 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Domain Knowledge to Guide Dialog Structure Induction via Neural Probabilistic Soft Logic
Mar 26, 2024



Dialog Structure Induction (DSI) is the task of inferring the latent dialog structure (i.e., a set of dialog states and their temporal transitions) of a given goal-oriented dialog. It is a critical component for modern dialog system design and discourse analysis. Existing DSI approaches are often purely data-driven, deploy models that infer latent states without access to domain knowledge, underperform when the training corpus is limited/noisy, or have difficulty when test dialogs exhibit distributional shifts from the training domain. This work explores a neural-symbolic approach as a potential solution to these problems. We introduce Neural Probabilistic Soft Logic Dialogue Structure Induction (NEUPSL DSI), a principled approach that injects symbolic knowledge into the latent space of a generative neural model. We conduct a thorough empirical investigation on the effect of NEUPSL DSI learning on hidden representation quality, few-shot learning, and out-of-domain generalization performance. Over three dialog structure induction datasets and across unsupervised and semi-supervised settings for standard and cross-domain generalization, the injection of symbolic knowledge using NEUPSL DSI provides a consistent boost in performance over the canonical baselines.
Towards Question-Answering as an Automatic Metric for Evaluating the Content Quality of a Summary
Oct 01, 2020
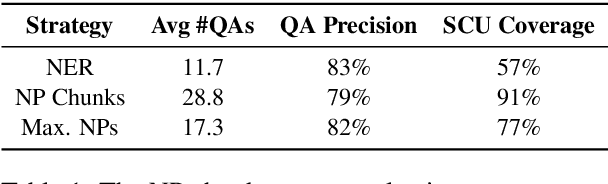
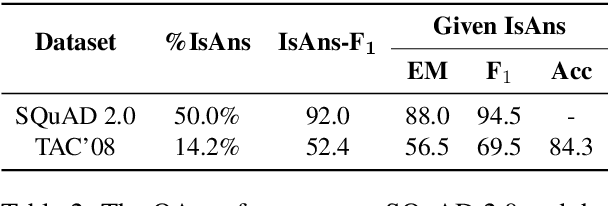
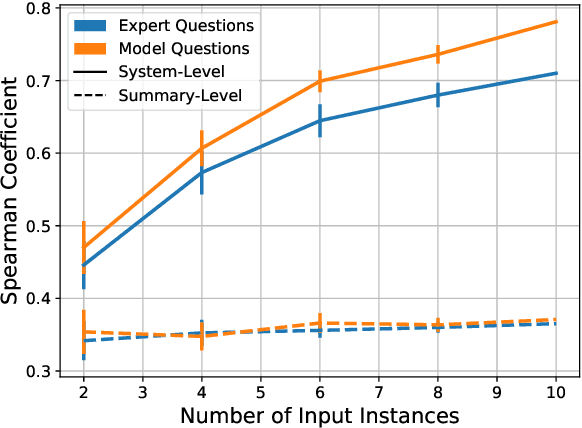
Recently, there has been growing interest in using question-answering (QA) models to evaluate the content quality of summaries. While previous work has shown initial promising results in this direction, their experimentation has been limited, leading to a poor understanding of the utility of QA in evaluating summary content. In this work, we perform an extensive evaluation of a QA-based metric for summary content quality, calculating its performance with today's state-of-the-art models as well as estimating its potential upper-bound performance. We analyze a proposed metric, QAEval, which is more widely applicable than previous work. We show that QAEval already achieves state-of-the-art performance at scoring summarization systems, beating all other metrics including the gold-standard Pyramid Method, while its performance on individual summaries is at best competitive to other automatic metrics. Through a careful analysis of each component of QAEval, we identify the performance bottlenecks and estimate that with human-level performance, QAEval's summary-level results have the potential to approach that of the Pyramid Method.
