionally robust direct preference optimization (DPO) algorithms, namely, Wasserstein DPO (WDPO) and Kullback-Leibler DPO (KLDPO). We characterize the sample complexity of learning the optimal policy parameters for WDPO and KLDPO. Moreover, we propose scalable gradient descent-style learning algorithms by developing suitable approximations for the challenging minimax loss functions of WDPO and KLDPO. Our empirical experiments demonstrate the superior performance of WDPO and KLDPO in substantially improving the alignment when there is a preference distribution shift.
Best Policy Learning from Trajectory Preference Feedback
Jan 31, 2025



We address the problem of best policy identification in preference-based reinforcement learning (PbRL), where learning occurs from noisy binary preferences over trajectory pairs rather than explicit numerical rewards. This approach is useful for post-training optimization of generative AI models during multi-turn user interactions, where preference feedback is more robust than handcrafted reward models. In this setting, learning is driven by both an offline preference dataset -- collected from a rater of unknown 'competence' -- and online data collected with pure exploration. Since offline datasets may exhibit out-of-distribution (OOD) biases, principled online data collection is necessary. To address this, we propose Posterior Sampling for Preference Learning ($\mathsf{PSPL}$), a novel algorithm inspired by Top-Two Thompson Sampling, that maintains independent posteriors over the true reward model and transition dynamics. We provide the first theoretical guarantees for PbRL in this setting, establishing an upper bound on the simple Bayesian regret of $\mathsf{PSPL}$. Since the exact algorithm can be computationally impractical, we also provide an approximate version that outperforms existing baselines.
Focus-N-Fix: Region-Aware Fine-Tuning for Text-to-Image Generation
Jan 11, 2025

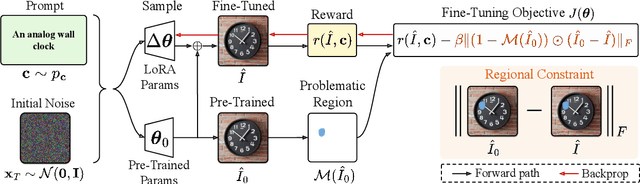
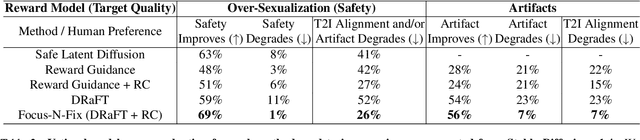
Text-to-image (T2I) generation has made significant advances in recent years, but challenges still remain in the generation of perceptual artifacts, misalignment with complex prompts, and safety. The prevailing approach to address these issues involves collecting human feedback on generated images, training reward models to estimate human feedback, and then fine-tuning T2I models based on the reward models to align them with human preferences. However, while existing reward fine-tuning methods can produce images with higher rewards, they may change model behavior in unexpected ways. For example, fine-tuning for one quality aspect (e.g., safety) may degrade other aspects (e.g., prompt alignment), or may lead to reward hacking (e.g., finding a way to increase rewards without having the intended effect). In this paper, we propose Focus-N-Fix, a region-aware fine-tuning method that trains models to correct only previously problematic image regions. The resulting fine-tuned model generates images with the same high-level structure as the original model but shows significant improvements in regions where the original model was deficient in safety (over-sexualization and violence), plausibility, or other criteria. Our experiments demonstrate that Focus-N-Fix improves these localized quality aspects with little or no degradation to others and typically imperceptible changes in the rest of the image. Disclaimer: This paper contains images that may be overly sexual, violent, offensive, or harmful.
Personalized and Sequential Text-to-Image Generation
Dec 10, 2024



