 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProducing Usable Taxonomies Cheaply and Rapidly at Pinterest Using Discovered Dynamic $μ$-Topics
Jan 29, 2023
Creating a taxonomy of interests is expensive and human-effort intensive: not only do we need to identify nodes and interconnect them, in order to use the taxonomy, we must also connect the nodes to relevant entities such as users, pins, and queries. Connecting to entities is challenging because of ambiguities inherent to language but also because individual interests are dynamic and evolve. Here, we offer an alternative approach that begins with bottom-up discovery of $\mu$-topics called pincepts. The discovery process itself connects these $\mu$-topics dynamically with relevant queries, pins, and users at high precision, automatically adapting to shifting interests. Pincepts cover all areas of user interest and automatically adjust to the specificity of user interests and are thus suitable for the creation of various kinds of taxonomies. Human experts associate taxonomy nodes with $\mu$-topics (on average, 3 $\mu$-topics per node), and the $\mu$-topics offer a high-level data layer that allows quick definition, immediate inspection, and easy modification. Even more powerfully, $\mu$-topics allow easy exploration of nearby semantic space, enabling curators to spot and fill gaps. Curators' domain knowledge is heavily leveraged and we thus don't need untrained mechanical Turks, allowing further cost reduction. These $\mu$-topics thus offer a satisfactory "symbolic" stratum over which to define taxonomies. We have successfully applied this technique for very rapidly iterating on and launching the home decor and fashion styles taxonomy for style-based personalization, prominently featured at the top of Pinterest search results, at 94% precision, improving search success rate by 34.8% as well as boosting long clicks and pin saves.
Improving Query Safety at Pinterest
Jun 23, 2020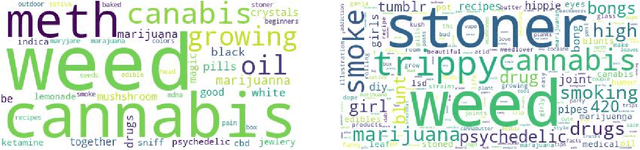


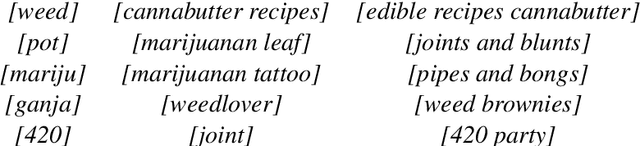
Query recommendations in search engines is a double edged sword, with undeniable benefits but potential of harm. Identifying unsafe queries is necessary to protect users from inappropriate query suggestions. However, identifying these is non-trivial because of the linguistic diversity resulting from large vocabularies, social-group-specific slang and typos, and because the inappropriateness of a term depends on the context. Here we formulate the problem as query-set expansion, where we are given a small and potentially biased seed set and the aim is to identify a diverse set of semantically related queries. We present PinSets, a system for query-set expansion, which applies a simple yet powerful mechanism to search user sessions, expanding a tiny seed set into thousands of related queries at nearly perfect precision, deep into the tail, along with explanations that are easy to interpret. PinSets owes its high quality expansion to using a hybrid of textual and behavioral techniques (i.e., treating queries both as compositional and as black boxes). Experiments show that, for the domain of drugs-related queries, PinSets expands 20 seed queries into 15,670 positive training examples at over 99\% precision. The generated expansions have diverse vocabulary and correctly handles words with ambiguous safety. PinSets decreased unsafe query suggestions at Pinterest by 90\%.
Text Classification with Few Examples using Controlled Generalization
May 18, 2020
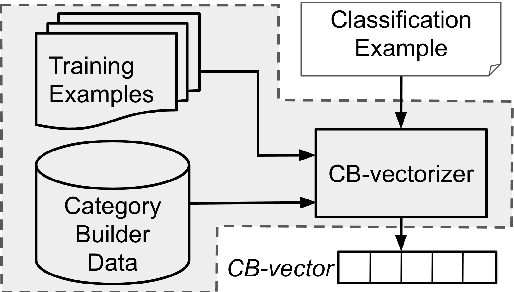