Simple and Principled Uncertainty Estimation with Deterministic Deep Learning via Distance Awareness
Jun 17, 2020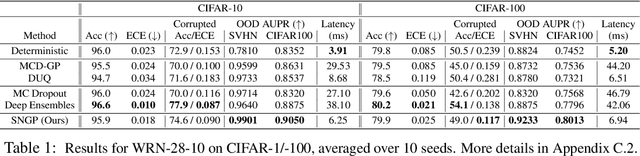
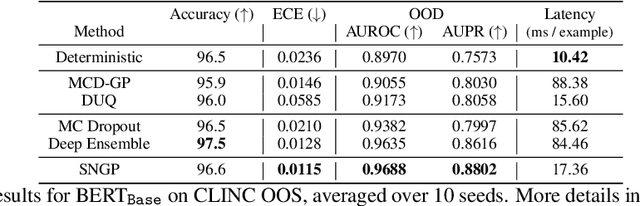
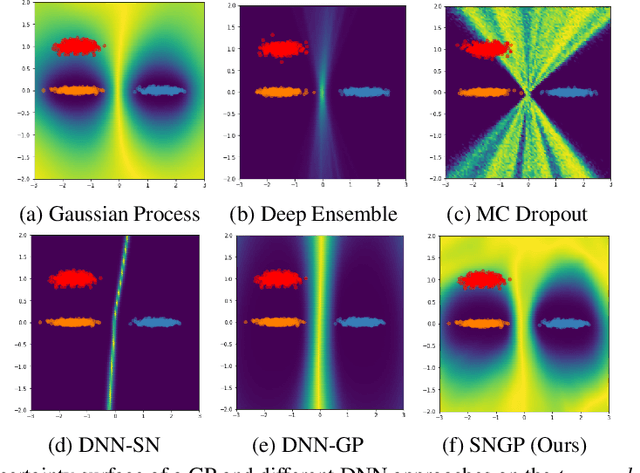
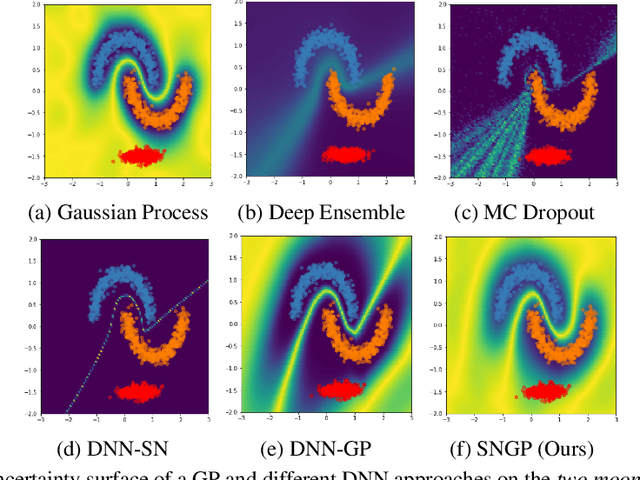
Bayesian neural networks (BNN) and deep ensembles are principled approaches to estimate the predictive uncertainty of a deep learning model. However their practicality in real-time, industrial-scale applications are limited due to their heavy memory and inference cost. This motivates us to study principled approaches to high-quality uncertainty estimation that require only a single deep neural network (DNN). By formalizing the uncertainty quantification as a minimax learning problem, we first identify input distance awareness, i.e., the model's ability to quantify the distance of a testing example from the training data in the input space, as a necessary condition for a DNN to achieve high-quality (i.e., minimax optimal) uncertainty estimation. We then propose Spectral-normalized Neural Gaussian Process (SNGP), a simple method that improves the distance-awareness ability of modern DNNs, by adding a weight normalization step during training and replacing the output layer with a Gaussian process. On a suite of vision and language understanding tasks and on modern architectures (Wide-ResNet and BERT), SNGP is competitive with deep ensembles in prediction, calibration and out-of-domain detection, and outperforms the other single-model approaches.
Guessing What's Plausible But Remembering What's True: Accurate Neural Reasoning for Question-Answering
Apr 07, 2020
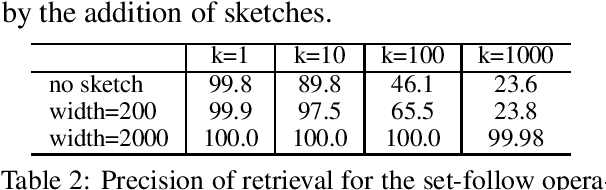

Neural approaches to natural language processing (NLP) often fail at the logical reasoning needed for deeper language understanding. In particular, neural approaches to reasoning that rely on embedded \emph{generalizations} of a knowledge base (KB) implicitly model which facts that are \emph{plausible}, but may not model which facts are \emph{true}, according to the KB. While generalizing the facts in a KB is useful for KB completion, the inability to distinguish between plausible inferences and logically entailed conclusions can be problematic in settings like as KB question answering (KBQA). We propose here a novel KB embedding scheme that supports generalization, but also allows accurate logical reasoning with a KB. Our approach introduces two new mechanisms for KB reasoning: neural retrieval over a set of embedded triples, and "memorization" of highly specific information with a compact sketch structure. Experimentally, this leads to substantial improvements over the state-of-the-art on two KBQA benchmarks.
How Large Are Lions? Inducing Distributions over Quantitative Attributes
Jun 04, 2019
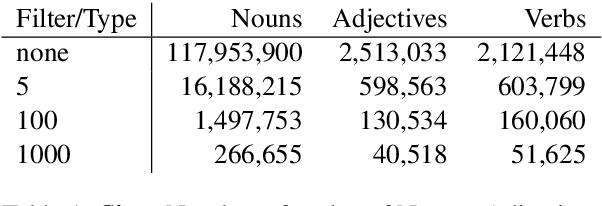
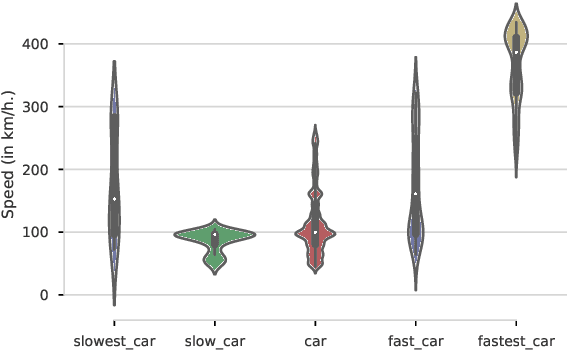

Most current NLP systems have little knowledge about quantitative attributes of objects and events. We propose an unsupervised method for collecting quantitative information from large amounts of web data, and use it to create a new, very large resource consisting of distributions over physical quantities associated with objects, adjectives, and verbs which we call Distributions over Quantitative (DoQ). This contrasts with recent work in this area which has focused on making only relative comparisons such as "Is a lion bigger than a wolf?". Our evaluation shows that DoQ compares favorably with state of the art results on existing datasets for relative comparisons of nouns and adjectives, and on a new dataset we introduce.
