 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Query Safety at Pinterest
Jun 23, 2020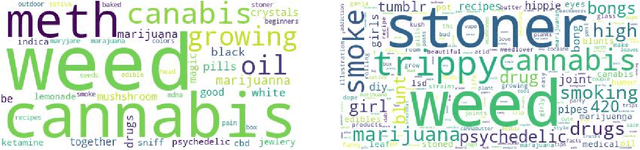


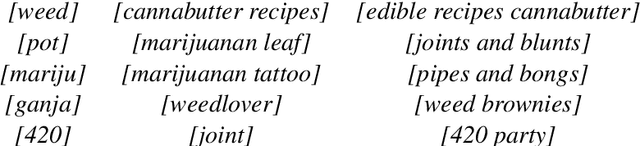
Query recommendations in search engines is a double edged sword, with undeniable benefits but potential of harm. Identifying unsafe queries is necessary to protect users from inappropriate query suggestions. However, identifying these is non-trivial because of the linguistic diversity resulting from large vocabularies, social-group-specific slang and typos, and because the inappropriateness of a term depends on the context. Here we formulate the problem as query-set expansion, where we are given a small and potentially biased seed set and the aim is to identify a diverse set of semantically related queries. We present PinSets, a system for query-set expansion, which applies a simple yet powerful mechanism to search user sessions, expanding a tiny seed set into thousands of related queries at nearly perfect precision, deep into the tail, along with explanations that are easy to interpret. PinSets owes its high quality expansion to using a hybrid of textual and behavioral techniques (i.e., treating queries both as compositional and as black boxes). Experiments show that, for the domain of drugs-related queries, PinSets expands 20 seed queries into 15,670 positive training examples at over 99\% precision. The generated expansions have diverse vocabulary and correctly handles words with ambiguous safety. PinSets decreased unsafe query suggestions at Pinterest by 90\%.
Understanding the Interaction between Interests, Conversations and Friendships in Facebook
Oct 31, 2012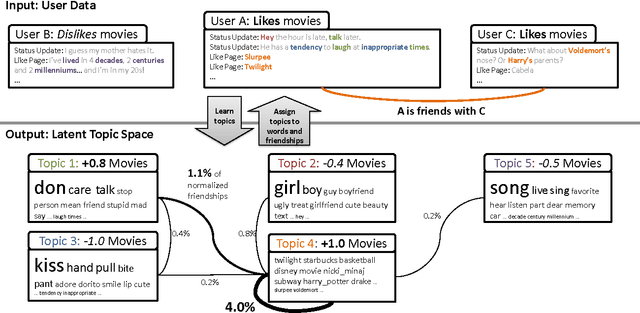
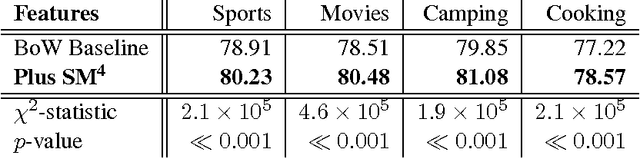

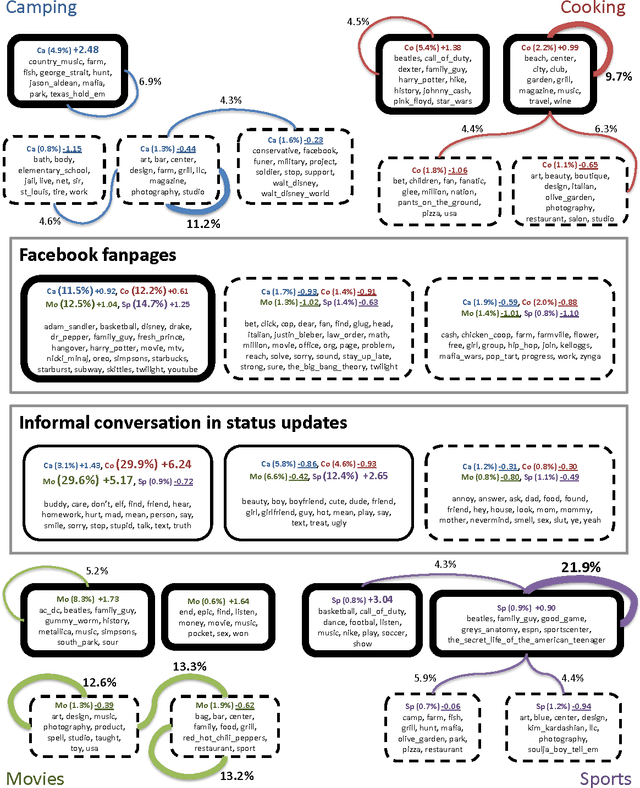
In this paper, we explore salient questions about user interests, conversations and friendships in the Facebook social network, using a novel latent space model that integrates several data types. A key challenge of studying Facebook's data is the wide range of data modalities such as text, network links, and categorical labels. Our latent space model seamlessly combines all three data modalities over millions of users, allowing us to study the interplay between user friendships, interests, and higher-order network-wide social trends on Facebook. The recovered insights not only answer our initial questions, but also reveal surprising facts about user interests in the context of Facebook's ecosystem. We also confirm that our results are significant with respect to evidential information from the study subjects.
Shift-Invariance Sparse Coding for Audio Classification
Jun 20, 2012
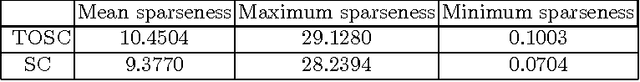


Sparse coding is an unsupervised learning algorithm that learns a succinct high-level representation of the inputs given only unlabeled data; it represents each input as a sparse linear combination of a set of basis functions. Originally applied to modeling the human visual cortex, sparse coding has also been shown to be useful for self-taught learning, in which the goal is to solve a supervised classification task given access to additional unlabeled data drawn from different classes than that in the supervised learning problem. Shift-invariant sparse coding (SISC) is an extension of sparse coding which reconstructs a (usually time-series) input using all of the basis functions in all possible shifts. In this paper, we present an efficient algorithm for learning SISC bases. Our method is based on iteratively solving two large convex optimization problems: The first, which computes the linear coefficients, is an L1-regularized linear least squares problem with potentially hundreds of thousands of variables. Existing methods typically use a heuristic to select a small subset of the variables to optimize, but we present a way to efficiently compute the exact solution. The second, which solves for bases, is a constrained linear least squares problem. By optimizing over complex-valued variables in the Fourier domain, we reduce the coupling between the different variables, allowing the problem to be solved efficiently. We show that SISC's learned high-level representations of speech and music provide useful features for classification tasks within those domains. When applied to classification, under certain conditions the learned features outperform state of the art spectral and cepstral features.