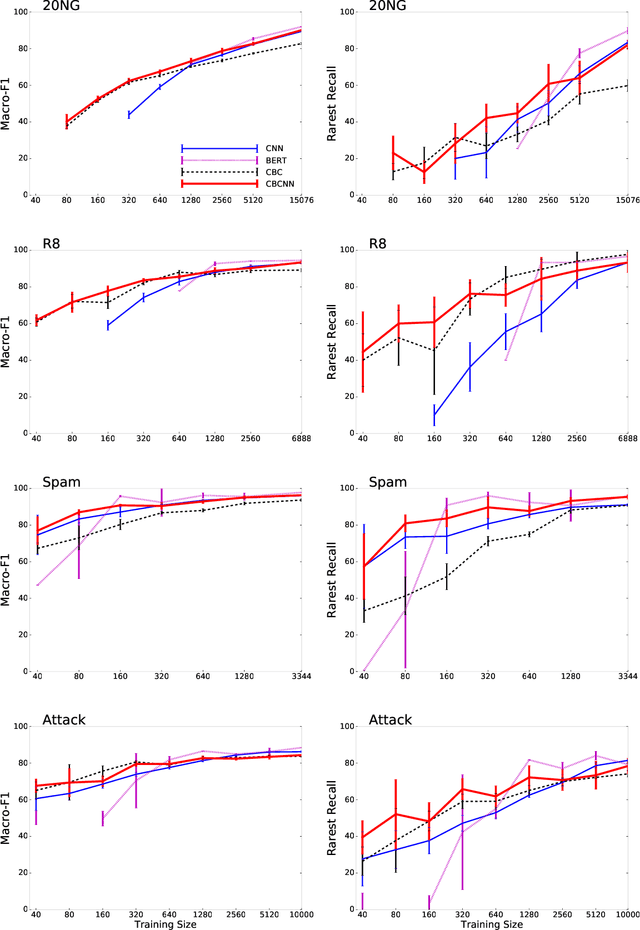
Training data for text classification is often limited in practice, especially for applications with many output classes or involving many related classification problems. This means classifiers must generalize from limited evidence, but the manner and extent of generalization is task dependent. Current practice primarily relies on pre-trained word embeddings to map words unseen in training to similar seen ones. Unfortunately, this squishes many components of meaning into highly restricted capacity. Our alternative begins with sparse pre-trained representations derived from unlabeled parsed corpora; based on the available training data, we select features that offers the relevant generalizations. This produces task-specific semantic vectors; here, we show that a feed-forward network over these vectors is especially effective in low-data scenarios, compared to existing state-of-the-art methods. By further pairing this network with a convolutional neural network, we keep this edge in low data scenarios and remain competitive when using full training sets.
How Large Are Lions? Inducing Distributions over Quantitative Attributes
Jun 04, 2019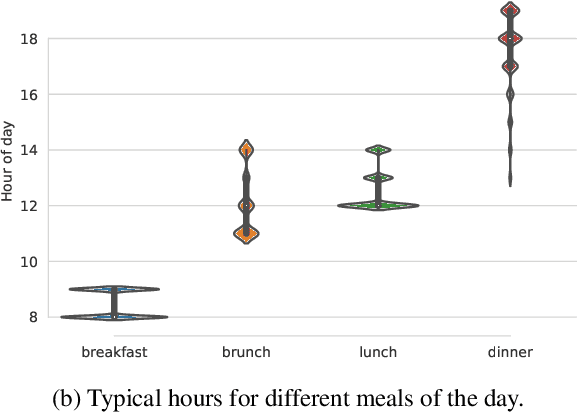
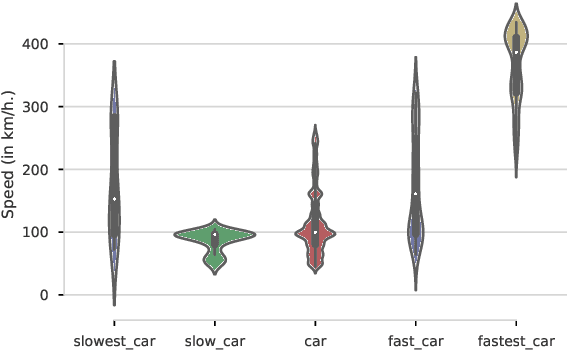

Most current NLP systems have little knowledge about quantitative attributes of objects and events. We propose an unsupervised method for collecting quantitative information from large amounts of web data, and use it to create a new, very large resource consisting of distributions over physical quantities associated with objects, adjectives, and verbs which we call Distributions over Quantitative (DoQ). This contrasts with recent work in this area which has focused on making only relative comparisons such as "Is a lion bigger than a wolf?". Our evaluation shows that DoQ compares favorably with state of the art results on existing datasets for relative comparisons of nouns and adjectives, and on a new dataset we introduce.
Robust Handling of Polysemy via Sparse Representations
May 18, 2018



Words are polysemous and multi-faceted, with many shades of meanings. We suggest that sparse distributed representations are more suitable than other, commonly used, (dense) representations to express these multiple facets, and present Category Builder, a working system that, as we show, makes use of sparse representations to support multi-faceted lexical representations. We argue that the set expansion task is well suited to study these meaning distinctions since a word may belong to multiple sets with a different reason for membership in each. We therefore exhibit the performance of Category Builder on this task, while showing that our representation captures at the same time analogy problems such as "the Ganga of Egypt" or "the Voldemort of Tolkien". Category Builder is shown to be a more expressive lexical representation and to outperform dense representations such as Word2Vec in some analogy classes despite being shown only two of the three input terms.