We address the problem of personalized, interactive text-to-image (T2I) generation, designing a reinforcement learning (RL) agent which iteratively improves a set of generated images for a user through a sequence of prompt expansions. Using human raters, we create a novel dataset of sequential preferences, which we leverage, together with large-scale open-source (non-sequential) datasets. We construct user-preference and user-choice models using an EM strategy and identify varying user preference types. We then leverage a large multimodal language model (LMM) and a value-based RL approach to suggest a personalized and diverse slate of prompt expansions to the user. Our Personalized And Sequential Text-to-image Agent (PASTA) extends T2I models with personalized multi-turn capabilities, fostering collaborative co-creation and addressing uncertainty or underspecification in a user's intent. We evaluate PASTA using human raters, showing significant improvement compared to baseline methods. We also release our sequential rater dataset and simulated user-rater interactions to support future research in personalized, multi-turn T2I generation.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Beyond Thumbs Up/Down: Untangling Challenges of Fine-Grained Feedback for Text-to-Image Generation
Jun 24, 2024Human feedback plays a critical role in learning and refining reward models for text-to-image generation, but the optimal form the feedback should take for learning an accurate reward function has not been conclusively established. This paper investigates the effectiveness of fine-grained feedback which captures nuanced distinctions in image quality and prompt-alignment, compared to traditional coarse-grained feedback (for example, thumbs up/down or ranking between a set of options). While fine-grained feedback holds promise, particularly for systems catering to diverse societal preferences, we show that demonstrating its superiority to coarse-grained feedback is not automatic. Through experiments on real and synthetic preference data, we surface the complexities of building effective models due to the interplay of model choice, feedback type, and the alignment between human judgment and computational interpretation. We identify key challenges in eliciting and utilizing fine-grained feedback, prompting a reassessment of its assumed benefits and practicality. Our findings -- e.g., that fine-grained feedback can lead to worse models for a fixed budget, in some settings; however, in controlled settings with known attributes, fine grained rewards can indeed be more helpful -- call for careful consideration of feedback attributes and potentially beckon novel modeling approaches to appropriately unlock the potential value of fine-grained feedback in-the-wild.
e-COP : Episodic Constrained Optimization of Policies
Jun 13, 2024In this paper, we present the $\texttt{e-COP}$ algorithm, the first policy optimization algorithm for constrained Reinforcement Learning (RL) in episodic (finite horizon) settings. Such formulations are applicable when there are separate sets of optimization criteria and constraints on a system's behavior. We approach this problem by first establishing a policy difference lemma for the episodic setting, which provides the theoretical foundation for the algorithm. Then, we propose to combine a set of established and novel solution ideas to yield the $\texttt{e-COP}$ algorithm that is easy to implement and numerically stable, and provide a theoretical guarantee on optimality under certain scaling assumptions. Through extensive empirical analysis using benchmarks in the Safety Gym suite, we show that our algorithm has similar or better performance than SoTA (non-episodic) algorithms adapted for the episodic setting. The scalability of the algorithm opens the door to its application in safety-constrained Reinforcement Learning from Human Feedback for Large Language or Diffusion Models.
Online Bandit Learning with Offline Preference Data
Jun 13, 2024Reinforcement Learning with Human Feedback (RLHF) is at the core of fine-tuning methods for generative AI models for language and images. Such feedback is often sought as rank or preference feedback from human raters, as opposed to eliciting scores since the latter tends to be very noisy. On the other hand, RL theory and algorithms predominantly assume that a reward feedback is available. In particular, approaches for online learning that can be helpful in adaptive data collection via active learning cannot incorporate offline preference data. In this paper, we adopt a finite-armed linear bandit model as a prototypical model of online learning. We consider an offline preference dataset to be available generated by an expert of unknown 'competence'. We propose $\texttt{warmPref-PS}$, a posterior sampling algorithm for online learning that can be warm-started with an offline dataset with noisy preference feedback. We show that by modeling the competence of the expert that generated it, we are able to use such a dataset most effectively. We support our claims with novel theoretical analysis of its Bayesian regret, as well as extensive empirical evaluation of an approximate algorithm which performs substantially better (almost 25 to 50% regret reduction in our studies) as compared to baselines.