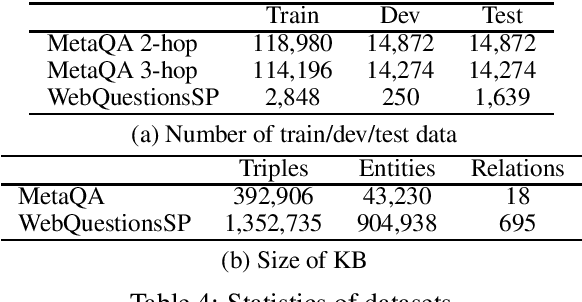
PullNet: Open Domain Question Answering with Iterative Retrieval on Knowledge Bases and Text
Apr 21, 2019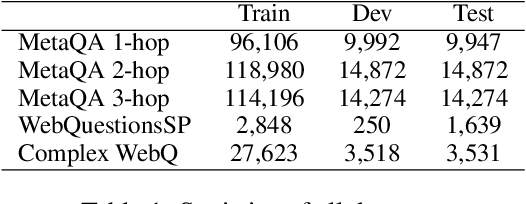
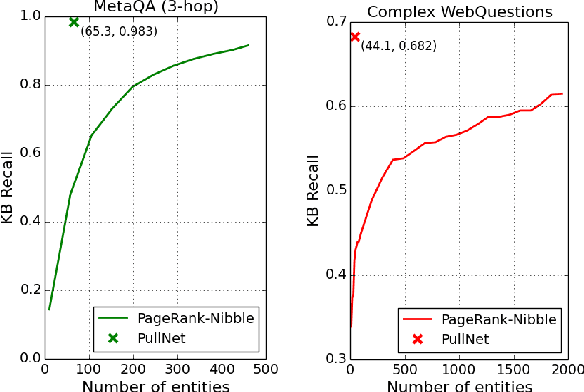
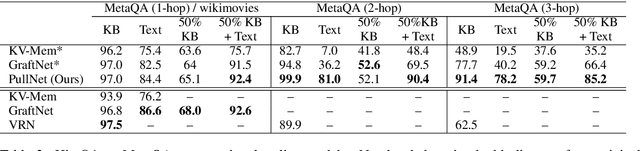
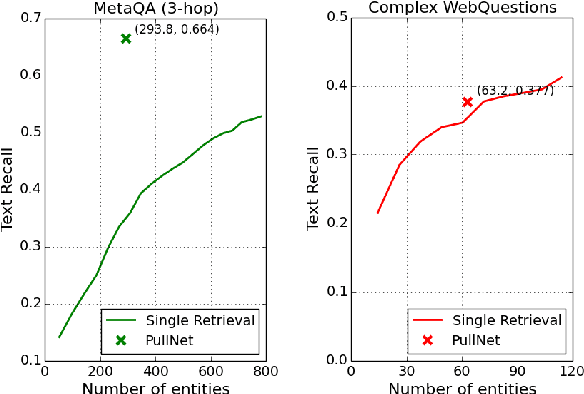
We consider open-domain queston answering (QA) where answers are drawn from either a corpus, a knowledge base (KB), or a combination of both of these. We focus on a setting in which a corpus is supplemented with a large but incomplete KB, and on questions that require non-trivial (e.g., ``multi-hop'') reasoning. We describe PullNet, an integrated framework for (1) learning what to retrieve (from the KB and/or corpus) and (2) reasoning with this heterogeneous information to find the best answer. PullNet uses an {iterative} process to construct a question-specific subgraph that contains information relevant to the question. In each iteration, a graph convolutional network (graph CNN) is used to identify subgraph nodes that should be expanded using retrieval (or ``pull'') operations on the corpus and/or KB. After the subgraph is complete, a similar graph CNN is used to extract the answer from the subgraph. This retrieve-and-reason process allows us to answer multi-hop questions using large KBs and corpora. PullNet is weakly supervised, requiring question-answer pairs but not gold inference paths. Experimentally PullNet improves over the prior state-of-the art, and in the setting where a corpus is used with incomplete KB these improvements are often dramatic. PullNet is also often superior to prior systems in a KB-only setting or a text-only setting.